 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaDiS: Parallelly Distributable Slimmable Neural Networks
Oct 06, 2021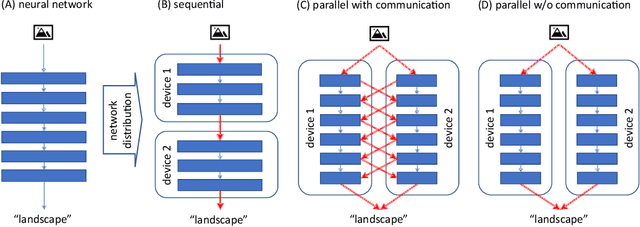

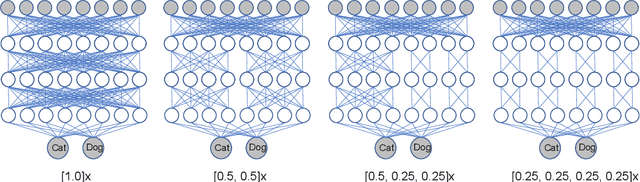

When several limited power devices are available, one of the most efficient ways to make profit of these resources, while reducing the processing latency and communication load, is to run in parallel several neural sub-networks and to fuse the result at the end of processing. However, such a combination of sub-networks must be trained specifically for each particular configuration of devices (characterized by number of devices and their capacities) which may vary over different model deployments and even within the same deployment. In this work we introduce parallelly distributable slimmable (ParaDiS) neural networks that are splittable in parallel among various device configurations without retraining. While inspired by slimmable networks allowing instant adaptation to resources on just one device, ParaDiS networks consist of several multi-device distributable configurations or switches that strongly share the parameters between them. We evaluate ParaDiS framework on MobileNet v1 and ResNet-50 architectures on ImageNet classification task. We show that ParaDiS switches achieve similar or better accuracy than the individual models, i.e., distributed models of the same structure trained individually. Moreover, we show that, as compared to universally slimmable networks that are not distributable, the accuracy of distributable ParaDiS switches either does not drop at all or drops by a maximum of 1 % only in the worst cases.
Detecting Human-Object Interaction with Mixed Supervision
Nov 12, 2020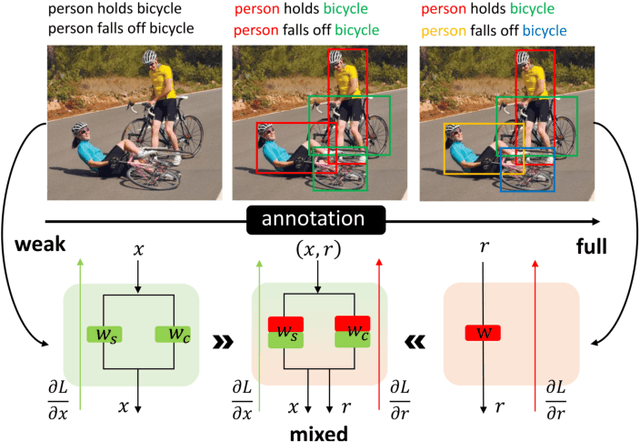
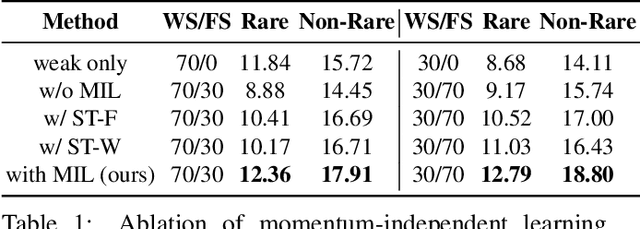
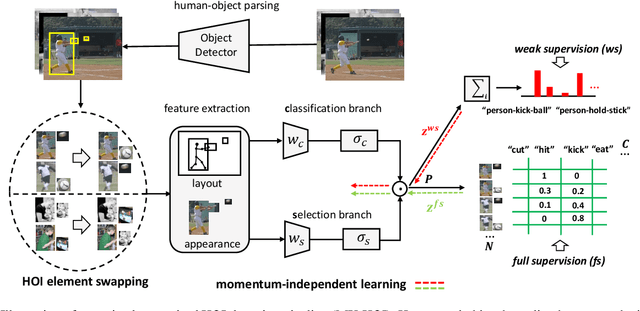
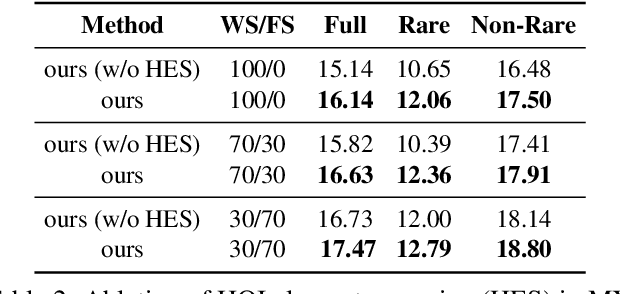
Human object interaction (HOI) detection is an important task in image understanding and reasoning. It is in a form of HOI triplet <human; verb; object>, requiring bounding boxes for human and object, and action between them for the task completion. In other words, this task requires strong supervision for training that is however hard to procure. A natural solution to overcome this is to pursue weakly-supervised learning, where we only know the presence of certain HOI triplets in images but their exact location is unknown. Most weakly-supervised learning methods do not make provision for leveraging data with strong supervision, when they are available; and indeed a na\"ive combination of this two paradigms in HOI detection fails to make contributions to each other. In this regard we propose a mixed-supervised HOI detection pipeline: thanks to a specific design of momentum-independent learning that learns seamlessly across these two types of supervision. Moreover, in light of the annotation insufficiency in mixed supervision, we introduce an HOI element swapping technique to synthesize diverse and hard negatives across images and improve the robustness of the model. Our method is evaluated on the challenging HICO-DET dataset. It performs close to or even better than many fully-supervised methods by using a mixed amount of strong and weak annotations; furthermore, it outperforms representative state of the art weakly and fully-supervised methods under the same supervision.
Transfer Learning in CNNs Using Filter-Trees
Nov 27, 2017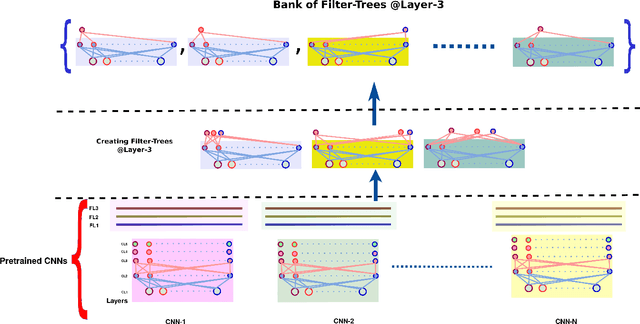

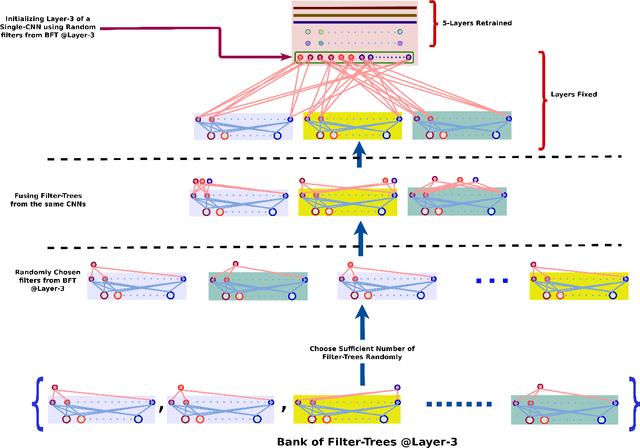
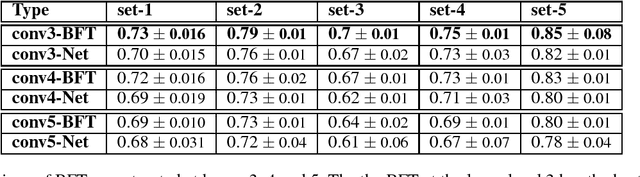
Convolutional Neural Networks (CNNs) are very effective for many pattern recognition tasks. However, training deep CNNs needs extensive computation and large training data. In this paper we propose Bank of Filter-Trees (BFT) as a trans- fer learning mechanism for improving efficiency of learning CNNs. A filter-tree corresponding to a filter in k^{th} convolu- tional layer of a CNN is a subnetwork consisting of the filter along with all its connections to filters in all preceding layers. An ensemble of such filter-trees created from the k^{th} layers of many CNNs learnt on different but related tasks, forms the BFT. To learn a new CNN, we sample from the BFT to select a set of filter trees. This fixes the target net up to the k th layer and only the remaining network would be learnt using train- ing data of new task. Through simulations we demonstrate the effectiveness of this idea of BFT. This method constitutes a novel transfer learning technique where transfer is at a sub- network level; transfer can be effected from multiple source networks; and, with no finetuning of the transferred weights, the performance achieved is on par with networks that are trained from scratch.