 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing The Amortization Gap of Entropy Bottleneck In End-to-End Image Compression
Sep 02, 2022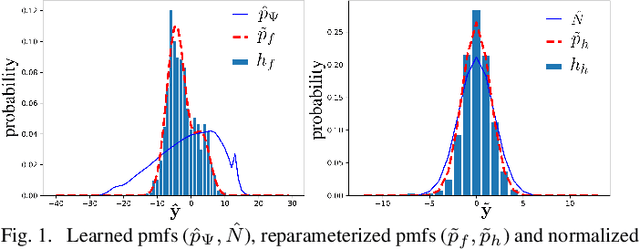
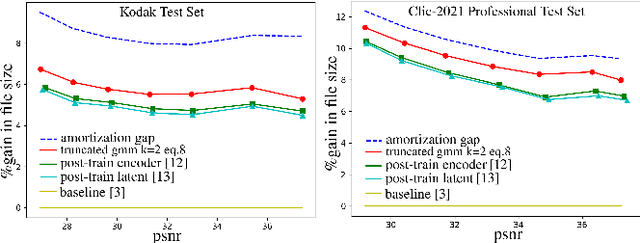
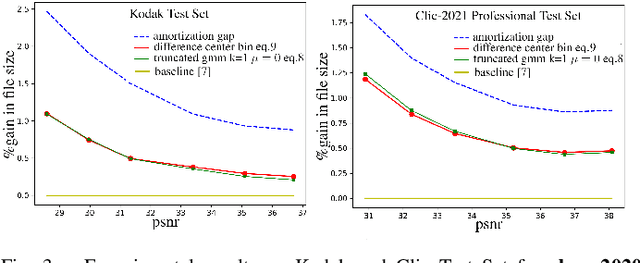
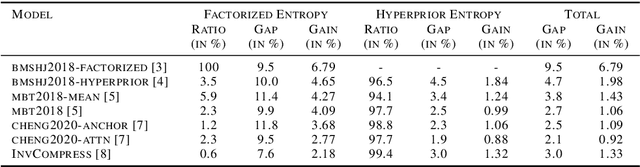
End-to-end deep trainable models are about to exceed the performance of the traditional handcrafted compression techniques on videos and images. The core idea is to learn a non-linear transformation, modeled as a deep neural network, mapping input image into latent space, jointly with an entropy model of the latent distribution. The decoder is also learned as a deep trainable network, and the reconstructed image measures the distortion. These methods enforce the latent to follow some prior distributions. Since these priors are learned by optimization over the entire training set, the performance is optimal in average. However, it cannot fit exactly on every single new instance, hence damaging the compression performance by enlarging the bit-stream. In this paper, we propose a simple yet efficient instance-based parameterization method to reduce this amortization gap at a minor cost. The proposed method is applicable to any end-to-end compressing methods, improving the compression bitrate by 1% without any impact on the reconstruction quality.