 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding path and cycle counting formulae in graphs with Deep Reinforcement Learning
Oct 02, 2024
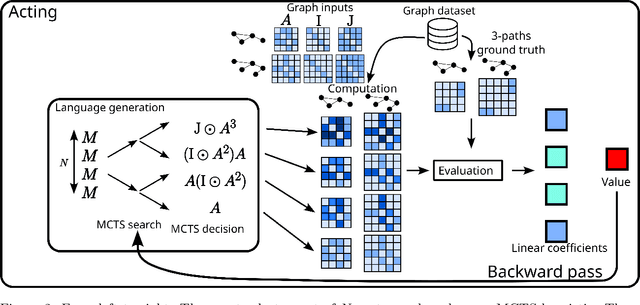
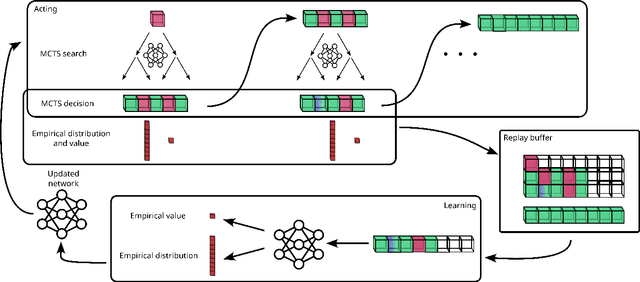
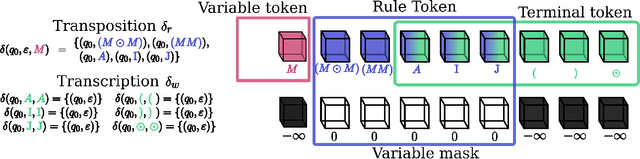
This paper presents Grammar Reinforcement Learning (GRL), a reinforcement learning algorithm that uses Monte Carlo Tree Search (MCTS) and a transformer architecture that models a Pushdown Automaton (PDA) within a context-free grammar (CFG) framework. Taking as use case the problem of efficiently counting paths and cycles in graphs, a key challenge in network analysis, computer science, biology, and social sciences, GRL discovers new matrix-based formulas for path/cycle counting that improve computational efficiency by factors of two to six w.r.t state-of-the-art approaches. Our contributions include: (i) a framework for generating gramformers that operate within a CFG, (ii) the development of GRL for optimizing formulas within grammatical structures, and (iii) the discovery of novel formulas for graph substructure counting, leading to significant computational improvements.
Technical report: Graph Neural Networks go Grammatical
Mar 02, 2023



This paper proposes a new GNN design strategy. This strategy relies on Context-Free Grammars (CFG) generating the matrix language MATLANG. It enables us to ensure both WL-expressive power, substructure counting abilities and spectral properties. Applying our strategy, we design Grammatical Graph Neural Network G$ ^2$N$^2$, a provably 3-WL GNN able to count at edge-level cycles of length up to 6 and able to reach band-pass filters. A large number of experiments covering these properties corroborate the presented theoretical results.
Non-Aligned Distribution Distance using Metric Measure Embedding and Optimal Transport
Feb 19, 2020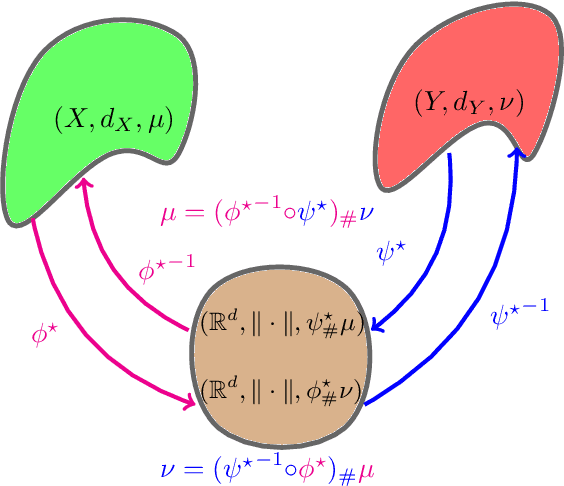
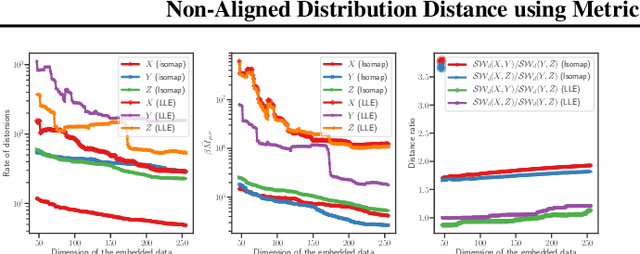
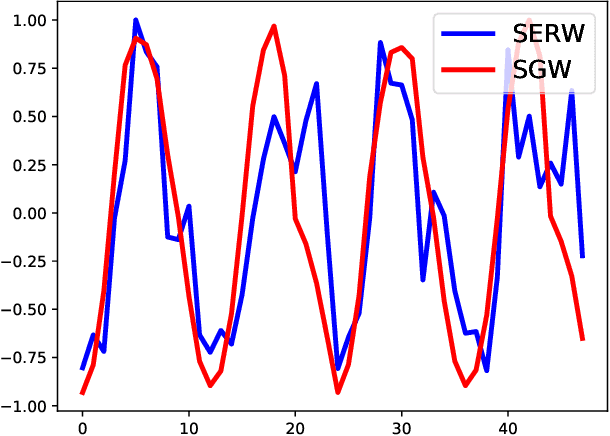
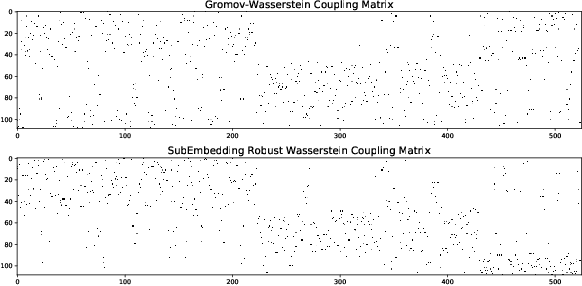
We propose a novel approach for comparing distributions whose supports do not necessarily lie on the same metric space. Unlike Gromov-Wasserstein (GW) distance that compares pairwise distance of elements from each distribution, we consider a method that embeds the metric measure spaces in a common Euclidean space and computes an optimal transport (OT) on the embedded distributions. This leads to what we call a sub-embedding robust Wasserstein(SERW). Under some conditions, SERW is a distance that considers an OT distance of the (low-distorted) embedded distributions using a common metric. In addition to this novel proposal that generalizes several recent OT works, our contributions stand on several theoretical analyses: i) we characterize the embedding spaces to define SERW distance for distribution alignment; ii) we prove that SERW mimics almost the same properties of GW distance, and we give a cost relation between GW and SERW. The paper also provides some numerical experiments illustrating how SERW behaves on matching problems in real-world.
Screening Sinkhorn Algorithm for Regularized Optimal Transport
Jun 20, 2019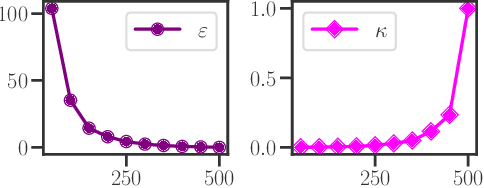
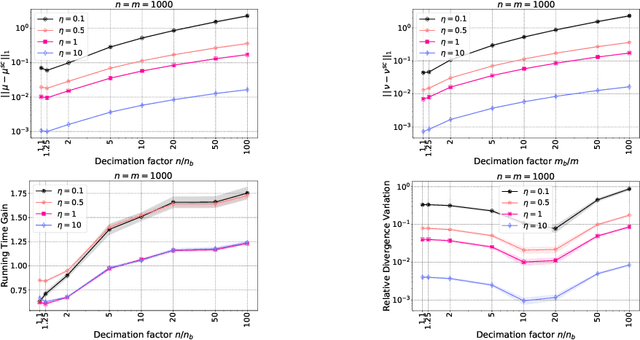
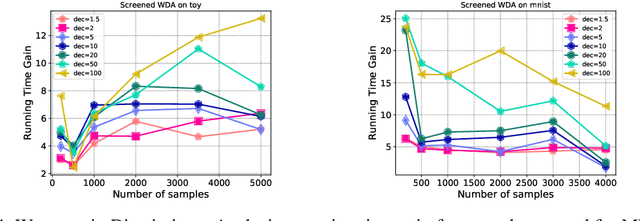
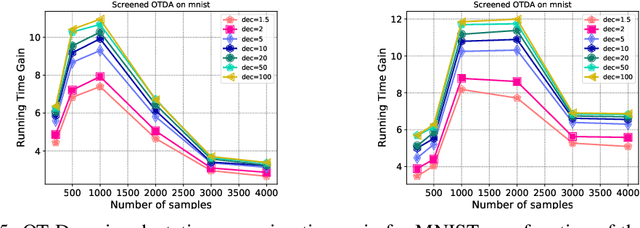
We introduce in this paper a novel strategy for efficiently approximate the Sinkhorn distance between two discrete measures. After identifying neglectible components of the dual solution of the regularized Sinkhorn problem, we propose to screen those components by directly setting them at that value before entering the Sinkhorn problem. This allows us to solve a smaller Sinkhorn problem while ensuring approximation with provable guarantees. More formally, the approach is based on a reformulation of dual of Sinkhorn divergence problem and on the KKT optimality conditions of this problem, which enable identification of dual components to be screened. This new analysis leads to the Screenkhorn algorithm. We illustrate the efficiency of Screenkhorn on complex tasks such as dimensionality reduction or domain adaptation involving regularized optimal transport.