 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocXPand-25k: a large and diverse benchmark dataset for identity documents analysis
Jul 30, 2024
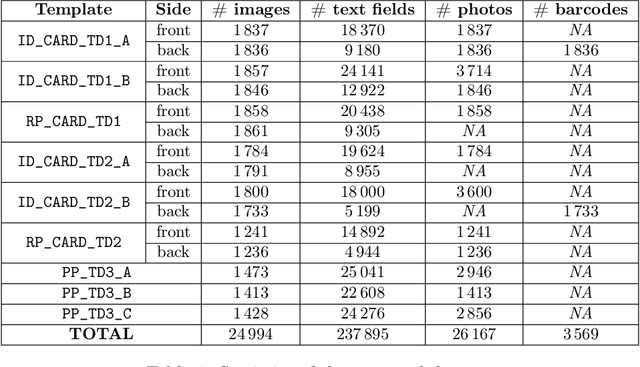

Identity document (ID) image analysis has become essential for many online services, like bank account opening or insurance subscription. In recent years, much research has been conducted on subjects like document localization, text recognition and fraud detection, to achieve a level of accuracy reliable enough to automatize identity verification. However, there are only a few available datasets to benchmark ID analysis methods, mainly because of privacy restrictions, security requirements and legal reasons. In this paper, we present the DocXPand-25k dataset, which consists of 24,994 richly labeled IDs images, generated using custom-made vectorial templates representing nine fictitious ID designs, including four identity cards, two residence permits and three passports designs. These synthetic IDs feature artificially generated personal information (names, dates, identifiers, faces, barcodes, ...), and present a rich diversity in the visual layouts and textual contents. We collected about 5.8k diverse backgrounds coming from real-world photos, scans and screenshots of IDs to guarantee the variety of the backgrounds. The software we wrote to generate these images has been published (https://github.com/QuickSign/docxpand/) under the terms of the MIT license, and our dataset has been published (https://github.com/QuickSign/docxpand/releases/tag/v1.0.0) under the terms of the CC-BY-NC-SA 4.0 License.
Data Efficient Training of a U-Net Based Architecture for Structured Documents Localization
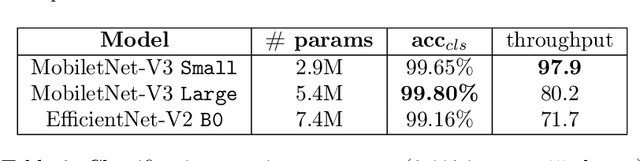
Oct 02, 2023Structured documents analysis and recognition are essential for modern online on-boarding processes, and document localization is a crucial step to achieve reliable key information extraction. While deep-learning has become the standard technique used to solve document analysis problems, real-world applications in industry still face the limited availability of labelled data and of computational resources when training or fine-tuning deep-learning models. To tackle these challenges, we propose SDL-Net: a novel U-Net like encoder-decoder architecture for the localization of structured documents. Our approach allows pre-training the encoder of SDL-Net on a generic dataset containing samples of various document classes, and enables fast and data-efficient fine-tuning of decoders to support the localization of new document classes. We conduct extensive experiments on a proprietary dataset of structured document images to demonstrate the effectiveness and the generalization capabilities of the proposed approach.
Graph edit distance : a new binary linear programming formulation
May 21, 2015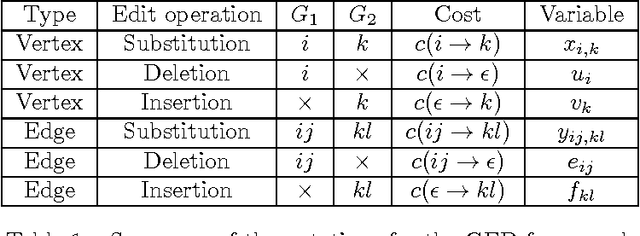
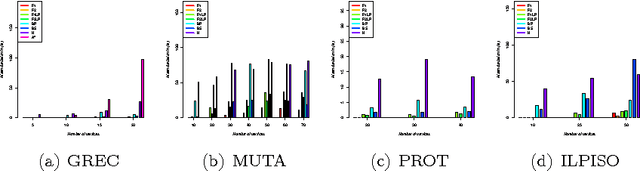
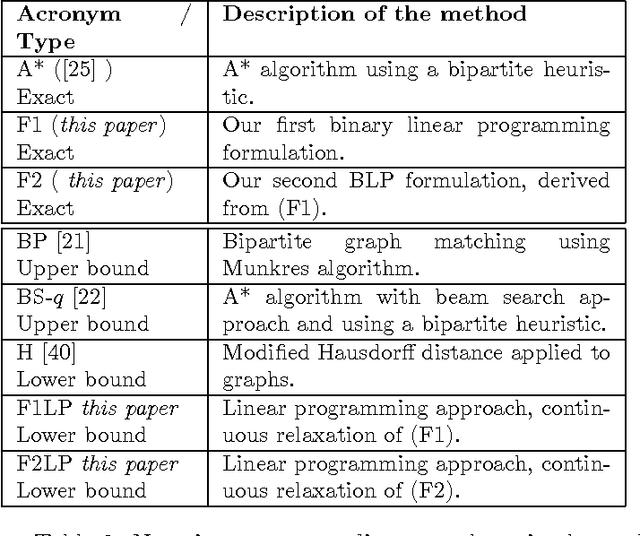

Graph edit distance (GED) is a powerful and flexible graph matching paradigm that can be used to address different tasks in structural pattern recognition, machine learning, and data mining. In this paper, some new binary linear programming formulations for computing the exact GED between two graphs are proposed. A major strength of the formulations lies in their genericity since the GED can be computed between directed or undirected fully attributed graphs (i.e. with attributes on both vertices and edges). Moreover, a relaxation of the domain constraints in the formulations provides efficient lower bound approximations of the GED. A complete experimental study comparing the proposed formulations with 4 state-of-the-art algorithms for exact and approximate graph edit distances is provided. By considering both the quality of the proposed solution and the efficiency of the algorithms as performance criteria, the results show that none of the compared methods dominates the others in the Pareto sense. As a consequence, faced to a given real-world problem, a trade-off between quality and efficiency has to be chosen w.r.t. the application constraints. In this context, this paper provides a guide that can be used to choose the appropriate method.