 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLU: Learning Vision-Language Uncertainties for Failure Prediction
Jul 10, 2025Reliable Uncertainty Quantification (UQ) and failure prediction remain open challenges for Vision-Language Models (VLMs). We introduce ViLU, a new Vision-Language Uncertainty quantification framework that contextualizes uncertainty estimates by leveraging all task-relevant textual representations. ViLU constructs an uncertainty-aware multi-modal representation by integrating the visual embedding, the predicted textual embedding, and an image-conditioned textual representation via cross-attention. Unlike traditional UQ methods based on loss prediction, ViLU trains an uncertainty predictor as a binary classifier to distinguish correct from incorrect predictions using a weighted binary cross-entropy loss, making it loss-agnostic. In particular, our proposed approach is well-suited for post-hoc settings, where only vision and text embeddings are available without direct access to the model itself. Extensive experiments on diverse datasets show the significant gains of our method compared to state-of-the-art failure prediction methods. We apply our method to standard classification datasets, such as ImageNet-1k, as well as large-scale image-caption datasets like CC12M and LAION-400M. Ablation studies highlight the critical role of our architecture and training in achieving effective uncertainty quantification. Our code is publicly available and can be found here: https://github.com/ykrmm/ViLU.
Supra-Laplacian Encoding for Transformer on Dynamic Graphs
Sep 26, 2024



Fully connected Graph Transformers (GT) have rapidly become prominent in the static graph community as an alternative to Message-Passing models, which suffer from a lack of expressivity, oversquashing, and under-reaching. However, in a dynamic context, by interconnecting all nodes at multiple snapshots with self-attention, GT loose both structural and temporal information. In this work, we introduce Supra-LAplacian encoding for spatio-temporal TransformErs (SLATE), a new spatio-temporal encoding to leverage the GT architecture while keeping spatio-temporal information. Specifically, we transform Discrete Time Dynamic Graphs into multi-layer graphs and take advantage of the spectral properties of their associated supra-Laplacian matrix. Our second contribution explicitly model nodes' pairwise relationships with a cross-attention mechanism, providing an accurate edge representation for dynamic link prediction. SLATE outperforms numerous state-of-the-art methods based on Message-Passing Graph Neural Networks combined with recurrent models (e.g LSTM), and Dynamic Graph Transformers, on 9 datasets. Code and instructions to reproduce our results will be open-sourced.
GalLoP: Learning Global and Local Prompts for Vision-Language Models
Jul 01, 2024



Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs), e.g. CLIP, for few-shot image classification. Despite their success, most prompt learning methods trade-off between classification accuracy and robustness, e.g. in domain generalization or out-of-distribution (OOD) detection. In this work, we introduce Global-Local Prompts (GalLoP), a new prompt learning method that learns multiple diverse prompts leveraging both global and local visual features. The training of the local prompts relies on local features with an enhanced vision-text alignment. To focus only on pertinent features, this local alignment is coupled with a sparsity strategy in the selection of the local features. We enforce diversity on the set of prompts using a new ``prompt dropout'' technique and a multiscale strategy on the local prompts. GalLoP outperforms previous prompt learning methods on accuracy on eleven datasets in different few shots settings and with various backbones. Furthermore, GalLoP shows strong robustness performances in both domain generalization and OOD detection, even outperforming dedicated OOD detection methods. Code and instructions to reproduce our results will be open-sourced.
Understanding the Double Descent Phenomenon in Deep Learning
Mar 15, 2024



Combining empirical risk minimization with capacity control is a classical strategy in machine learning when trying to control the generalization gap and avoid overfitting, as the model class capacity gets larger. Yet, in modern deep learning practice, very large over-parameterized models (e.g. neural networks) are optimized to fit perfectly the training data and still obtain great generalization performance. Past the interpolation point, increasing model complexity seems to actually lower the test error. In this tutorial, we explain the concept of double descent and its mechanisms. The first section sets the classical statistical learning framework and introduces the double descent phenomenon. By looking at a number of examples, section 2 introduces inductive biases that appear to have a key role in double descent by selecting, among the multiple interpolating solutions, a smooth empirical risk minimizer. Finally, section 3 explores the double descent with two linear models, and gives other points of view from recent related works.
Energy Correction Model in the Feature Space for Out-of-Distribution Detection
Mar 15, 2024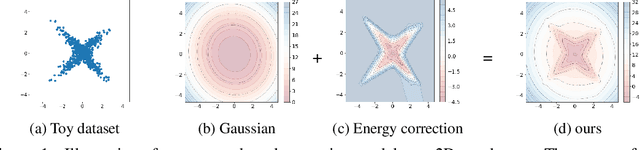

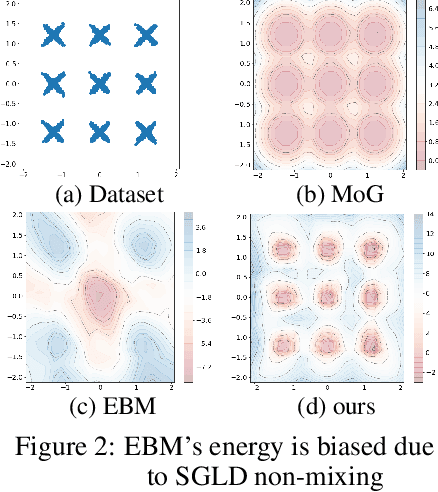

In this work, we study the out-of-distribution (OOD) detection problem through the use of the feature space of a pre-trained deep classifier. We show that learning the density of in-distribution (ID) features with an energy-based models (EBM) leads to competitive detection results. However, we found that the non-mixing of MCMC sampling during the EBM's training undermines its detection performance. To overcome this an energy-based correction of a mixture of class-conditional Gaussian distributions. We obtains favorable results when compared to a strong baseline like the KNN detector on the CIFAR-10/CIFAR-100 OOD detection benchmarks.
Hybrid Energy Based Model in the Feature Space for Out-of-Distribution Detection
Jun 01, 2023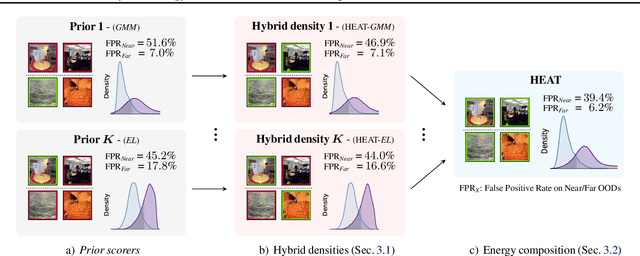


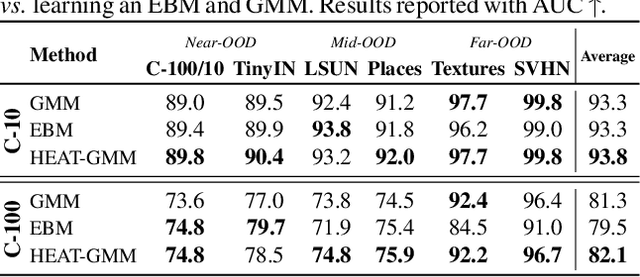
Out-of-distribution (OOD) detection is a critical requirement for the deployment of deep neural networks. This paper introduces the HEAT model, a new post-hoc OOD detection method estimating the density of in-distribution (ID) samples using hybrid energy-based models (EBM) in the feature space of a pre-trained backbone. HEAT complements prior density estimators of the ID density, e.g. parametric models like the Gaussian Mixture Model (GMM), to provide an accurate yet robust density estimation. A second contribution is to leverage the EBM framework to provide a unified density estimation and to compose several energy terms. Extensive experiments demonstrate the significance of the two contributions. HEAT sets new state-of-the-art OOD detection results on the CIFAR-10 / CIFAR-100 benchmark as well as on the large-scale Imagenet benchmark. The code is available at: https://github.com/MarcLafon/heatood.