 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAN: a Segmentation-free Document Attention Network for Handwritten Document Recognition
Paper and Code

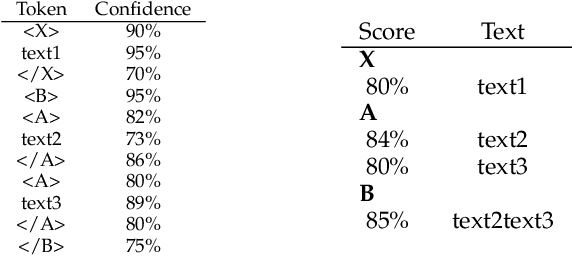

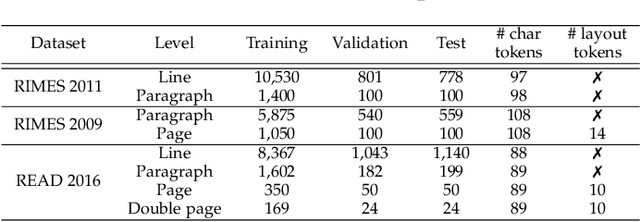
Unconstrained handwritten text recognition is a challenging computer vision task. It is traditionally handled by a two-step approach combining line segmentation followed by text line recognition. For the first time, we propose an end-to-end segmentation-free architecture for the task of handwritten document recognition: the Document Attention Network. In addition to the text recognition, the model is trained to label text parts using begin and end tags in an XML-like fashion. This model is made up of an FCN encoder for feature extraction and a stack of transformer decoder layers for a recurrent token-by-token prediction process. It takes whole text documents as input and sequentially outputs characters, as well as logical layout tokens. Contrary to the existing segmentation-based approaches, the model is trained without using any segmentation label. We achieve competitive results on the READ 2016 dataset at page level, as well as double-page level with a CER of 3.53% and 3.69%, respectively. We also provide results for the RIMES 2009 dataset at page level, reaching 4.54% of CER. We provide all source code and pre-trained model weights at https://github.com/FactoDeepLearning/DAN.