 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVG-VPC: Voxelized Point Cloud Dataset for Visual Volumetric Video-based Coding
Apr 08, 2025Point cloud compression has become a crucial factor in immersive visual media processing and streaming. This paper presents a new open dataset called UVG-VPC for the development, evaluation, and validation of MPEG Visual Volumetric Video-based Coding (V3C) technology. The dataset is distributed under its own non-commercial license. It consists of 12 point cloud test video sequences of diverse characteristics with respect to the motion, RGB texture, 3D geometry, and surface occlusion of the points. Each sequence is 10 seconds long and comprises 250 frames captured at 25 frames per second. The sequences are voxelized with a geometry precision of 9 to 12 bits, and the voxel color attributes are represented as 8-bit RGB values. The dataset also includes associated normals that make it more suitable for evaluating point cloud compression solutions. The main objective of releasing the UVG-VPC dataset is to foster the development of V3C technologies and thereby shape the future in this field.
* Point cloud compression;Geometry;Visualization;Three-dimensional displays;Video sequences;Transform coding;Media;Open dataset;point cloud;Visual Volumetric Video-based Coding (V3C);Video-based Point Cloud Compression (V-PCC);Extended Reality (XR)
Machine Learning based Efficient QT-MTT Partitioning Scheme for VVC Intra Encoders
Mar 10, 2021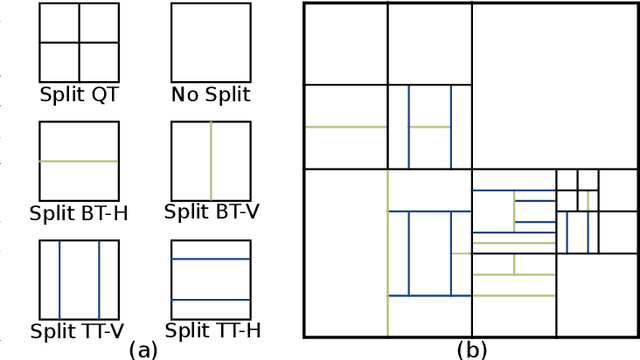
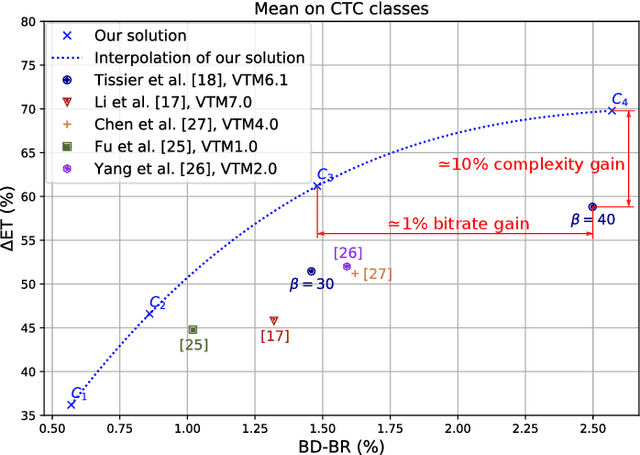
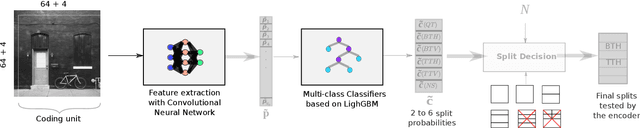
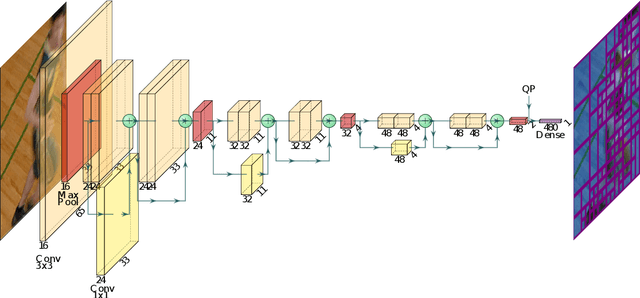
The next-generation Versatile Video Coding (VVC) standard introduces a new Multi-Type Tree (MTT) block partitioning structure that supports Binary-Tree (BT) and Ternary-Tree (TT) splits in both vertical and horizontal directions. This new approach leads to five possible splits at each block depth and thereby improves the coding efficiency of VVC over that of the preceding High Efficiency Video Coding (HEVC) standard, which only supports Quad-Tree (QT) partitioning with a single split per block depth. However, MTT also has brought a considerable impact on encoder computational complexity. In this paper, a two-stage learning-based technique is proposed to tackle the complexity overhead of MTT in VVC intra encoders. In our scheme, the input block is first processed by a Convolutional Neural Network (CNN) to predict its spatial features through a vector of probabilities describing the partition at each 4x4 edge. Subsequently, a Decision Tree (DT) model leverages this vector of spatial features to predict the most likely splits at each block. Finally, based on this prediction, only the N most likely splits are processed by the Rate-Distortion (RD) process of the encoder. In order to train our CNN and DT models on a wide range of image contents, we also propose a public VVC frame partitioning dataset based on existing image dataset encoded with the VVC reference software encoder. Our proposal relying on the top-3 configuration reaches 46.6% complexity reduction for a negligible bitrate increase of 0.86%. A top-2 configuration enables a higher complexity reduction of 69.8% for 2.57% bitrate loss. These results emphasis a better trade-off between VTM intra coding efficiency and complexity reduction compared to the state-of-the-art solutions.