 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principled Hierarchical Deep Learning Approach to Joint Image Compression and Classification
Oct 30, 2023



Among applications of deep learning (DL) involving low cost sensors, remote image classification involves a physical channel that separates edge sensors and cloud classifiers. Traditional DL models must be divided between an encoder for the sensor and the decoder + classifier at the edge server. An important challenge is to effectively train such distributed models when the connecting channels have limited rate/capacity. Our goal is to optimize DL models such that the encoder latent requires low channel bandwidth while still delivers feature information for high classification accuracy. This work proposes a three-step joint learning strategy to guide encoders to extract features that are compact, discriminative, and amenable to common augmentations/transformations. We optimize latent dimension through an initial screening phase before end-to-end (E2E) training. To obtain an adjustable bit rate via a single pre-deployed encoder, we apply entropy-based quantization and/or manual truncation on the latent representations. Tests show that our proposed method achieves accuracy improvement of up to 1.5% on CIFAR-10 and 3% on CIFAR-100 over conventional E2E cross-entropy training.
End-to-End Optimization of JPEG-Based Deep Learning Process for Image Classification
Aug 10, 2023Among major deep learning (DL) applications, distributed learning involving image classification require effective image compression codecs deployed on low-cost sensing devices for efficient transmission and storage. Traditional codecs such as JPEG designed for perceptual quality are not configured for DL tasks. This work introduces an integrative end-to-end trainable model for image compression and classification consisting of a JPEG image codec and a DL-based classifier. We demonstrate how this model can optimize the widely deployed JPEG codec settings to improve classification accuracy in consideration of bandwidth constraint. Our tests on CIFAR-100 and ImageNet also demonstrate improved validation accuracy over preset JPEG configuration.
End-to-end optimized image compression for multiple machine tasks
Mar 06, 2021
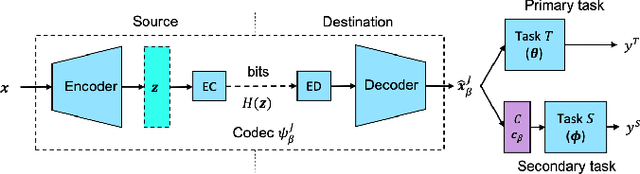
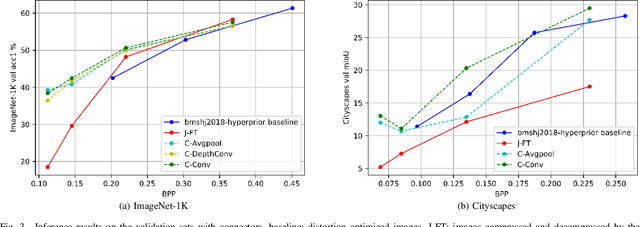

An increasing share of captured images and videos are transmitted for storage and remote analysis by computer vision algorithms, rather than to be viewed by humans. Contrary to traditional standard codecs with engineered tools, neural network based codecs can be trained end-to-end to optimally compress images with respect to a target rate and any given differentiable performance metric. Although it is possible to train such compression tools to achieve better rate-accuracy performance for a particular computer vision task, it could be practical and relevant to re-use the compressed bit-stream for multiple machine tasks. For this purpose, we introduce 'Connectors' that are inserted between the decoder and the task algorithms to enable a direct transformation of the compressed content, which was previously optimized for a specific task, to multiple other machine tasks. We demonstrate the effectiveness of the proposed method by achieving significant rate-accuracy performance improvement for both image classification and object segmentation, using the same bit-stream, originally optimized for object detection.
End-to-end optimized image compression for machines, a study
Nov 10, 2020

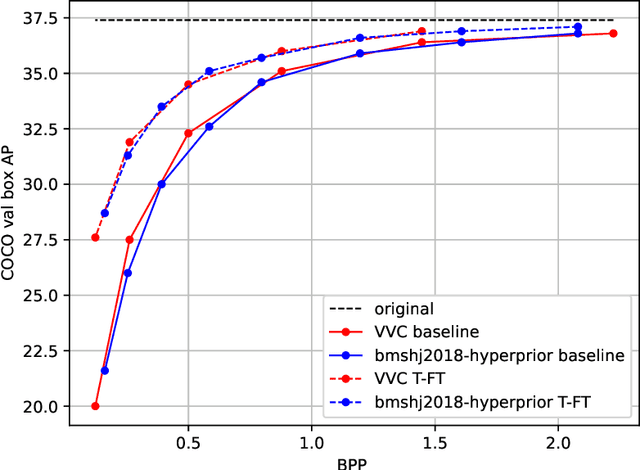
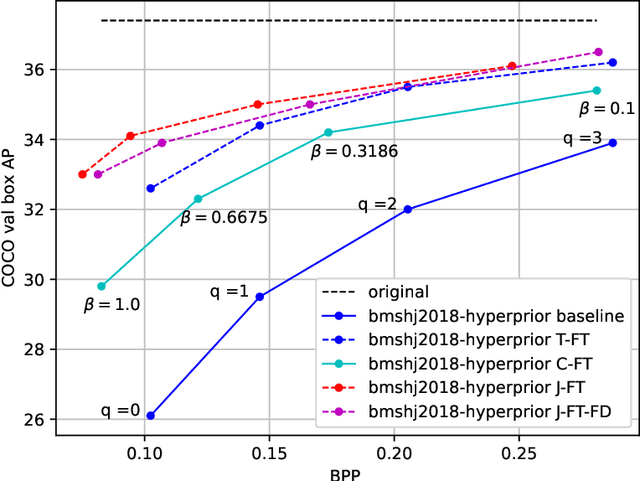
An increasing share of image and video content is analyzed by machines rather than viewed by humans, and therefore it becomes relevant to optimize codecs for such applications where the analysis is performed remotely. Unfortunately, conventional coding tools are challenging to specialize for machine tasks as they were originally designed for human perception. However, neural network based codecs can be jointly trained end-to-end with any convolutional neural network (CNN)-based task model. In this paper, we propose to study an end-to-end framework enabling efficient image compression for remote machine task analysis, using a chain composed of a compression module and a task algorithm that can be optimized end-to-end. We show that it is possible to significantly improve the task accuracy when fine-tuning jointly the codec and the task networks, especially at low bit-rates. Depending on training or deployment constraints, selective fine-tuning can be applied only on the encoder, decoder or task network and still achieve rate-accuracy improvements over an off-the-shelf codec and task network. Our results also demonstrate the flexibility of end-to-end pipelines for practical applications.
Faster and Accurate Classification for JPEG2000 Compressed Images in Networked Applications
Sep 04, 2019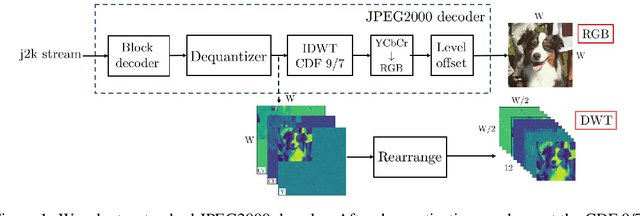

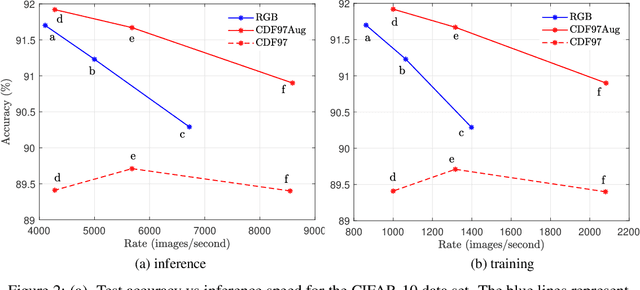
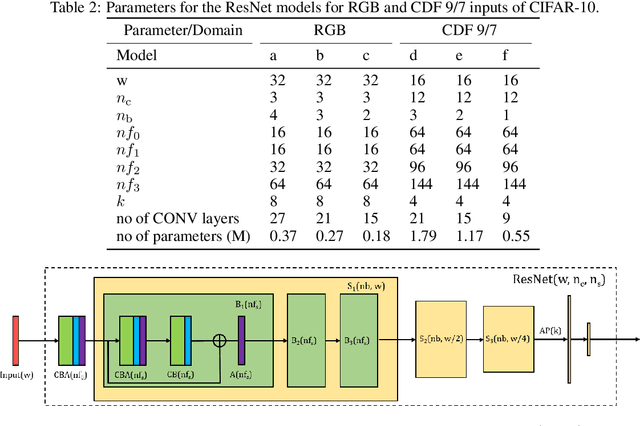
JPEG2000 (j2k) is a highly popular format for image and video compression.With the rapidly growing applications of cloud based image classification, most existing j2k-compatible schemes would stream compressed color images from the source before reconstruction at the processing center as inputs to deep CNNs. We propose to remove the computationally costly reconstruction step by training a deep CNN image classifier using the CDF 9/7 Discrete Wavelet Transformed (DWT) coefficients directly extracted from j2k-compressed images. We demonstrate additional computation savings by utilizing shallower CNN to achieve classification of good accuracy in the DWT domain. Furthermore, we show that traditional augmentation transforms such as flipping/shifting are ineffective in the DWT domain and present different augmentation transformations to achieve more accurate classification without any additional cost. This way, faster and more accurate classification is possible for j2k encoded images without image reconstruction. Through experiments on CIFAR-10 and Tiny ImageNet data sets, we show that the performance of the proposed solution is consistent for image transmission over limited channel bandwidth.