 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Specialized Software-Assistant ChatBot with Graph-Based Retrieval-Augmented Generation
Nov 07, 2025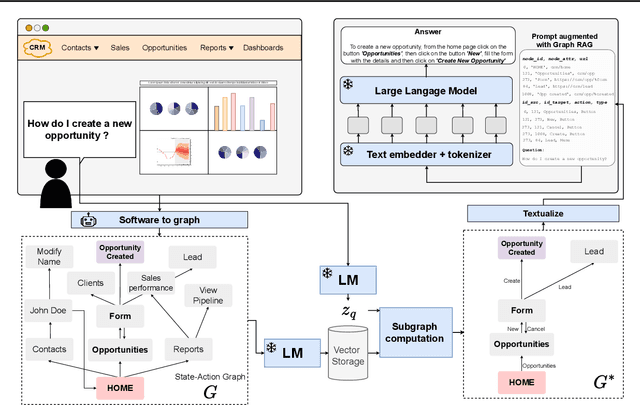



Digital Adoption Platforms (DAPs) have become essential tools for helping employees navigate complex enterprise software such as CRM, ERP, or HRMS systems. Companies like LemonLearning have shown how digital guidance can reduce training costs and accelerate onboarding. However, building and maintaining these interactive guides still requires extensive manual effort. Leveraging Large Language Models as virtual assistants is an appealing alternative, yet without a structured understanding of the target software, LLMs often hallucinate and produce unreliable answers. Moreover, most production-grade LLMs are black-box APIs, making fine-tuning impractical due to the lack of access to model weights. In this work, we introduce a Graph-based Retrieval-Augmented Generation framework that automatically converts enterprise web applications into state-action knowledge graphs, enabling LLMs to generate grounded and context-aware assistance. The framework was co-developed with the AI enterprise RAKAM, in collaboration with Lemon Learning. We detail the engineering pipeline that extracts and structures software interfaces, the design of the graph-based retrieval process, and the integration of our approach into production DAP workflows. Finally, we discuss scalability, robustness, and deployment lessons learned from industrial use cases.
ViLU: Learning Vision-Language Uncertainties for Failure Prediction
Jul 10, 2025Reliable Uncertainty Quantification (UQ) and failure prediction remain open challenges for Vision-Language Models (VLMs). We introduce ViLU, a new Vision-Language Uncertainty quantification framework that contextualizes uncertainty estimates by leveraging all task-relevant textual representations. ViLU constructs an uncertainty-aware multi-modal representation by integrating the visual embedding, the predicted textual embedding, and an image-conditioned textual representation via cross-attention. Unlike traditional UQ methods based on loss prediction, ViLU trains an uncertainty predictor as a binary classifier to distinguish correct from incorrect predictions using a weighted binary cross-entropy loss, making it loss-agnostic. In particular, our proposed approach is well-suited for post-hoc settings, where only vision and text embeddings are available without direct access to the model itself. Extensive experiments on diverse datasets show the significant gains of our method compared to state-of-the-art failure prediction methods. We apply our method to standard classification datasets, such as ImageNet-1k, as well as large-scale image-caption datasets like CC12M and LAION-400M. Ablation studies highlight the critical role of our architecture and training in achieving effective uncertainty quantification. Our code is publicly available and can be found here: https://github.com/ykrmm/ViLU.
Supra-Laplacian Encoding for Transformer on Dynamic Graphs
Sep 26, 2024



Fully connected Graph Transformers (GT) have rapidly become prominent in the static graph community as an alternative to Message-Passing models, which suffer from a lack of expressivity, oversquashing, and under-reaching. However, in a dynamic context, by interconnecting all nodes at multiple snapshots with self-attention, GT loose both structural and temporal information. In this work, we introduce Supra-LAplacian encoding for spatio-temporal TransformErs (SLATE), a new spatio-temporal encoding to leverage the GT architecture while keeping spatio-temporal information. Specifically, we transform Discrete Time Dynamic Graphs into multi-layer graphs and take advantage of the spectral properties of their associated supra-Laplacian matrix. Our second contribution explicitly model nodes' pairwise relationships with a cross-attention mechanism, providing an accurate edge representation for dynamic link prediction. SLATE outperforms numerous state-of-the-art methods based on Message-Passing Graph Neural Networks combined with recurrent models (e.g LSTM), and Dynamic Graph Transformers, on 9 datasets. Code and instructions to reproduce our results will be open-sourced.
Temporal receptive field in dynamic graph learning: A comprehensive analysis
Jul 19, 2024



Dynamic link prediction is a critical task in the analysis of evolving networks, with applications ranging from recommender systems to economic exchanges. However, the concept of the temporal receptive field, which refers to the temporal context that models use for making predictions, has been largely overlooked and insufficiently analyzed in existing research. In this study, we present a comprehensive analysis of the temporal receptive field in dynamic graph learning. By examining multiple datasets and models, we formalize the role of temporal receptive field and highlight their crucial influence on predictive accuracy. Our results demonstrate that appropriately chosen temporal receptive field can significantly enhance model performance, while for some models, overly large windows may introduce noise and reduce accuracy. We conduct extensive benchmarking to validate our findings, ensuring that all experiments are fully reproducible. Code is available at https://github.com/ykrmm/BenchmarkTW .
ITEM: Improving Training and Evaluation of Message-Passing based GNNs for top-k recommendation
Jul 03, 2024



Graph Neural Networks (GNNs), especially message-passing-based models, have become prominent in top-k recommendation tasks, outperforming matrix factorization models due to their ability to efficiently aggregate information from a broader context. Although GNNs are evaluated with ranking-based metrics, e.g NDCG@k and Recall@k, they remain largely trained with proxy losses, e.g the BPR loss. In this work we explore the use of ranking loss functions to directly optimize the evaluation metrics, an area not extensively investigated in the GNN community for collaborative filtering. We take advantage of smooth approximations of the rank to facilitate end-to-end training of GNNs and propose a Personalized PageRank-based negative sampling strategy tailored for ranking loss functions. Moreover, we extend the evaluation of GNN models for top-k recommendation tasks with an inductive user-centric protocol, providing a more accurate reflection of real-world applications. Our proposed method significantly outperforms the standard BPR loss and more advanced losses across four datasets and four recent GNN architectures while also exhibiting faster training. Demonstrating the potential of ranking loss functions in improving GNN training for collaborative filtering tasks.