 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark of State-Space Models vs. Transformers and BiLSTM-based Models for Historical Newspaper OCR
Apr 01, 2026End-to-end OCR for historical newspapers remains challenging, as models must handle long text sequences, degraded print quality, and complex layouts. While Transformer-based recognizers dominate current research, their quadratic complexity limits efficient paragraph-level transcription and large-scale deployment. We investigate linear-time State-Space Models (SSMs), specifically Mamba, as a scalable alternative to Transformer-based sequence modeling for OCR. We present to our knowledge, the first OCR architecture based on SSMs, combining a CNN visual encoder with bi-directional and autoregressive Mamba sequence modeling, and conduct a large-scale benchmark comparing SSMs with Transformer- and BiLSTM-based recognizers. Multiple decoding strategies (CTC, autoregressive, and non-autoregressive) are evaluated under identical training conditions alongside strong neural baselines (VAN, DAN, DANIEL) and widely used off-the-shelf OCR engines (PERO-OCR, Tesseract OCR, TrOCR, Gemini). Experiments on historical newspapers from the Bibliothèque nationale du Luxembourg, with newly released >99% verified gold-standard annotations, and cross-dataset tests on Fraktur and Antiqua lines, show that all neural models achieve low error rates (~2% CER), making computational efficiency the main differentiator. Mamba-based models maintain competitive accuracy while halving inference time and exhibiting superior memory scaling (1.26x vs 2.30x growth at 1000 chars), reaching 6.07% CER at the severely degraded paragraph level compared to 5.24% for DAN, while remaining 2.05x faster. We release code, trained models, and standardized evaluation protocols to enable reproducible research and guide practitioners in large-scale cultural heritage OCR.
See Without Decoding: Motion-Vector-Based Tracking in Compressed Video
Jan 29, 2026We propose a lightweight compressed-domain tracking model that operates directly on video streams, without requiring full RGB video decoding. Using motion vectors and transform coefficients from compressed data, our deep model propagates object bounding boxes across frames, achieving a computational speed-up of order up to 3.7 with only a slight 4% mAP@0.5 drop vs RGB baseline on MOTS15/17/20 datasets. These results highlight codec-domain motion modeling efficiency for real-time analytics in large monitoring systems.
Temporal receptive field in dynamic graph learning: A comprehensive analysis
Jul 19, 2024



Dynamic link prediction is a critical task in the analysis of evolving networks, with applications ranging from recommender systems to economic exchanges. However, the concept of the temporal receptive field, which refers to the temporal context that models use for making predictions, has been largely overlooked and insufficiently analyzed in existing research. In this study, we present a comprehensive analysis of the temporal receptive field in dynamic graph learning. By examining multiple datasets and models, we formalize the role of temporal receptive field and highlight their crucial influence on predictive accuracy. Our results demonstrate that appropriately chosen temporal receptive field can significantly enhance model performance, while for some models, overly large windows may introduce noise and reduce accuracy. We conduct extensive benchmarking to validate our findings, ensuring that all experiments are fully reproducible. Code is available at https://github.com/ykrmm/BenchmarkTW .
Dynamic Graph Representation Learning with Neural Networks: A Survey
Apr 12, 2023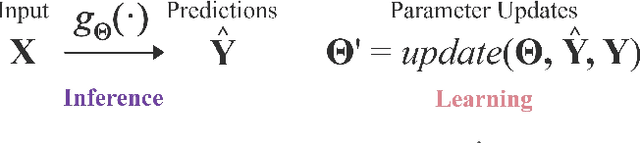

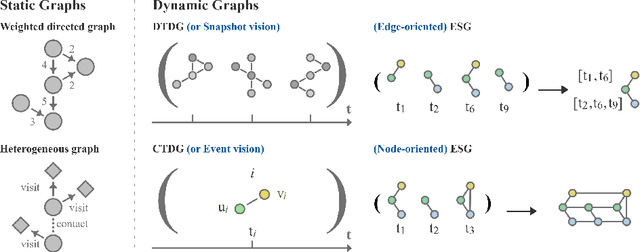

In recent years, Dynamic Graph (DG) representations have been increasingly used for modeling dynamic systems due to their ability to integrate both topological and temporal information in a compact representation. Dynamic graphs allow to efficiently handle applications such as social network prediction, recommender systems, traffic forecasting or electroencephalography analysis, that can not be adressed using standard numeric representations. As a direct consequence of the emergence of dynamic graph representations, dynamic graph learning has emerged as a new machine learning problem, combining challenges from both sequential/temporal data processing and static graph learning. In this research area, Dynamic Graph Neural Network (DGNN) has became the state of the art approach and plethora of models have been proposed in the very recent years. This paper aims at providing a review of problems and models related to dynamic graph learning. The various dynamic graph supervised learning settings are analysed and discussed. We identify the similarities and differences between existing models with respect to the way time information is modeled. Finally, general guidelines for a DGNN designer when faced with a dynamic graph learning problem are provided.
Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition
Jan 25, 2023Recent advances in handwritten text recognition enabled to recognize whole documents in an end-to-end way: the Document Attention Network (DAN) recognizes the characters one after the other through an attention-based prediction process until reaching the end of the document. However, this autoregressive process leads to inference that cannot benefit from any parallelization optimization. In this paper, we propose Faster DAN, a two-step strategy to speed up the recognition process at prediction time: the model predicts the first character of each text line in the document, and then completes all the text lines in parallel through multi-target queries and a specific document positional encoding scheme. Faster DAN reaches competitive results compared to standard DAN, while being at least 4 times faster on whole single-page and double-page images of the RIMES 2009, READ 2016 and MAURDOR datasets. Source code and trained model weights are available at https://github.com/FactoDeepLearning/FasterDAN.
DAN: a Segmentation-free Document Attention Network for Handwritten Document Recognition
Apr 07, 2022
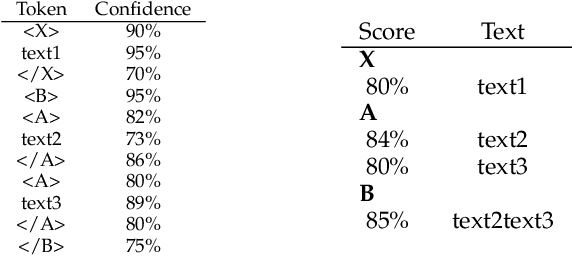

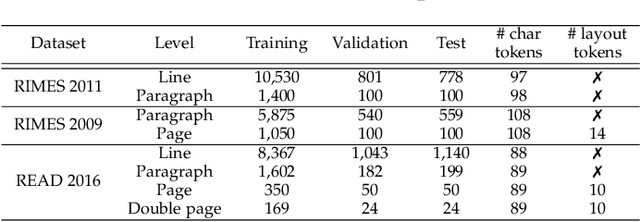
Unconstrained handwritten text recognition is a challenging computer vision task. It is traditionally handled by a two-step approach combining line segmentation followed by text line recognition. For the first time, we propose an end-to-end segmentation-free architecture for the task of handwritten document recognition: the Document Attention Network. In addition to the text recognition, the model is trained to label text parts using begin and end tags in an XML-like fashion. This model is made up of an FCN encoder for feature extraction and a stack of transformer decoder layers for a recurrent token-by-token prediction process. It takes whole text documents as input and sequentially outputs characters, as well as logical layout tokens. Contrary to the existing segmentation-based approaches, the model is trained without using any segmentation label. We achieve competitive results on the READ 2016 dataset at page level, as well as double-page level with a CER of 3.53% and 3.69%, respectively. We also provide results for the RIMES 2009 dataset at page level, reaching 4.54% of CER. We provide all source code and pre-trained model weights at https://github.com/FactoDeepLearning/DAN.
SPAN: a Simple Predict & Align Network for Handwritten Paragraph Recognition
Feb 17, 2021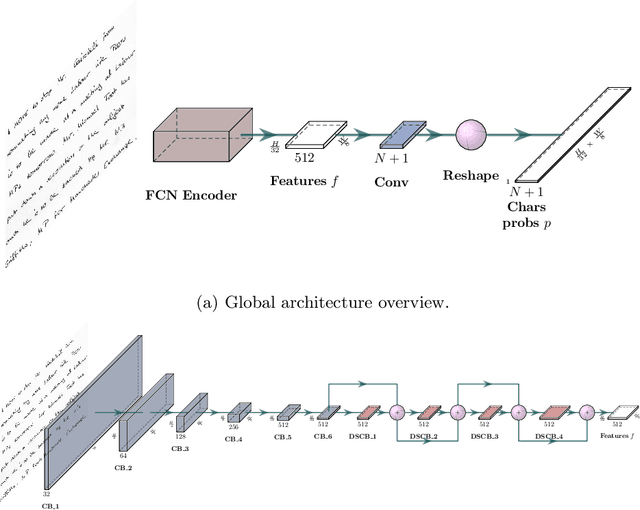
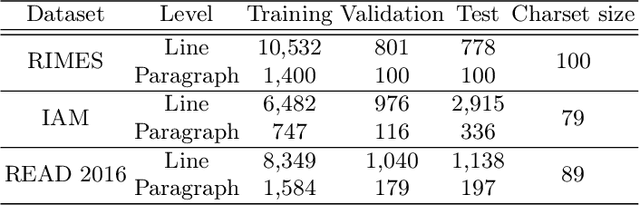
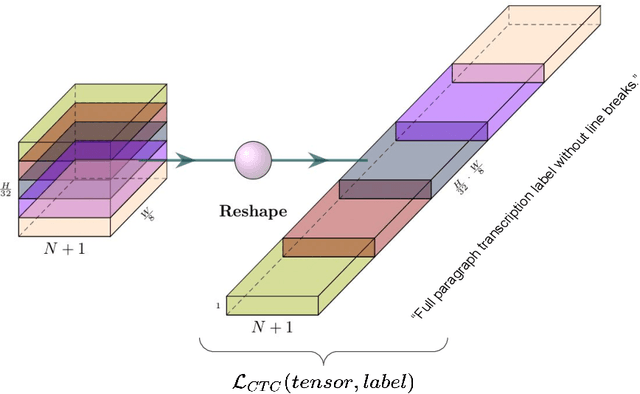
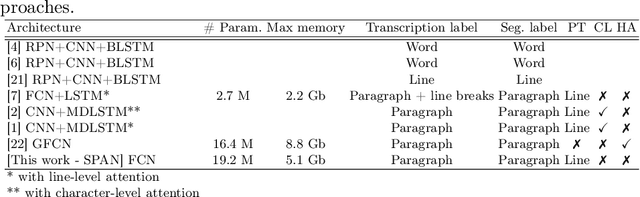
Unconstrained handwriting recognition is an essential task in document analysis. It is usually carried out in two steps. First, the document is segmented into text lines. Second, an Optical Character Recognition model is applied on these line images. We propose the Simple Predict & Align Network: an end-to-end recurrence-free Fully Convolutional Network performing OCR at paragraph level without any prior segmentation stage. The framework is as simple as the one used for the recognition of isolated lines and we achieve competitive results on three popular datasets: RIMES, IAM and READ 2016. The proposed model does not require any dataset adaptation, it can be trained from scratch, without segmentation labels, and it does not require line breaks in the transcription labels. Our code and trained model weights are available at https://github.com/FactoDeepLearning/SPAN.
Recurrence-free unconstrained handwritten text recognition using gated fully convolutional network
Dec 09, 2020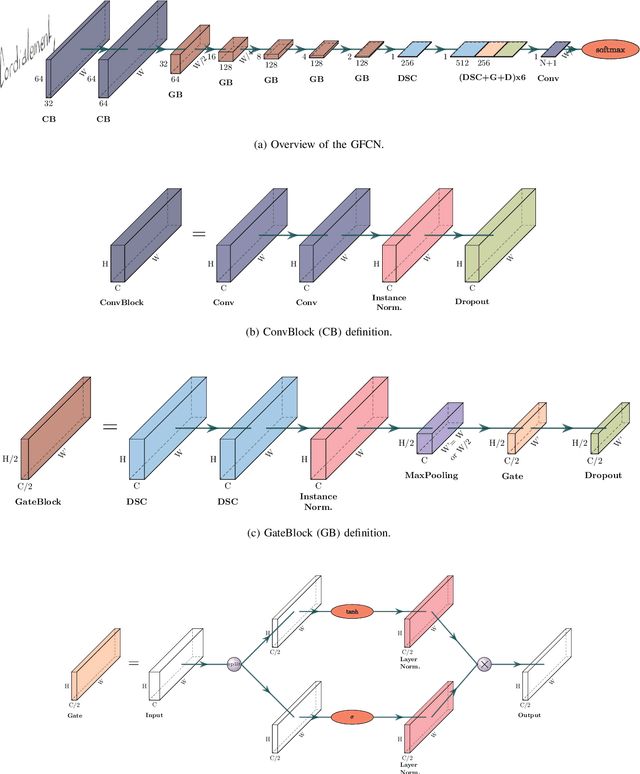
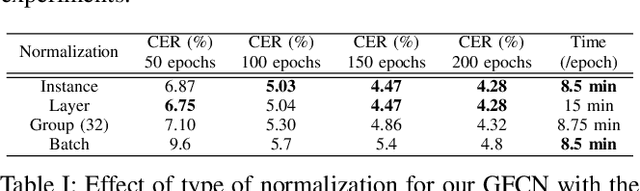


Unconstrained handwritten text recognition is a major step in most document analysis tasks. This is generally processed by deep recurrent neural networks and more specifically with the use of Long Short-Term Memory cells. The main drawbacks of these components are the large number of parameters involved and their sequential execution during training and prediction. One alternative solution to using LSTM cells is to compensate the long time memory loss with an heavy use of convolutional layers whose operations can be executed in parallel and which imply fewer parameters. In this paper we present a Gated Fully Convolutional Network architecture that is a recurrence-free alternative to the well-known CNN+LSTM architectures. Our model is trained with the CTC loss and shows competitive results on both the RIMES and IAM datasets. We release all code to enable reproduction of our experiments: https://github.com/FactoDeepLearning/LinePytorchOCR.
Have convolutions already made recurrence obsolete for unconstrained handwritten text recognition ?
Dec 09, 2020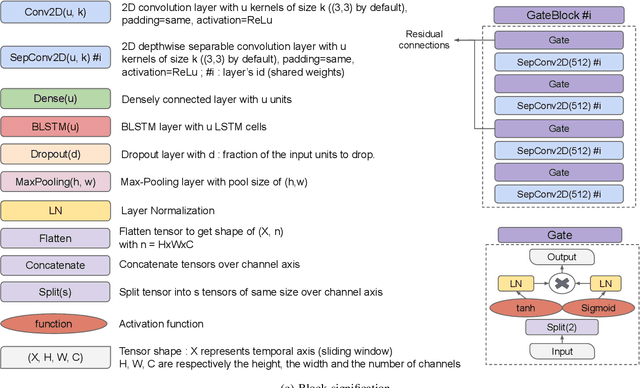

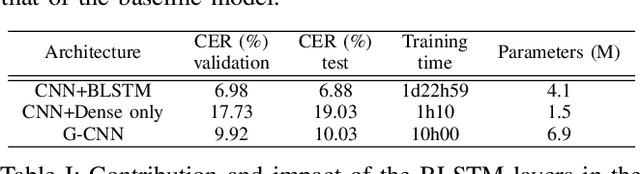
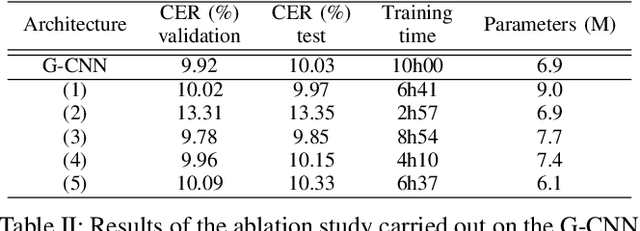
Unconstrained handwritten text recognition remains an important challenge for deep neural networks. These last years, recurrent networks and more specifically Long Short-Term Memory networks have achieved state-of-the-art performance in this field. Nevertheless, they are made of a large number of trainable parameters and training recurrent neural networks does not support parallelism. This has a direct influence on the training time of such architectures, with also a direct consequence on the time required to explore various architectures. Recently, recurrence-free architectures such as Fully Convolutional Networks with gated mechanisms have been proposed as one possible alternative achieving competitive results. In this paper, we explore convolutional architectures and compare them to a CNN+BLSTM baseline. We propose an experimental study regarding different architectures on an offline handwriting recognition task using the RIMES dataset, and a modified version of it that consists of augmenting the images with notebook backgrounds that are printed grids.
End-to-end Handwritten Paragraph Text Recognition Using a Vertical Attention Network
Dec 07, 2020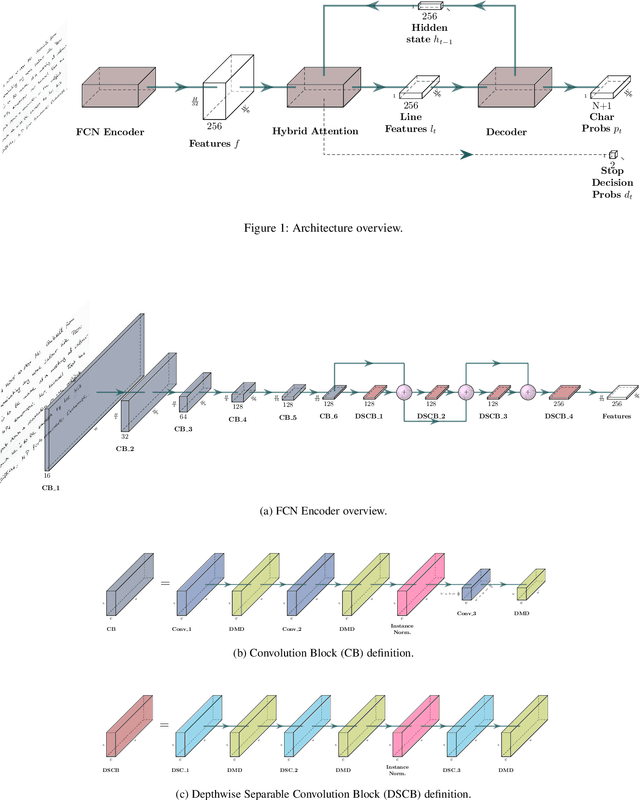
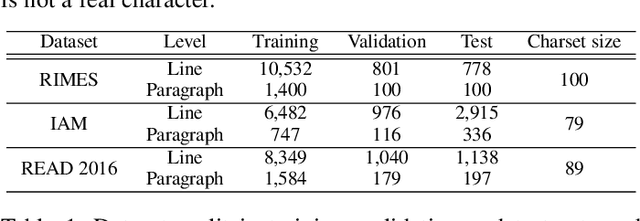


Unconstrained handwritten text recognition remains challenging for computer vision systems. Paragraph text recognition is traditionally achieved by two models: the first one for line segmentation and the second one for text line recognition. We propose a unified end-to-end model using hybrid attention to tackle this task. We achieve state-of-the-art character error rate at line and paragraph levels on three popular datasets: 1.90% for RIMES, 4.32% for IAM and 3.63% for READ 2016. The proposed model can be trained from scratch, without using any segmentation label contrary to the standard approach. Our code and trained model weights are available at https://github.com/FactoDeepLearning/VerticalAttentionOCR.