 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-gram Injection into Transformers for Dynamic Language Model Adaptation in Handwritten Text Recognition
Mar 04, 2026Transformer-based encoder-decoder networks have recently achieved impressive results in handwritten text recognition, partly thanks to their auto-regressive decoder which implicitly learns a language model. However, such networks suffer from a large performance drop when evaluated on a target corpus whose language distribution is shifted from the source text seen during training. To retain recognition accuracy despite this language shift, we propose an external n-gram injection (NGI) for dynamic adaptation of the network's language modeling at inference time. Our method allows switching to an n-gram language model estimated on a corpus close to the target distribution, therefore mitigating bias without any extra training on target image-text pairs. We opt for an early injection of the n-gram into the transformer decoder so that the network learns to fully leverage text-only data at the low additional cost of n-gram inference. Experiments on three handwritten datasets demonstrate that the proposed NGI significantly reduces the performance gap between source and target corpora.
Are Time Series Foundation Models Susceptible to Catastrophic Forgetting?
Oct 02, 2025



Time Series Foundation Models (TSFMs) have shown promising zero-shot generalization across diverse forecasting tasks. However, their robustness to continual adaptation remains underexplored. In this work, we investigate the extent to which TSFMs suffer from catastrophic forgetting when fine-tuned sequentially on multiple datasets. Using synthetic datasets designed with varying degrees of periodic structure, we measure the trade-off between adaptation to new data and retention of prior knowledge. Our experiments reveal that, while fine-tuning improves performance on new tasks, it often causes significant degradation on previously learned ones, illustrating a fundamental stability-plasticity dilemma.
How Foundational are Foundation Models for Time Series Forecasting?
Oct 02, 2025
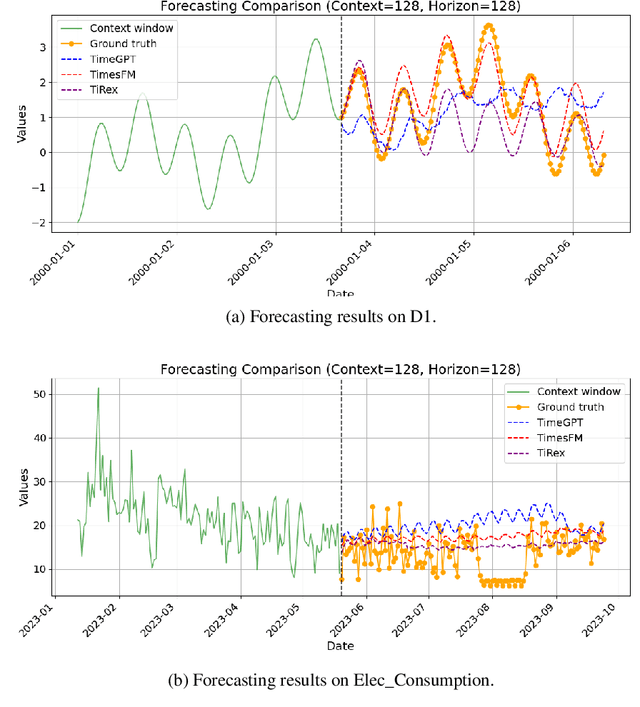

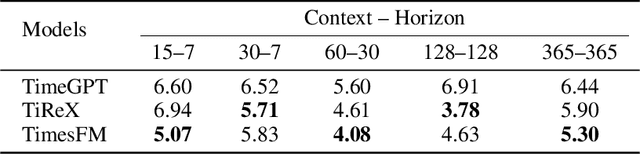
Foundation Models are designed to serve as versatile embedding machines, with strong zero shot capabilities and superior generalization performance when fine-tuned on diverse downstream tasks. While this is largely true for language and vision foundation models, we argue that the inherent diversity of time series data makes them less suited for building effective foundation models. We demonstrate this using forecasting as our downstream task. We show that the zero-shot capabilities of a time series foundation model are significantly influenced and tied to the specific domains it has been pretrained on. Furthermore, when applied to unseen real-world time series data, fine-tuned foundation models do not consistently yield substantially better results, relative to their increased parameter count and memory footprint, than smaller, dedicated models tailored to the specific forecasting task at hand.
Meta-DAN: towards an efficient prediction strategy for page-level handwritten text recognition
Apr 04, 2025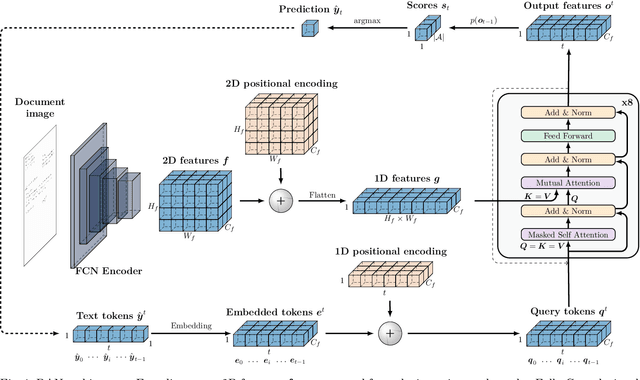
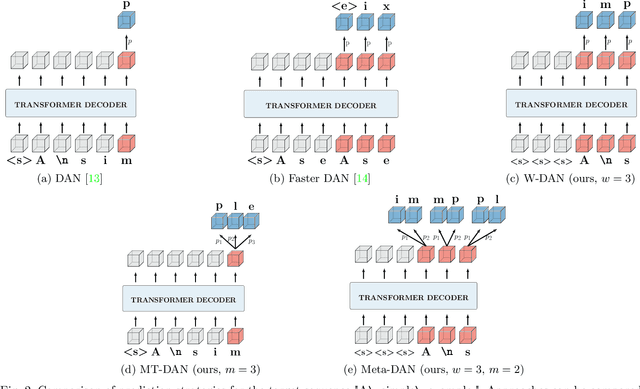
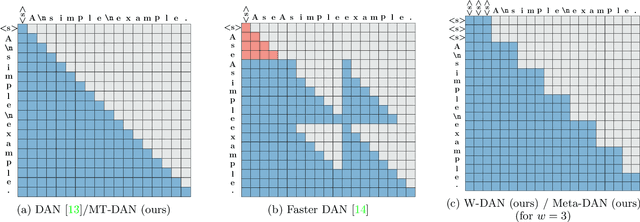
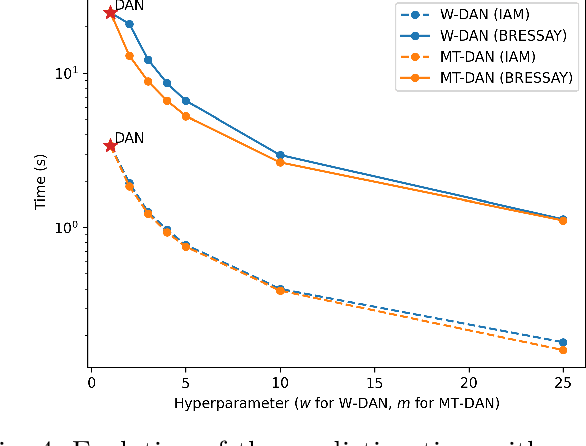
Recent advances in text recognition led to a paradigm shift for page-level recognition, from multi-step segmentation-based approaches to end-to-end attention-based ones. However, the na\"ive character-level autoregressive decoding process results in long prediction times: it requires several seconds to process a single page image on a modern GPU. We propose the Meta Document Attention Network (Meta-DAN) as a novel decoding strategy to reduce the prediction time while enabling a better context modeling. It relies on two main components: windowed queries, to process several transformer queries altogether, enlarging the context modeling with near future; and multi-token predictions, whose goal is to predict several tokens per query instead of only the next one. We evaluate the proposed approach on 10 full-page handwritten datasets and demonstrate state-of-the-art results on average in terms of character error rate. Source code and weights of trained models are available at https://github.com/FactoDeepLearning/meta_dan.
Leveraging Vision-Language Foundation Models for Fine-Grained Downstream Tasks
Jul 13, 2023



Vision-language foundation models such as CLIP have shown impressive zero-shot performance on many tasks and datasets, especially thanks to their free-text inputs. However, they struggle to handle some downstream tasks, such as fine-grained attribute detection and localization. In this paper, we propose a multitask fine-tuning strategy based on a positive/negative prompt formulation to further leverage the capacities of the vision-language foundation models. Using the CLIP architecture as baseline, we show strong improvements on bird fine-grained attribute detection and localization tasks, while also increasing the classification performance on the CUB200-2011 dataset. We provide source code for reproducibility purposes: it is available at https://github.com/FactoDeepLearning/MultitaskVLFM.
Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition
Jan 25, 2023Recent advances in handwritten text recognition enabled to recognize whole documents in an end-to-end way: the Document Attention Network (DAN) recognizes the characters one after the other through an attention-based prediction process until reaching the end of the document. However, this autoregressive process leads to inference that cannot benefit from any parallelization optimization. In this paper, we propose Faster DAN, a two-step strategy to speed up the recognition process at prediction time: the model predicts the first character of each text line in the document, and then completes all the text lines in parallel through multi-target queries and a specific document positional encoding scheme. Faster DAN reaches competitive results compared to standard DAN, while being at least 4 times faster on whole single-page and double-page images of the RIMES 2009, READ 2016 and MAURDOR datasets. Source code and trained model weights are available at https://github.com/FactoDeepLearning/FasterDAN.
Towards End-to-end Handwritten Document Recognition
Sep 30, 2022
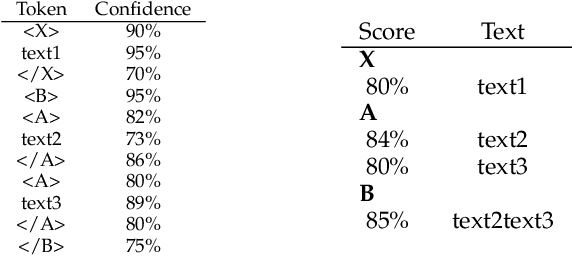
Handwritten text recognition has been widely studied in the last decades for its numerous applications. Nowadays, the state-of-the-art approach consists in a three-step process. The document is segmented into text lines, which are then ordered and recognized. However, this three-step approach has many drawbacks. The three steps are treated independently whereas they are closely related. Errors accumulate from one step to the other. The ordering step is based on heuristic rules which prevent its use for documents with a complex layouts or for heterogeneous documents. The need for additional physical segmentation annotations for training the segmentation stage is inherent to this approach. In this thesis, we propose to tackle these issues by performing the handwritten text recognition of whole document in an end-to-end way. To this aim, we gradually increase the difficulty of the recognition task, moving from isolated lines to paragraphs, and then to whole documents. We proposed an approach at the line level, based on a fully convolutional network, in order to design a first generic feature extraction step for the handwriting recognition task. Based on this preliminary work, we studied two different approaches to recognize handwritten paragraphs. We reached state-of-the-art results at paragraph level on the RIMES 2011, IAM and READ 2016 datasets and outperformed the line-level state of the art on these datasets. We finally proposed the first end-to-end approach dedicated to the recognition of both text and layout, at document level. Characters and layout tokens are sequentially predicted following a learned reading order. We proposed two new metrics we used to evaluate this task on the RIMES 2009 and READ 2016 dataset, at page level and double-page level.
DAN: a Segmentation-free Document Attention Network for Handwritten Document Recognition
Apr 07, 2022

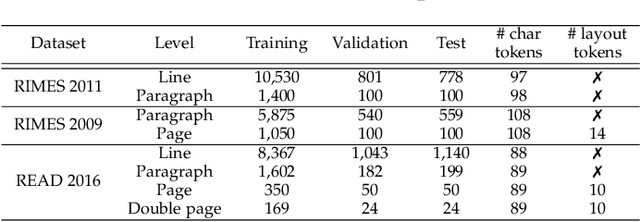
Unconstrained handwritten text recognition is a challenging computer vision task. It is traditionally handled by a two-step approach combining line segmentation followed by text line recognition. For the first time, we propose an end-to-end segmentation-free architecture for the task of handwritten document recognition: the Document Attention Network. In addition to the text recognition, the model is trained to label text parts using begin and end tags in an XML-like fashion. This model is made up of an FCN encoder for feature extraction and a stack of transformer decoder layers for a recurrent token-by-token prediction process. It takes whole text documents as input and sequentially outputs characters, as well as logical layout tokens. Contrary to the existing segmentation-based approaches, the model is trained without using any segmentation label. We achieve competitive results on the READ 2016 dataset at page level, as well as double-page level with a CER of 3.53% and 3.69%, respectively. We also provide results for the RIMES 2009 dataset at page level, reaching 4.54% of CER. We provide all source code and pre-trained model weights at https://github.com/FactoDeepLearning/DAN.
SPAN: a Simple Predict & Align Network for Handwritten Paragraph Recognition
Feb 17, 2021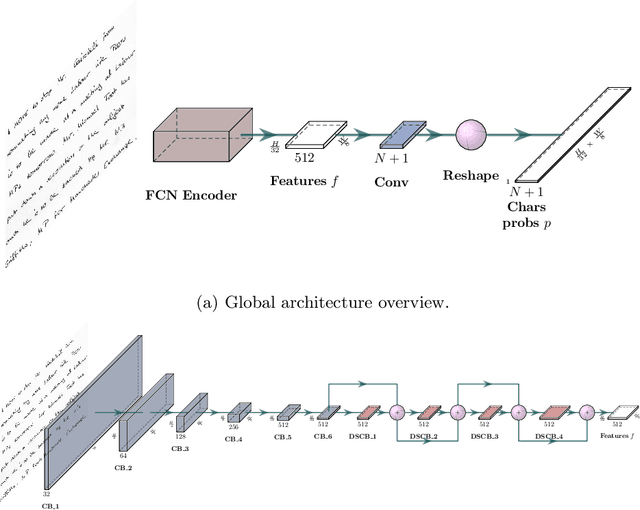
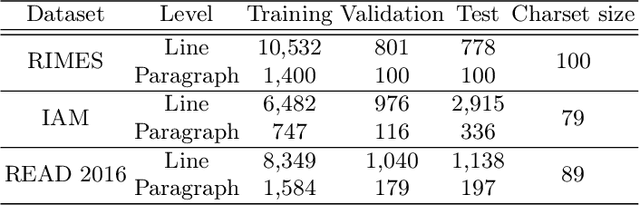
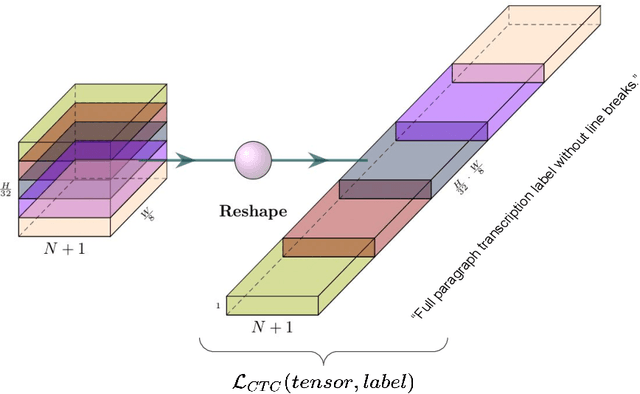
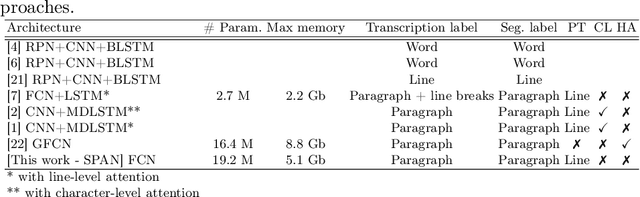
Unconstrained handwriting recognition is an essential task in document analysis. It is usually carried out in two steps. First, the document is segmented into text lines. Second, an Optical Character Recognition model is applied on these line images. We propose the Simple Predict & Align Network: an end-to-end recurrence-free Fully Convolutional Network performing OCR at paragraph level without any prior segmentation stage. The framework is as simple as the one used for the recognition of isolated lines and we achieve competitive results on three popular datasets: RIMES, IAM and READ 2016. The proposed model does not require any dataset adaptation, it can be trained from scratch, without segmentation labels, and it does not require line breaks in the transcription labels. Our code and trained model weights are available at https://github.com/FactoDeepLearning/SPAN.
Recurrence-free unconstrained handwritten text recognition using gated fully convolutional network
Dec 09, 2020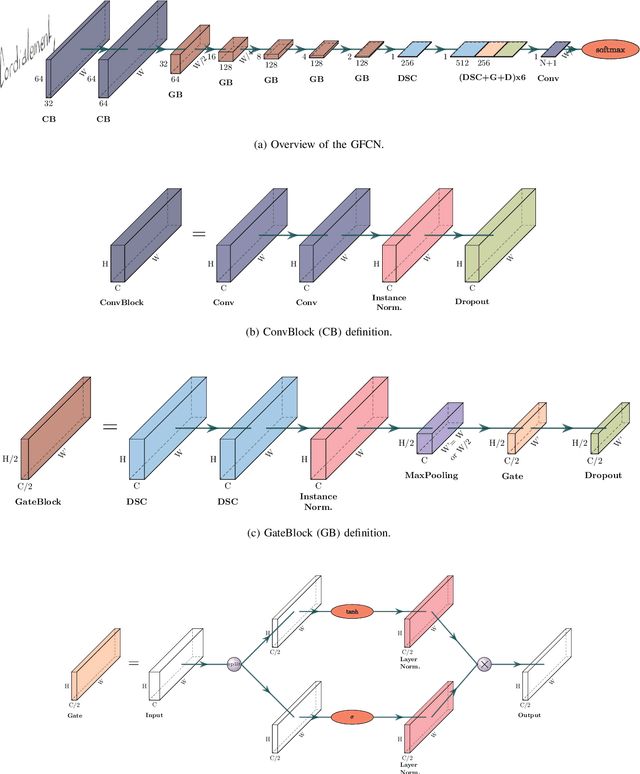
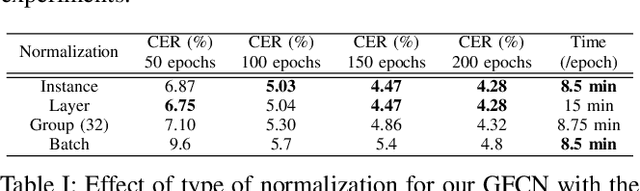


Unconstrained handwritten text recognition is a major step in most document analysis tasks. This is generally processed by deep recurrent neural networks and more specifically with the use of Long Short-Term Memory cells. The main drawbacks of these components are the large number of parameters involved and their sequential execution during training and prediction. One alternative solution to using LSTM cells is to compensate the long time memory loss with an heavy use of convolutional layers whose operations can be executed in parallel and which imply fewer parameters. In this paper we present a Gated Fully Convolutional Network architecture that is a recurrence-free alternative to the well-known CNN+LSTM architectures. Our model is trained with the CTC loss and shows competitive results on both the RIMES and IAM datasets. We release all code to enable reproduction of our experiments: https://github.com/FactoDeepLearning/LinePytorchOCR.