 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection in the DCT Domain: is Luminance the Solution?
Jun 22, 2020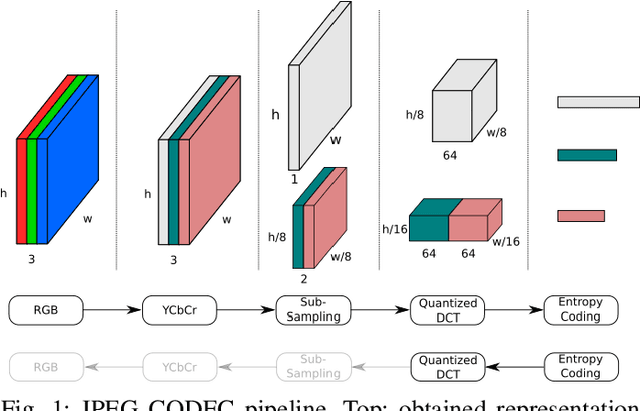
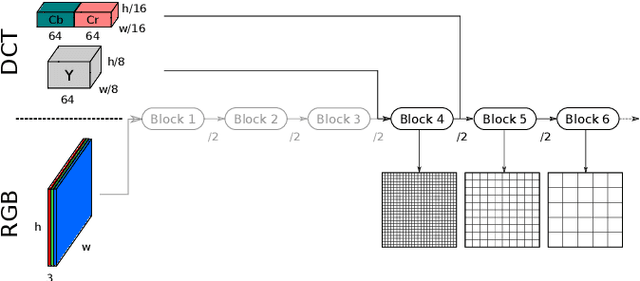
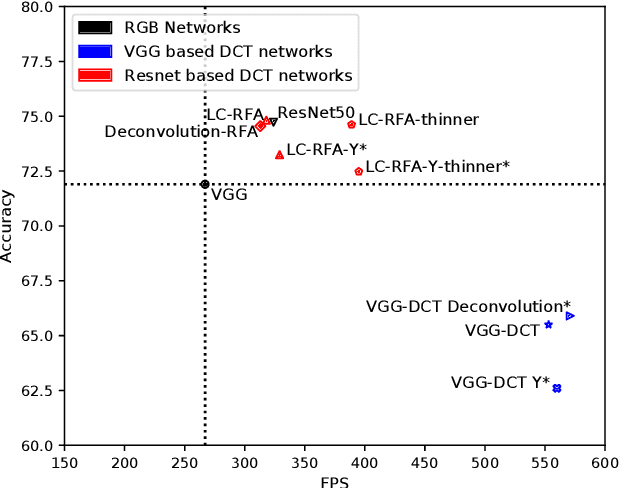
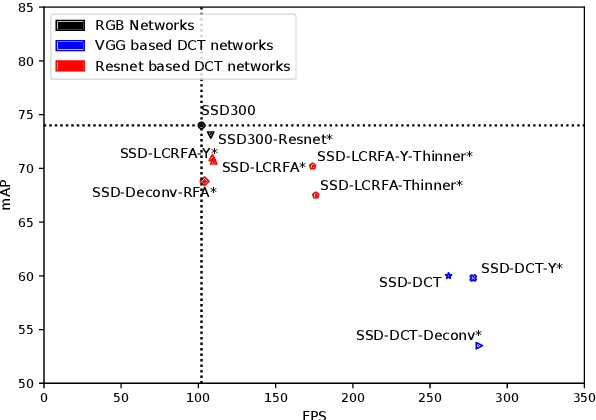
Object detection in images has reached unprecedented performances. The state-of-the-art methods rely on deep architectures that extract salient features and predict bounding boxes enclosing the objects of interest. These methods essentially run on RGB images. However, the RGB images are often compressed by the acquisition devices for storage purpose and transfer efficiency. Hence, their decompression is required for object detectors. To gain in efficiency, this paper proposes to take advantage of the compressed representation of images to carry out object detection usable in constrained resources conditions. Specifically, we focus on JPEG images and propose a thorough analysis of detection architectures newly designed in regard of the peculiarities of the JPEG norm. This leads to a $\times 1.7$ speed up in comparison with a standard RGB-based architecture, while only reducing the detection performance by 5.5%. Additionally, our empirical findings demonstrate that only part of the compressed JPEG information, namely the luminance component, may be required to match detection accuracy of the full input methods.
Fast object detection in compressed JPEG Images
Apr 16, 2019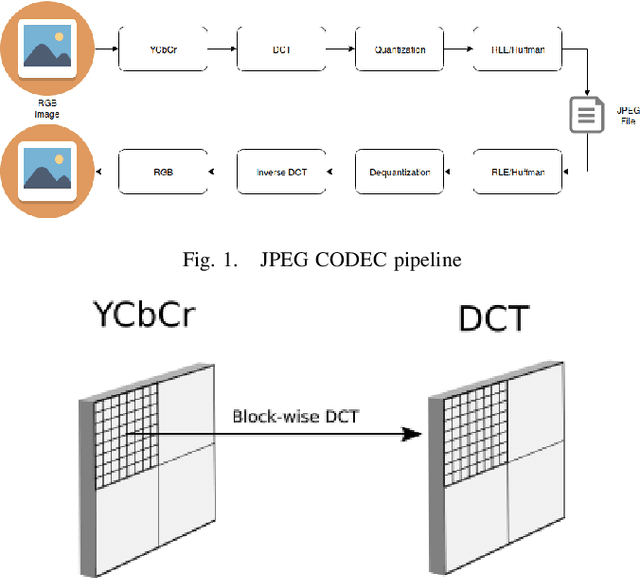

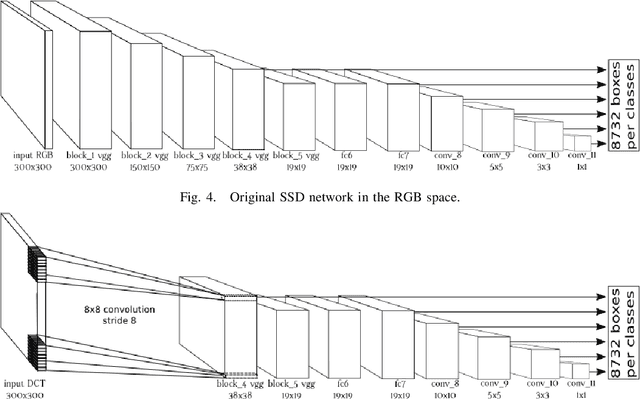
Object detection in still images has drawn a lot of attention over past few years, and with the advent of Deep Learning impressive performances have been achieved with numerous industrial applications. Most of these deep learning models rely on RGB images to localize and identify objects in the image. However in some application scenarii, images are compressed either for storage savings or fast transmission. Therefore a time consuming image decompression step is compulsory in order to apply the aforementioned deep models. To alleviate this drawback, we propose a fast deep architecture for object detection in JPEG images, one of the most widespread compression format. We train a neural network to detect objects based on the blockwise DCT (discrete cosine transform) coefficients {issued from} the JPEG compression algorithm. We modify the well-known Single Shot multibox Detector (SSD) by replacing its first layers with one convolutional layer dedicated to process the DCT inputs. Experimental evaluations on PASCAL VOC and industrial dataset comprising images of road traffic surveillance show that the model is about $2\times$ faster than regular SSD with promising detection performances. To the best of our knowledge, this paper is the first to address detection in compressed JPEG images.