Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Handwritten Paragraph Text Recognition Using a Vertical Attention Network
Paper and Code
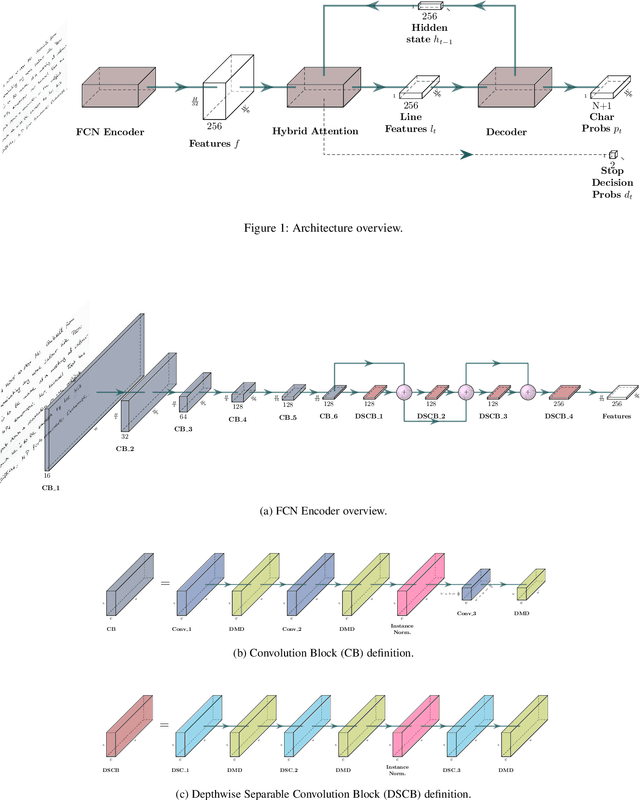
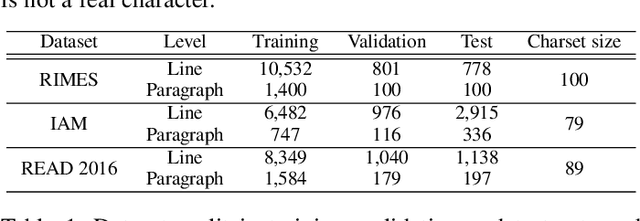


Unconstrained handwritten text recognition remains challenging for computer vision systems. Paragraph text recognition is traditionally achieved by two models: the first one for line segmentation and the second one for text line recognition. We propose a unified end-to-end model using hybrid attention to tackle this task. We achieve state-of-the-art character error rate at line and paragraph levels on three popular datasets: 1.90% for RIMES, 4.32% for IAM and 3.63% for READ 2016. The proposed model can be trained from scratch, without using any segmentation label contrary to the standard approach. Our code and trained model weights are available at https://github.com/FactoDeepLearning/VerticalAttentionOCR.
View paper on