 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding path and cycle counting formulae in graphs with Deep Reinforcement Learning
Oct 02, 2024
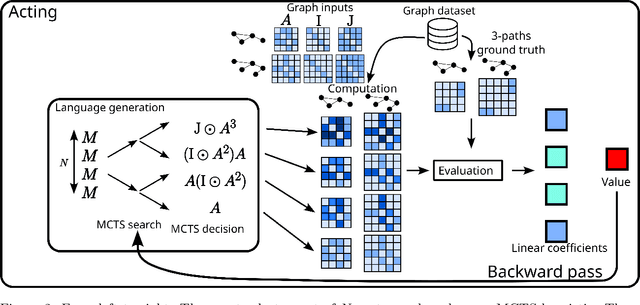
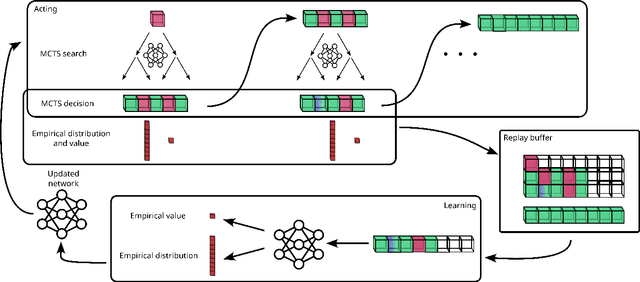
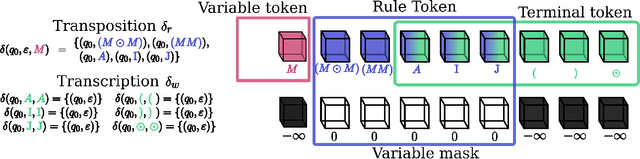
This paper presents Grammar Reinforcement Learning (GRL), a reinforcement learning algorithm that uses Monte Carlo Tree Search (MCTS) and a transformer architecture that models a Pushdown Automaton (PDA) within a context-free grammar (CFG) framework. Taking as use case the problem of efficiently counting paths and cycles in graphs, a key challenge in network analysis, computer science, biology, and social sciences, GRL discovers new matrix-based formulas for path/cycle counting that improve computational efficiency by factors of two to six w.r.t state-of-the-art approaches. Our contributions include: (i) a framework for generating gramformers that operate within a CFG, (ii) the development of GRL for optimizing formulas within grammatical structures, and (iii) the discovery of novel formulas for graph substructure counting, leading to significant computational improvements.
Temporal receptive field in dynamic graph learning: A comprehensive analysis
Jul 19, 2024



Dynamic link prediction is a critical task in the analysis of evolving networks, with applications ranging from recommender systems to economic exchanges. However, the concept of the temporal receptive field, which refers to the temporal context that models use for making predictions, has been largely overlooked and insufficiently analyzed in existing research. In this study, we present a comprehensive analysis of the temporal receptive field in dynamic graph learning. By examining multiple datasets and models, we formalize the role of temporal receptive field and highlight their crucial influence on predictive accuracy. Our results demonstrate that appropriately chosen temporal receptive field can significantly enhance model performance, while for some models, overly large windows may introduce noise and reduce accuracy. We conduct extensive benchmarking to validate our findings, ensuring that all experiments are fully reproducible. Code is available at https://github.com/ykrmm/BenchmarkTW .
Dynamic Graph Representation Learning with Neural Networks: A Survey
Apr 12, 2023

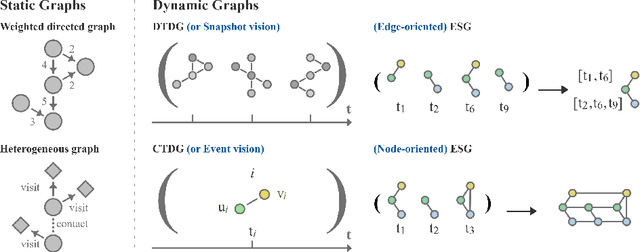

In recent years, Dynamic Graph (DG) representations have been increasingly used for modeling dynamic systems due to their ability to integrate both topological and temporal information in a compact representation. Dynamic graphs allow to efficiently handle applications such as social network prediction, recommender systems, traffic forecasting or electroencephalography analysis, that can not be adressed using standard numeric representations. As a direct consequence of the emergence of dynamic graph representations, dynamic graph learning has emerged as a new machine learning problem, combining challenges from both sequential/temporal data processing and static graph learning. In this research area, Dynamic Graph Neural Network (DGNN) has became the state of the art approach and plethora of models have been proposed in the very recent years. This paper aims at providing a review of problems and models related to dynamic graph learning. The various dynamic graph supervised learning settings are analysed and discussed. We identify the similarities and differences between existing models with respect to the way time information is modeled. Finally, general guidelines for a DGNN designer when faced with a dynamic graph learning problem are provided.
Technical report: Graph Neural Networks go Grammatical
Mar 02, 2023



This paper proposes a new GNN design strategy. This strategy relies on Context-Free Grammars (CFG) generating the matrix language MATLANG. It enables us to ensure both WL-expressive power, substructure counting abilities and spectral properties. Applying our strategy, we design Grammatical Graph Neural Network G$ ^2$N$^2$, a provably 3-WL GNN able to count at edge-level cycles of length up to 6 and able to reach band-pass filters. A large number of experiments covering these properties corroborate the presented theoretical results.
Breaking the Limits of Message Passing Graph Neural Networks
Jun 08, 2021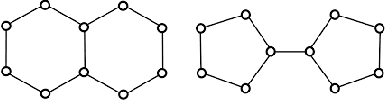
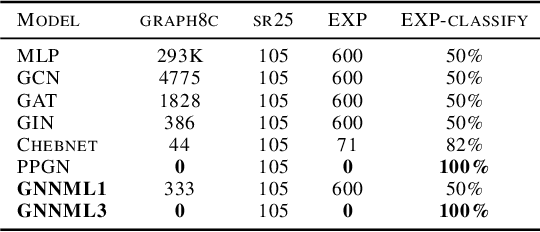
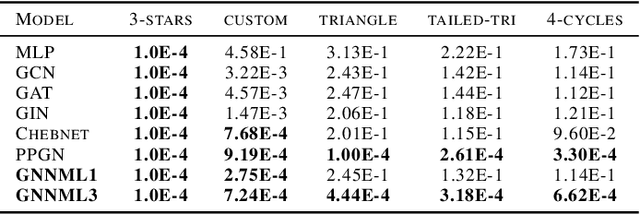
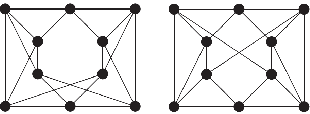
Since the Message Passing (Graph) Neural Networks (MPNNs) have a linear complexity with respect to the number of nodes when applied to sparse graphs, they have been widely implemented and still raise a lot of interest even though their theoretical expressive power is limited to the first order Weisfeiler-Lehman test (1-WL). In this paper, we show that if the graph convolution supports are designed in spectral-domain by a non-linear custom function of eigenvalues and masked with an arbitrary large receptive field, the MPNN is theoretically more powerful than the 1-WL test and experimentally as powerful as a 3-WL existing models, while remaining spatially localized. Moreover, by designing custom filter functions, outputs can have various frequency components that allow the convolution process to learn different relationships between a given input graph signal and its associated properties. So far, the best 3-WL equivalent graph neural networks have a computational complexity in $\mathcal{O}(n^3)$ with memory usage in $\mathcal{O}(n^2)$, consider non-local update mechanism and do not provide the spectral richness of output profile. The proposed method overcomes all these aforementioned problems and reaches state-of-the-art results in many downstream tasks.
Neural Networks Regularization Through Class-wise Invariant Representation Learning
Dec 22, 2017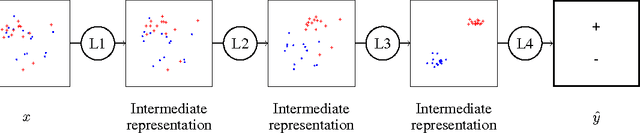


Training deep neural networks is known to require a large number of training samples. However, in many applications only few training samples are available. In this work, we tackle the issue of training neural networks for classification task when few training samples are available. We attempt to solve this issue by proposing a new regularization term that constrains the hidden layers of a network to learn class-wise invariant representations. In our regularization framework, learning invariant representations is generalized to the class membership where samples with the same class should have the same representation. Numerical experiments over MNIST and its variants showed that our proposal helps improving the generalization of neural network particularly when trained with few samples. We provide the source code of our framework https://github.com/sbelharbi/learning-class-invariant-features .
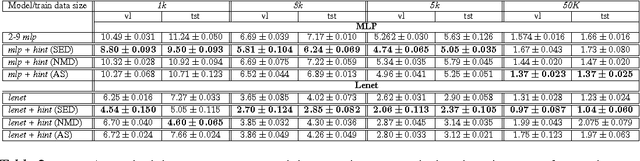
Deep Neural Networks Regularization for Structured Output Prediction
Oct 30, 2017
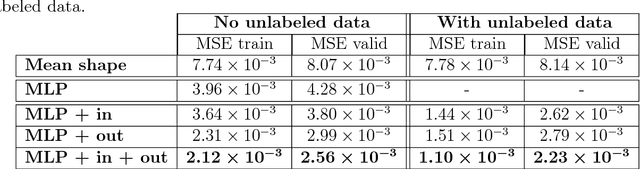
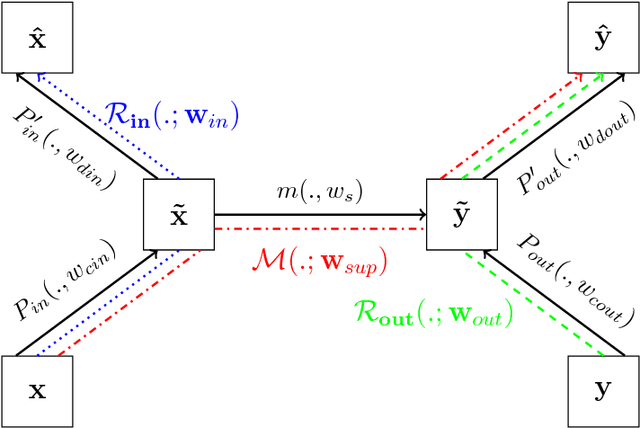
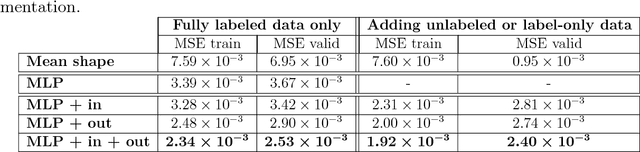
A deep neural network model is a powerful framework for learning representations. Usually, it is used to learn the relation $x \to y$ by exploiting the regularities in the input $x$. In structured output prediction problems, $y$ is multi-dimensional and structural relations often exist between the dimensions. The motivation of this work is to learn the output dependencies that may lie in the output data in order to improve the prediction accuracy. Unfortunately, feedforward networks are unable to exploit the relations between the outputs. In order to overcome this issue, we propose in this paper a regularization scheme for training neural networks for these particular tasks using a multi-task framework. Our scheme aims at incorporating the learning of the output representation $y$ in the training process in an unsupervised fashion while learning the supervised mapping function $x \to y$. We evaluate our framework on a facial landmark detection problem which is a typical structured output task. We show over two public challenging datasets (LFPW and HELEN) that our regularization scheme improves the generalization of deep neural networks and accelerates their training. The use of unlabeled data and label-only data is also explored, showing an additional improvement of the results. We provide an opensource implementation (https://github.com/sbelharbi/structured-output-ae) of our framework.
Graph edit distance : a new binary linear programming formulation
May 21, 2015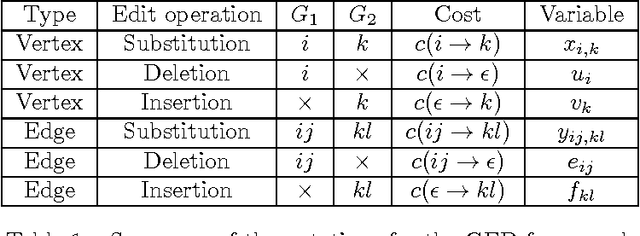
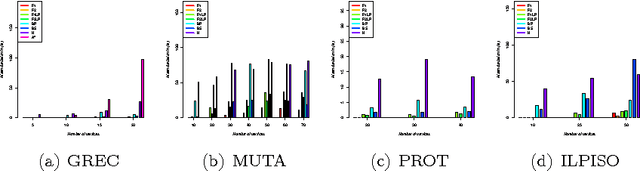
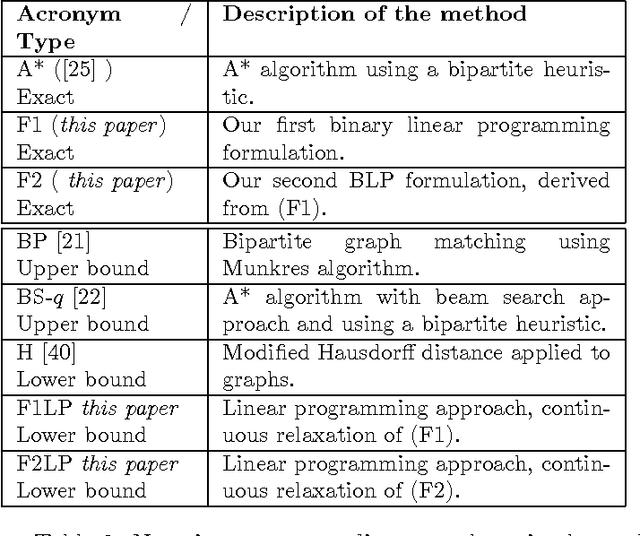

Graph edit distance (GED) is a powerful and flexible graph matching paradigm that can be used to address different tasks in structural pattern recognition, machine learning, and data mining. In this paper, some new binary linear programming formulations for computing the exact GED between two graphs are proposed. A major strength of the formulations lies in their genericity since the GED can be computed between directed or undirected fully attributed graphs (i.e. with attributes on both vertices and edges). Moreover, a relaxation of the domain constraints in the formulations provides efficient lower bound approximations of the GED. A complete experimental study comparing the proposed formulations with 4 state-of-the-art algorithms for exact and approximate graph edit distances is provided. By considering both the quality of the proposed solution and the efficiency of the algorithms as performance criteria, the results show that none of the compared methods dominates the others in the Pareto sense. As a consequence, faced to a given real-world problem, a trade-off between quality and efficiency has to be chosen w.r.t. the application constraints. In this context, this paper provides a guide that can be used to choose the appropriate method.