 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Learning for Efficient VVC Bitrate Ladder Prediction
Jul 23, 2022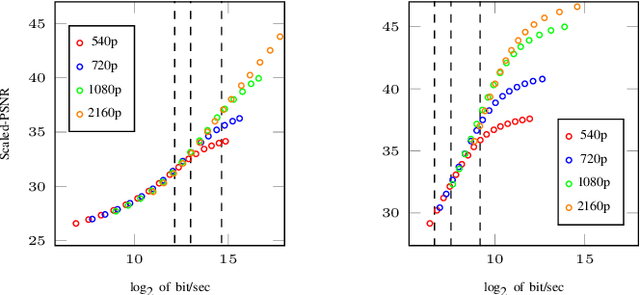
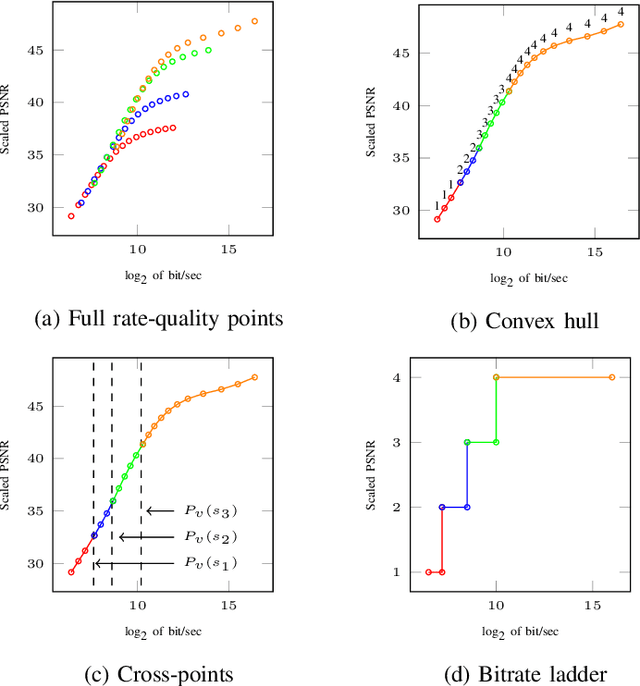
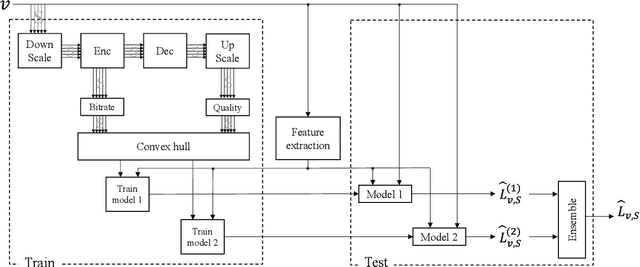
Changing the encoding parameters, in particular the video resolution, is a common practice before transcoding. To this end, streaming and broadcast platforms benefit from so-called bitrate ladders to determine the optimal resolution for given bitrates. However, the task of determining the bitrate ladder can usually be challenging as, on one hand, so-called fit-for-all static ladders would waste bandwidth, and on the other hand, fully specialized ladders are often not affordable in terms of computational complexity. In this paper, we propose an ML-based scheme for predicting the bitrate ladder based on the content of the video. The baseline of our solution predicts the bitrate ladder using two constituent methods, which require no encoding passes. To further enhance the performance of the constituent methods, we integrate a conditional ensemble method to aggregate their decisions, with a negligibly limited number of encoding passes. The experiment, carried out on the optimized software encoder implementation of the VVC standard, called VVenC, shows significant performance improvement. When compared to static bitrate ladder, the proposed method can offer about 13% bitrate reduction in terms of BD-BR with a negligible additional computational overhead. Conversely, when compared to the fully specialized bitrate ladder method, the proposed method can offer about 86% to 92% complexity reduction, at cost the of only 0.8% to 0.9% coding efficiency drop in terms of BD-BR.
CAESR: Conditional Autoencoder and Super-Resolution for Learned Spatial Scalability
Feb 01, 2022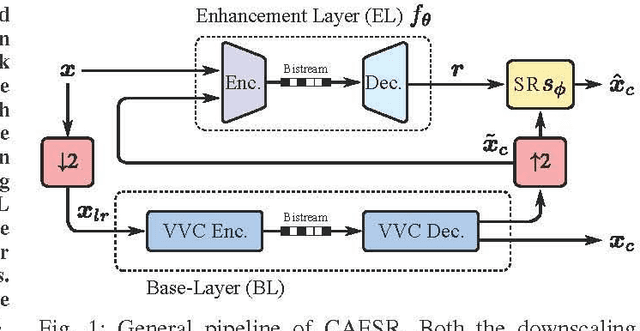
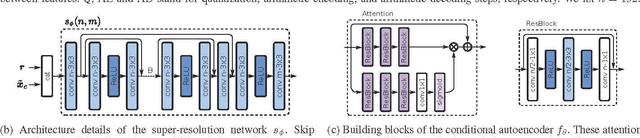
In this paper, we present CAESR, an hybrid learning-based coding approach for spatial scalability based on the versatile video coding (VVC) standard. Our framework considers a low-resolution signal encoded with VVC intra-mode as a base-layer (BL), and a deep conditional autoencoder with hyperprior (AE-HP) as an enhancement-layer (EL) model. The EL encoder takes as inputs both the upscaled BL reconstruction and the original image. Our approach relies on conditional coding that learns the optimal mixture of the source and the upscaled BL image, enabling better performance than residual coding. On the decoder side, a super-resolution (SR) module is used to recover high-resolution details and invert the conditional coding process. Experimental results have shown that our solution is competitive with the VVC full-resolution intra coding while being scalable.