 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Object Detection Models for TinyML: Foundations, Comparative Analysis, Challenges, and Emerging Solutions
Aug 11, 2025



Object detection (OD) has become vital for numerous computer vision applications, but deploying it on resource-constrained IoT devices presents a significant challenge. These devices, often powered by energy-efficient microcontrollers, struggle to handle the computational load of deep learning-based OD models. This issue is compounded by the rapid proliferation of IoT devices, predicted to surpass 150 billion by 2030. TinyML offers a compelling solution by enabling OD on ultra-low-power devices, paving the way for efficient and real-time processing at the edge. Although numerous survey papers have been published on this topic, they often overlook the optimization challenges associated with deploying OD models in TinyML environments. To address this gap, this survey paper provides a detailed analysis of key optimization techniques for deploying OD models on resource-constrained devices. These techniques include quantization, pruning, knowledge distillation, and neural architecture search. Furthermore, we explore both theoretical approaches and practical implementations, bridging the gap between academic research and real-world edge artificial intelligence deployment. Finally, we compare the key performance indicators (KPIs) of existing OD implementations on microcontroller devices, highlighting the achieved maturity level of these solutions in terms of both prediction accuracy and efficiency. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/christophezei/Optimizing-Object-Detection-Models-for-TinyML-A-Comprehensive-Survey.
Can LLMs Revolutionize the Design of Explainable and Efficient TinyML Models?
Apr 13, 2025



This paper introduces a novel framework for designing efficient neural network architectures specifically tailored to tiny machine learning (TinyML) platforms. By leveraging large language models (LLMs) for neural architecture search (NAS), a vision transformer (ViT)-based knowledge distillation (KD) strategy, and an explainability module, the approach strikes an optimal balance between accuracy, computational efficiency, and memory usage. The LLM-guided search explores a hierarchical search space, refining candidate architectures through Pareto optimization based on accuracy, multiply-accumulate operations (MACs), and memory metrics. The best-performing architectures are further fine-tuned using logits-based KD with a pre-trained ViT-B/16 model, which enhances generalization without increasing model size. Evaluated on the CIFAR-100 dataset and deployed on an STM32H7 microcontroller (MCU), the three proposed models, LMaNet-Elite, LMaNet-Core, and QwNet-Core, achieve accuracy scores of 74.50%, 74.20% and 73.00%, respectively. All three models surpass current state-of-the-art (SOTA) models, such as MCUNet-in3/in4 (69.62% / 72.86%) and XiNet (72.27%), while maintaining a low computational cost of less than 100 million MACs and adhering to the stringent 320 KB static random-access memory (SRAM) constraint. These results demonstrate the efficiency and performance of the proposed framework for TinyML platforms, underscoring the potential of combining LLM-driven search, Pareto optimization, KD, and explainability to develop accurate, efficient, and interpretable models. This approach opens new possibilities in NAS, enabling the design of efficient architectures specifically suited for TinyML.
Quality-driven Variable Frame-Rate for Green Video Coding in Broadcast Applications
Dec 29, 2020

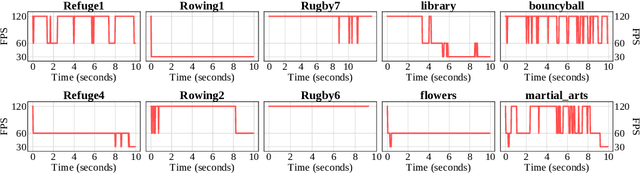
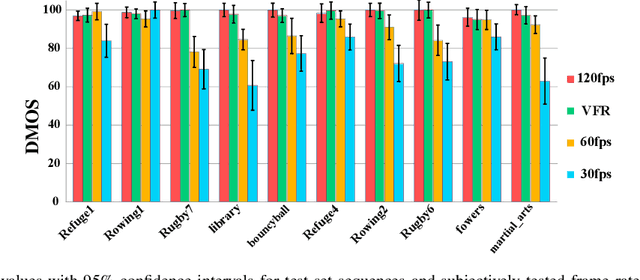
The Digital Video Broadcasting (DVB) has proposed to introduce the Ultra-High Definition services in three phases: UHD-1 phase 1, UHD-1 phase 2 and UHD-2. The UHD-1 phase 2 specification includes several new features such as High Dynamic Range (HDR) and High Frame-Rate (HFR). It has been shown in several studies that HFR (+100 fps) enhances the perceptual quality and that this quality enhancement is content-dependent. On the other hand, HFR brings several challenges to the transmission chain including codec complexity increase and bit-rate overhead, which may delay or even prevent its deployment in the broadcast echo-system. In this paper, we propose a Variable Frame Rate (VFR) solution to determine the minimum (critical) frame-rate that preserves the perceived video quality of HFR video. The frame-rate determination is modeled as a 3-class classification problem which consists in dynamically and locally selecting one frame-rate among three: 30, 60 and 120 frames per second. Two random forests classifiers are trained with a ground truth carefully built by experts for this purpose. The subjective results conducted on ten HFR video contents, not included in the training set, clearly show the efficiency of the proposed solution enabling to locally determine the lowest possible frame-rate while preserving the quality of the HFR content. Moreover, our VFR solution enables significant bit-rate savings and complexity reductions at both encoder and decoder sides.