 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding path and cycle counting formulae in graphs with Deep Reinforcement Learning
Oct 02, 2024
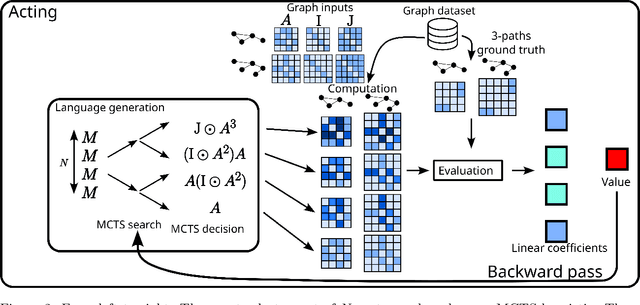
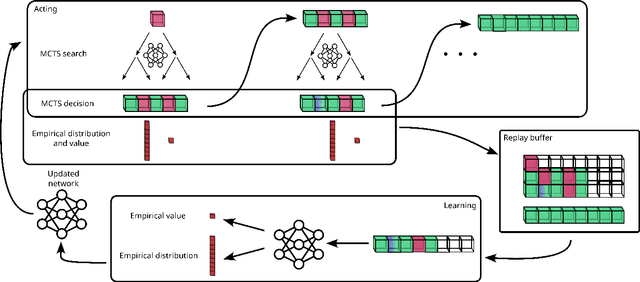
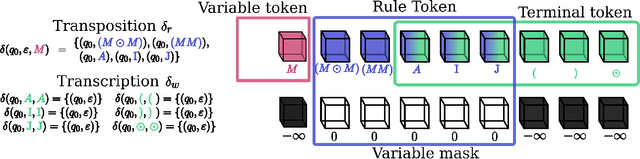
This paper presents Grammar Reinforcement Learning (GRL), a reinforcement learning algorithm that uses Monte Carlo Tree Search (MCTS) and a transformer architecture that models a Pushdown Automaton (PDA) within a context-free grammar (CFG) framework. Taking as use case the problem of efficiently counting paths and cycles in graphs, a key challenge in network analysis, computer science, biology, and social sciences, GRL discovers new matrix-based formulas for path/cycle counting that improve computational efficiency by factors of two to six w.r.t state-of-the-art approaches. Our contributions include: (i) a framework for generating gramformers that operate within a CFG, (ii) the development of GRL for optimizing formulas within grammatical structures, and (iii) the discovery of novel formulas for graph substructure counting, leading to significant computational improvements.
Deep graph matching meets mixed-integer linear programming: Relax at your own risk ?
Aug 01, 2021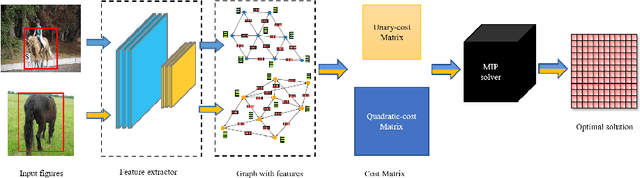
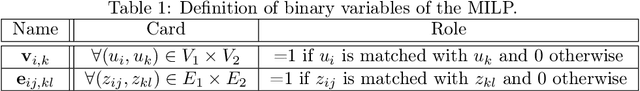

Graph matching is an important problem that has received widespread attention, especially in the field of computer vision. Recently, state-of-the-art methods seek to incorporate graph matching with deep learning. However, there is no research to explain what role the graph matching algorithm plays in the model. Therefore, we propose an approach integrating a MILP formulation of the graph matching problem. This formulation is solved to optimal and it provides inherent baseline. Meanwhile, similar approaches are derived by releasing the optimal guarantee of the graph matching solver and by introducing a quality level. This quality level controls the quality of the solutions provided by the graph matching solver. In addition, several relaxations of the graph matching problem are put to the test. Our experimental evaluation gives several theoretical insights and guides the direction of deep graph matching methods.
A Convolutional Neural Network into graph space
Feb 25, 2020

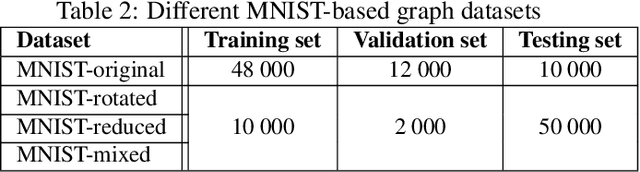

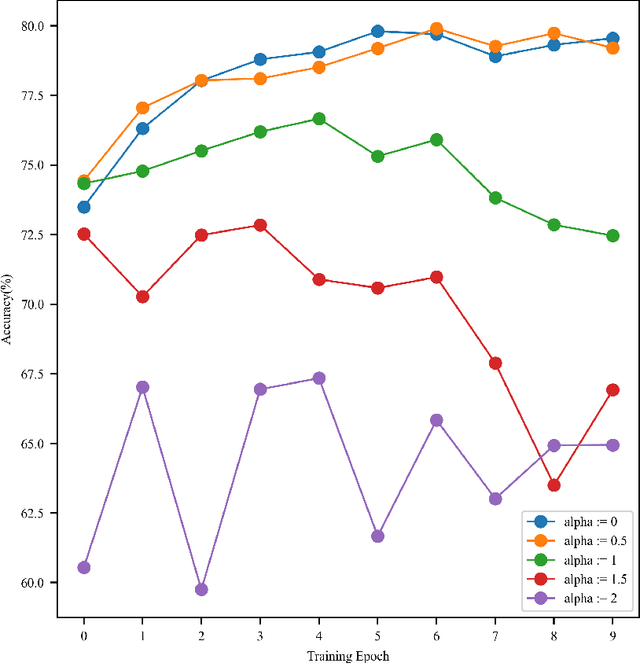
Convolutional neural networks (CNNs), in a few decades, have outperformed the existing state of the art methods in classification context. However, in the way they were formalised, CNNs are bound to operate on euclidean spaces. Indeed, convolution is a signal operation that are defined on euclidean spaces. This has restricted deep learning main use to euclidean-defined data such as sound or image. And yet, numerous computer application fields (among which network analysis, computational social science, chemo-informatics or computer graphics) induce non-euclideanly defined data such as graphs, networks or manifolds. In this paper we propose a new convolution neural network architecture, defined directly into graph space. Convolution and pooling operators are defined in graph domain. We show its usability in a back-propagation context. Experimental results show that our model performance is at state of the art level on simple tasks. It shows robustness with respect to graph domain changes and improvement with respect to other euclidean and non-euclidean convolutional architectures.
Graph edit distance : a new binary linear programming formulation
May 21, 2015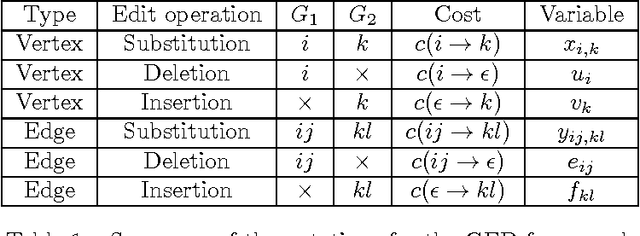
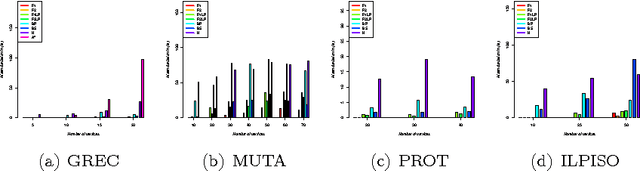
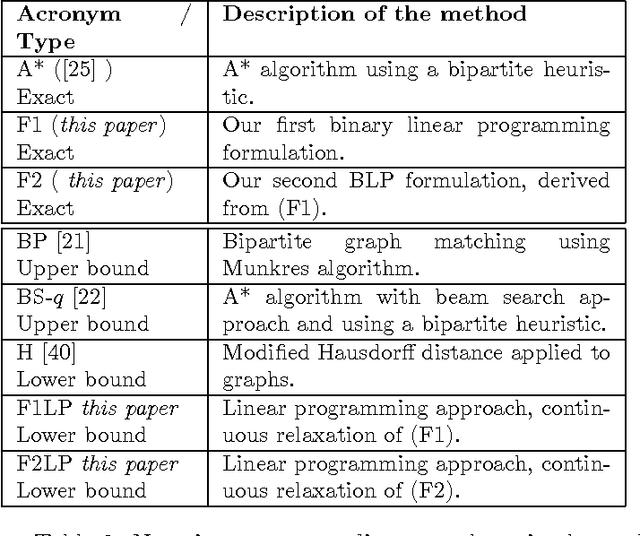

Graph edit distance (GED) is a powerful and flexible graph matching paradigm that can be used to address different tasks in structural pattern recognition, machine learning, and data mining. In this paper, some new binary linear programming formulations for computing the exact GED between two graphs are proposed. A major strength of the formulations lies in their genericity since the GED can be computed between directed or undirected fully attributed graphs (i.e. with attributes on both vertices and edges). Moreover, a relaxation of the domain constraints in the formulations provides efficient lower bound approximations of the GED. A complete experimental study comparing the proposed formulations with 4 state-of-the-art algorithms for exact and approximate graph edit distances is provided. By considering both the quality of the proposed solution and the efficiency of the algorithms as performance criteria, the results show that none of the compared methods dominates the others in the Pareto sense. As a consequence, faced to a given real-world problem, a trade-off between quality and efficiency has to be chosen w.r.t. the application constraints. In this context, this paper provides a guide that can be used to choose the appropriate method.