 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving The Reconstruction Quality by Overfitted Decoder Bias in Neural Image Compression
Oct 10, 2022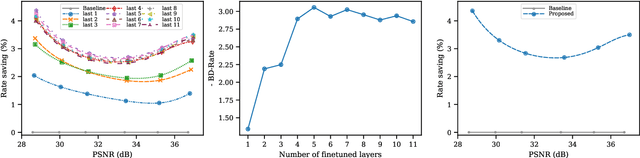


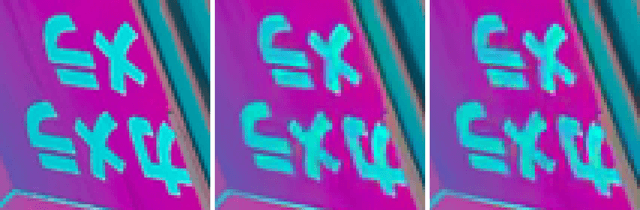
End-to-end trainable models have reached the performance of traditional handcrafted compression techniques on videos and images. Since the parameters of these models are learned over large training sets, they are not optimal for any given image to be compressed. In this paper, we propose an instance-based fine-tuning of a subset of decoder's bias to improve the reconstruction quality in exchange for extra encoding time and minor additional signaling cost. The proposed method is applicable to any end-to-end compression methods, improving the state-of-the-art neural image compression BD-rate by $3-5\%$.
The Graph Neural Networking Challenge: A Worldwide Competition for Education in AI/ML for Networks
Jul 26, 2021
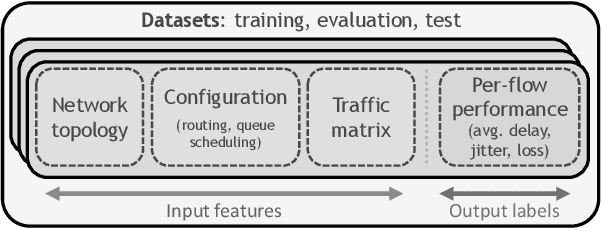

During the last decade, Machine Learning (ML) has increasingly become a hot topic in the field of Computer Networks and is expected to be gradually adopted for a plethora of control, monitoring and management tasks in real-world deployments. This poses the need to count on new generations of students, researchers and practitioners with a solid background in ML applied to networks. During 2020, the International Telecommunication Union (ITU) has organized the "ITU AI/ML in 5G challenge'', an open global competition that has introduced to a broad audience some of the current main challenges in ML for networks. This large-scale initiative has gathered 23 different challenges proposed by network operators, equipment manufacturers and academia, and has attracted a total of 1300+ participants from 60+ countries. This paper narrates our experience organizing one of the proposed challenges: the "Graph Neural Networking Challenge 2020''. We describe the problem presented to participants, the tools and resources provided, some organization aspects and participation statistics, an outline of the top-3 awarded solutions, and a summary with some lessons learned during all this journey. As a result, this challenge leaves a curated set of educational resources openly available to anyone interested in the topic.
On the hidden treasure of dialog in video question answering
Mar 26, 2021
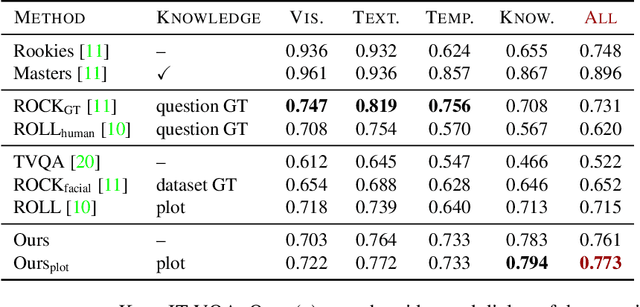
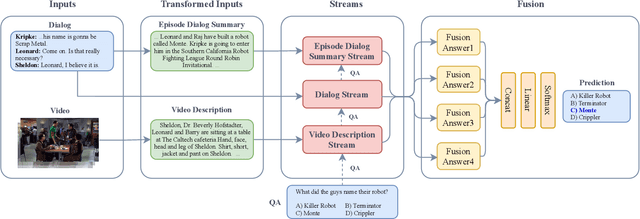

High-level understanding of stories in video such as movies and TV shows from raw data is extremely challenging. Modern video question answering (VideoQA) systems often use additional human-made sources like plot synopses, scripts, video descriptions or knowledge bases. In this work, we present a new approach to understand the whole story without such external sources. The secret lies in the dialog: unlike any prior work, we treat dialog as a noisy source to be converted into text description via dialog summarization, much like recent methods treat video. The input of each modality is encoded by transformers independently, and a simple fusion method combines all modalities, using soft temporal attention for localization over long inputs. Our model outperforms the state of the art on the KnowIT VQA dataset by a large margin, without using question-specific human annotation or human-made plot summaries. It even outperforms human evaluators who have never watched any whole episode before.
Off-policy evaluation for MDPs with unknown structure
Feb 11, 2015



Off-policy learning in dynamic decision problems is essential for providing strong evidence that a new policy is better than the one in use. But how can we prove superiority without testing the new policy? To answer this question, we introduce the G-SCOPE algorithm that evaluates a new policy based on data generated by the existing policy. Our algorithm is both computationally and sample efficient because it greedily learns to exploit factored structure in the dynamics of the environment. We present a finite sample analysis of our approach and show through experiments that the algorithm scales well on high-dimensional problems with few samples.