 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Positional Encoding for Implicit Neural Representation based Compact Data Representation
Nov 10, 2023Positional encodings are employed to capture the high frequency information of the encoded signals in implicit neural representation (INR). In this paper, we propose a novel positional encoding method which improves the reconstruction quality of the INR. The proposed embedding method is more advantageous for the compact data representation because it has a greater number of frequency basis than the existing methods. Our experiments shows that the proposed method achieves significant gain in the rate-distortion performance without introducing any additional complexity in the compression task and higher reconstruction quality in novel view synthesis.
Improving The Reconstruction Quality by Overfitted Decoder Bias in Neural Image Compression
Oct 10, 2022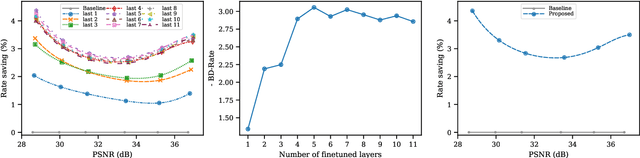


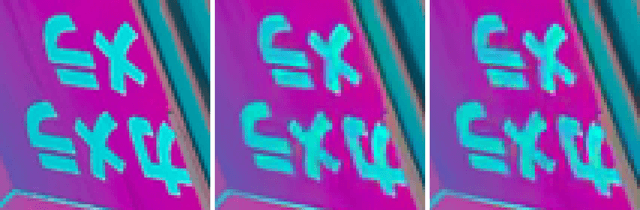
End-to-end trainable models have reached the performance of traditional handcrafted compression techniques on videos and images. Since the parameters of these models are learned over large training sets, they are not optimal for any given image to be compressed. In this paper, we propose an instance-based fine-tuning of a subset of decoder's bias to improve the reconstruction quality in exchange for extra encoding time and minor additional signaling cost. The proposed method is applicable to any end-to-end compression methods, improving the state-of-the-art neural image compression BD-rate by $3-5\%$.
ParaDiS: Parallelly Distributable Slimmable Neural Networks
Oct 06, 2021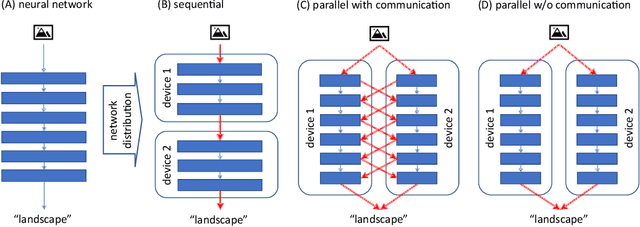

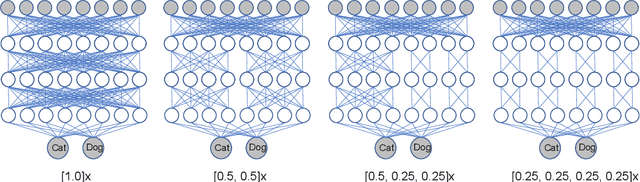

When several limited power devices are available, one of the most efficient ways to make profit of these resources, while reducing the processing latency and communication load, is to run in parallel several neural sub-networks and to fuse the result at the end of processing. However, such a combination of sub-networks must be trained specifically for each particular configuration of devices (characterized by number of devices and their capacities) which may vary over different model deployments and even within the same deployment. In this work we introduce parallelly distributable slimmable (ParaDiS) neural networks that are splittable in parallel among various device configurations without retraining. While inspired by slimmable networks allowing instant adaptation to resources on just one device, ParaDiS networks consist of several multi-device distributable configurations or switches that strongly share the parameters between them. We evaluate ParaDiS framework on MobileNet v1 and ResNet-50 architectures on ImageNet classification task. We show that ParaDiS switches achieve similar or better accuracy than the individual models, i.e., distributed models of the same structure trained individually. Moreover, we show that, as compared to universally slimmable networks that are not distributable, the accuracy of distributable ParaDiS switches either does not drop at all or drops by a maximum of 1 % only in the worst cases.