 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Learning for Efficient VVC Bitrate Ladder Prediction
Jul 23, 2022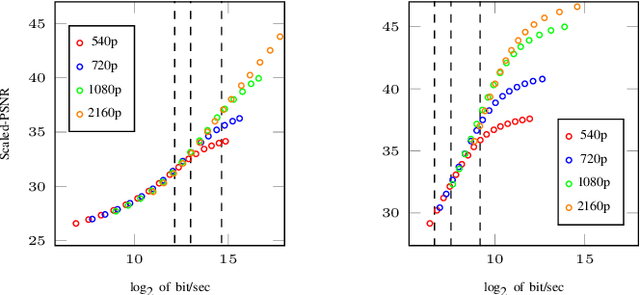
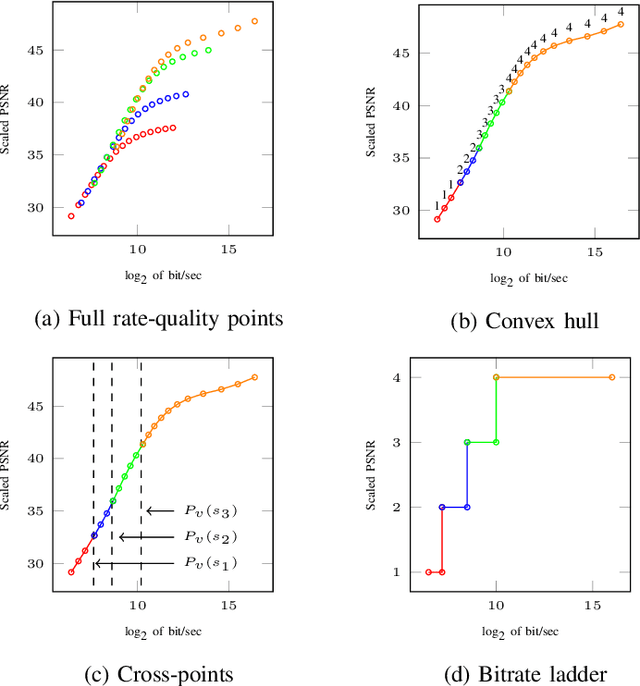
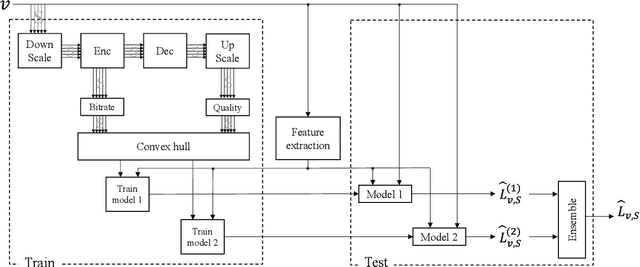
Changing the encoding parameters, in particular the video resolution, is a common practice before transcoding. To this end, streaming and broadcast platforms benefit from so-called bitrate ladders to determine the optimal resolution for given bitrates. However, the task of determining the bitrate ladder can usually be challenging as, on one hand, so-called fit-for-all static ladders would waste bandwidth, and on the other hand, fully specialized ladders are often not affordable in terms of computational complexity. In this paper, we propose an ML-based scheme for predicting the bitrate ladder based on the content of the video. The baseline of our solution predicts the bitrate ladder using two constituent methods, which require no encoding passes. To further enhance the performance of the constituent methods, we integrate a conditional ensemble method to aggregate their decisions, with a negligibly limited number of encoding passes. The experiment, carried out on the optimized software encoder implementation of the VVC standard, called VVenC, shows significant performance improvement. When compared to static bitrate ladder, the proposed method can offer about 13% bitrate reduction in terms of BD-BR with a negligible additional computational overhead. Conversely, when compared to the fully specialized bitrate ladder method, the proposed method can offer about 86% to 92% complexity reduction, at cost the of only 0.8% to 0.9% coding efficiency drop in terms of BD-BR.
Prediction-Aware Quality Enhancement of VVC Using CNN
Dec 08, 2021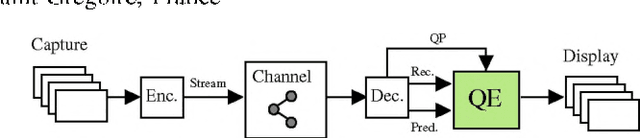


The upcoming video coding standard, Versatile Video Coding (VVC), has shown great improvement compared to its predecessor, High Efficiency Video Coding (HEVC), in terms of bitrate saving. Despite its substantial performance, compressed videos might still suffer from quality degradation at low bitrates due to coding artifacts such as blockiness, blurriness and ringing. In this work, we exploit Convolutional Neural Networks (CNN) to enhance quality of VVC coded frames after decoding in order to reduce low bitrate artifacts. The main contribution of this work is the use of coding information from the compressed bitstream. More precisely, the prediction information of intra frames is used for training the network in addition to the reconstruction information. The proposed method is applied on both luminance and chrominance components of intra coded frames of VVC. Experiments on VVC Test Model (VTM) show that, both in low and high bitrates, the use of coding information can improve the BD-rate performance by about 1% and 6% for luma and chroma components, respectively.
A CNN-based Prediction-Aware Quality Enhancement Framework for VVC
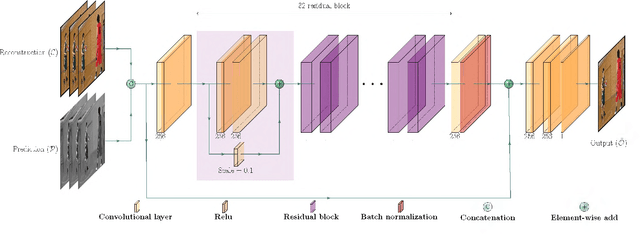
May 12, 2021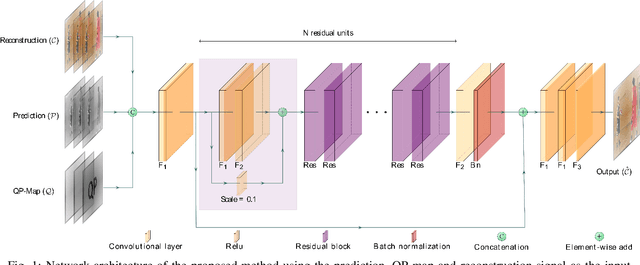
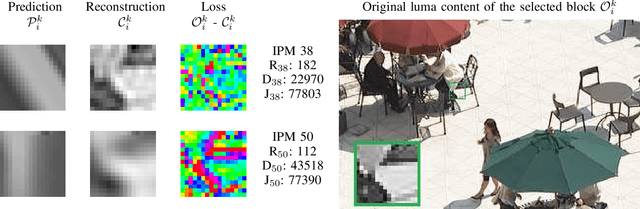
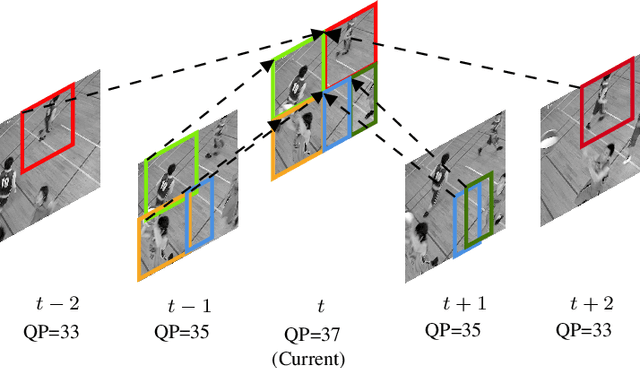
This paper presents a framework for Convolutional Neural Network (CNN)-based quality enhancement task, by taking advantage of coding information in the compressed video signal. The motivation is that normative decisions made by the encoder can significantly impact the type and strength of artifacts in the decoded images. In this paper, the main focus has been put on decisions defining the prediction signal in intra and inter frames. This information has been used in the training phase as well as input to help the process of learning artifacts that are specific to each coding type. Furthermore, to retain a low memory requirement for the proposed method, one model is used for all Quantization Parameters (QPs) with a QP-map, which is also shared between luma and chroma components. In addition to the Post Processing (PP) approach, the In-Loop Filtering (ILF) codec integration has also been considered, where the characteristics of the Group of Pictures (GoP) are taken into account to boost the performance. The proposed CNN-based Quality Enhancement(QE) framework has been implemented on top of the VVC Test Model (VTM-10). Experiments show that the prediction-aware aspect of the proposed method improves the coding efficiency gain of the default CNN-based QE method by 1.52%, in terms of BD-BR, at the same network complexity compared to the default CNN-based QE filter.
Model Selection CNN-based VVC QualityEnhancement
May 07, 2021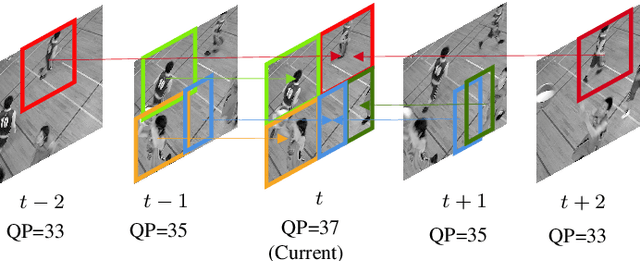
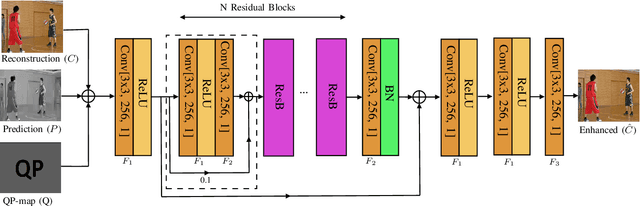

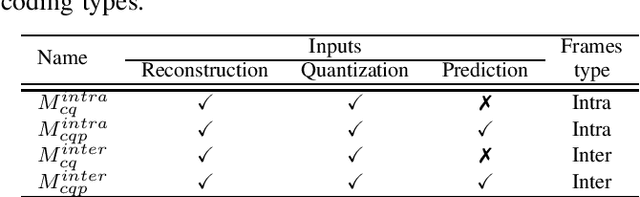
Artifact removal and filtering methods are inevitable parts of video coding. On one hand, new codecs and compression standards come with advanced in-loop filters and on the other hand, displays are equipped with high capacity processing units for post-treatment of decoded videos. This paper proposes a Convolutional Neural Network (CNN)-based post-processing algorithm for intra and inter frames of Versatile Video Coding (VVC) coded streams. Depending on the frame type, this method benefits from normative prediction signal by feeding it as an additional input along with reconstructed signal and a Quantization Parameter (QP)-map to the CNN. Moreover, an optional Model Selection (MS) strategy is adopted to pick the best trained model among available ones at the encoder side and signal it to the decoder side. This MS strategy is applicable at both frame level and block level. The experiments under the Random Access (RA) configuration of the VVC Test Model (VTM-10.0) show that the proposed prediction-aware algorithm can bring an additional BD-BR gain of -1.3% compared to the method without the prediction information. Furthermore, the proposed MS scheme brings -0.5% more BD-BR gain on top of the prediction-aware method.