 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-DAN: towards an efficient prediction strategy for page-level handwritten text recognition
Paper and Code
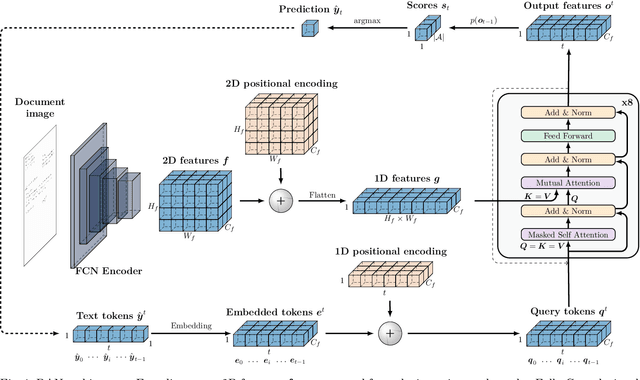
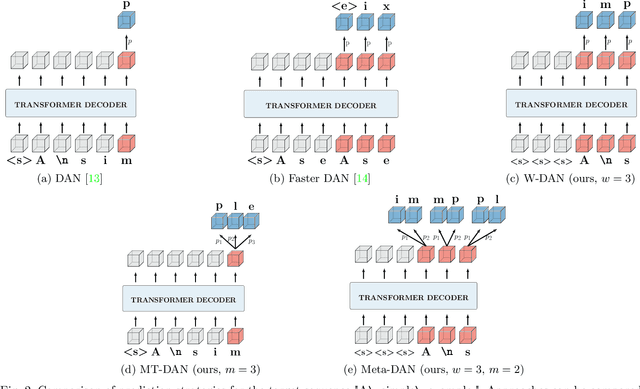
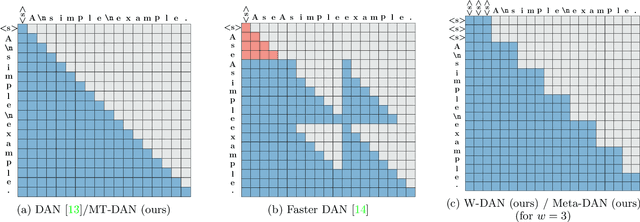
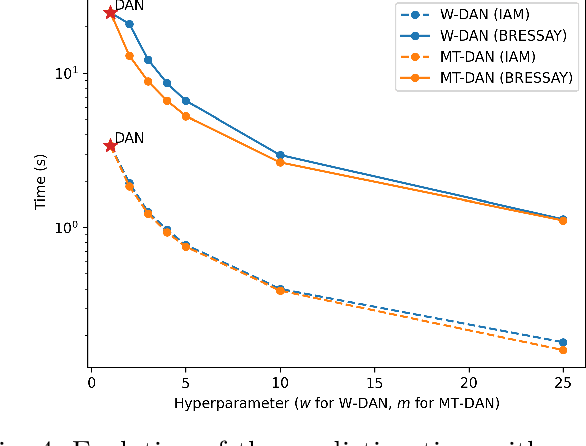
Recent advances in text recognition led to a paradigm shift for page-level recognition, from multi-step segmentation-based approaches to end-to-end attention-based ones. However, the na\"ive character-level autoregressive decoding process results in long prediction times: it requires several seconds to process a single page image on a modern GPU. We propose the Meta Document Attention Network (Meta-DAN) as a novel decoding strategy to reduce the prediction time while enabling a better context modeling. It relies on two main components: windowed queries, to process several transformer queries altogether, enlarging the context modeling with near future; and multi-token predictions, whose goal is to predict several tokens per query instead of only the next one. We evaluate the proposed approach on 10 full-page handwritten datasets and demonstrate state-of-the-art results on average in terms of character error rate. Source code and weights of trained models are available at https://github.com/FactoDeepLearning/meta_dan.