 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Event-based Optical Marker Systems
Apr 29, 2025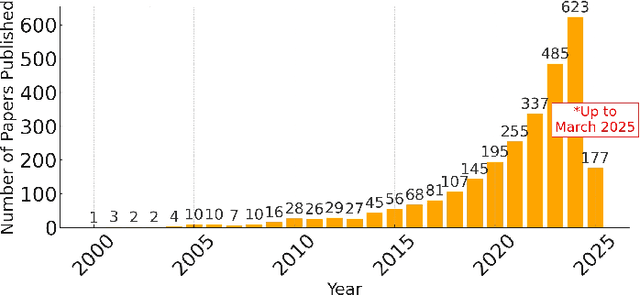
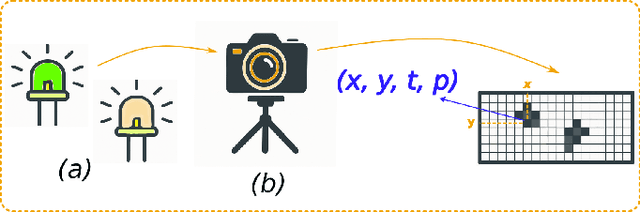
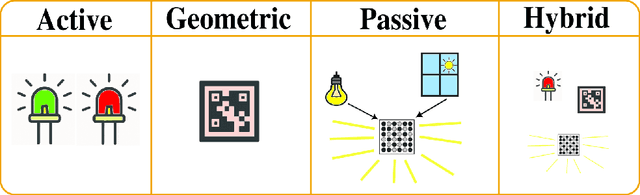
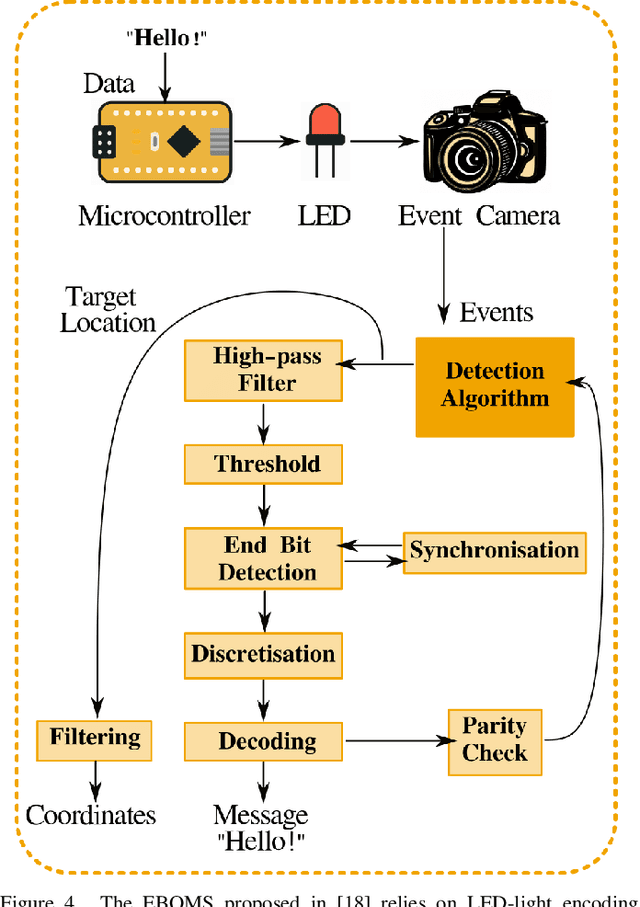
The advent of event-based cameras, with their low latency, high dynamic range, and reduced power consumption, marked a significant change in robotic vision and machine perception. In particular, the combination of these neuromorphic sensors with widely-available passive or active optical markers (e.g. AprilTags, arrays of blinking LEDs), has recently opened up a wide field of possibilities. This survey paper provides a comprehensive review on Event-Based Optical Marker Systems (EBOMS). We analyze the basic principles and technologies on which these systems are based, with a special focus on their asynchronous operation and robustness against adverse lighting conditions. We also describe the most relevant applications of EBOMS, including object detection and tracking, pose estimation, and optical communication. The article concludes with a discussion of possible future research directions in this rapidly-emerging and multidisciplinary field.
Pose Optimization for Autonomous Driving Datasets using Neural Rendering Models
Apr 22, 2025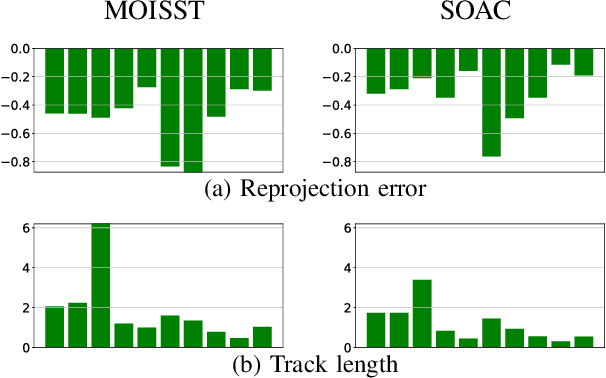
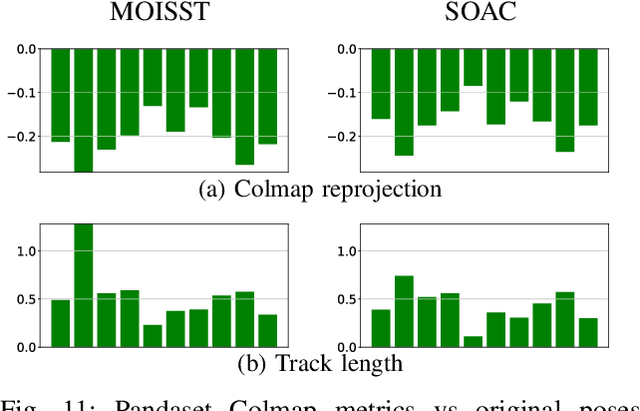
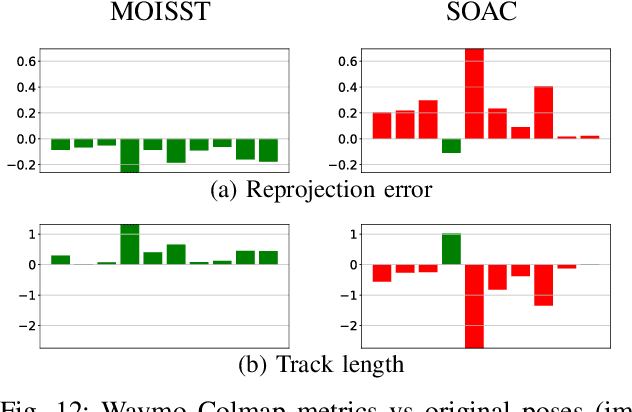
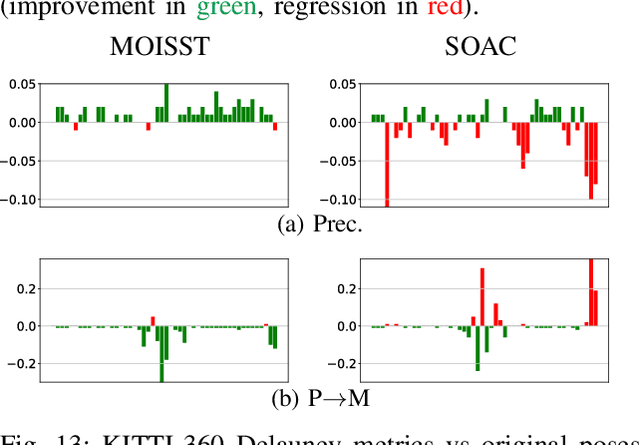
Autonomous driving systems rely on accurate perception and localization of the ego car to ensure safety and reliability in challenging real-world driving scenarios. Public datasets play a vital role in benchmarking and guiding advancement in research by providing standardized resources for model development and evaluation. However, potential inaccuracies in sensor calibration and vehicle poses within these datasets can lead to erroneous evaluations of downstream tasks, adversely impacting the reliability and performance of the autonomous systems. To address this challenge, we propose a robust optimization method based on Neural Radiance Fields (NeRF) to refine sensor poses and calibration parameters, enhancing the integrity of dataset benchmarks. To validate improvement in accuracy of our optimized poses without ground truth, we present a thorough evaluation process, relying on reprojection metrics, Novel View Synthesis rendering quality, and geometric alignment. We demonstrate that our method achieves significant improvements in sensor pose accuracy. By optimizing these critical parameters, our approach not only improves the utility of existing datasets but also paves the way for more reliable autonomous driving models. To foster continued progress in this field, we make the optimized sensor poses publicly available, providing a valuable resource for the research community.
3DGS-Calib: 3D Gaussian Splatting for Multimodal SpatioTemporal Calibration
Mar 18, 2024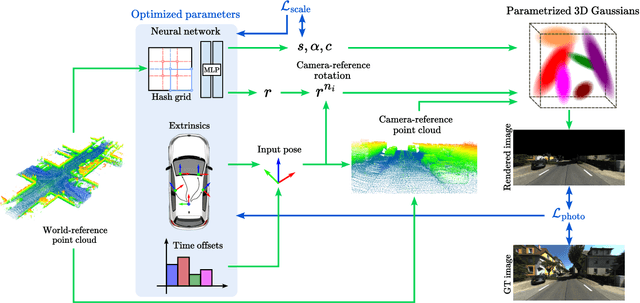
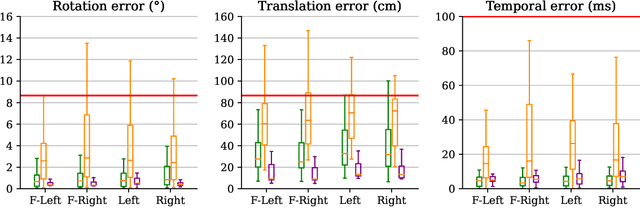
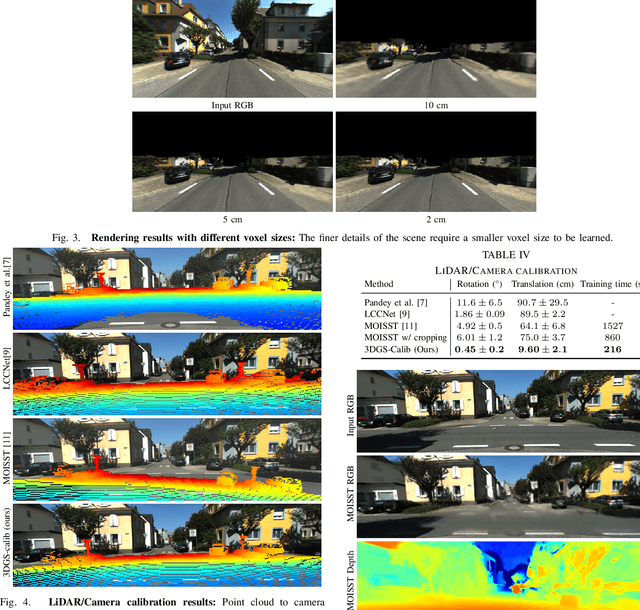
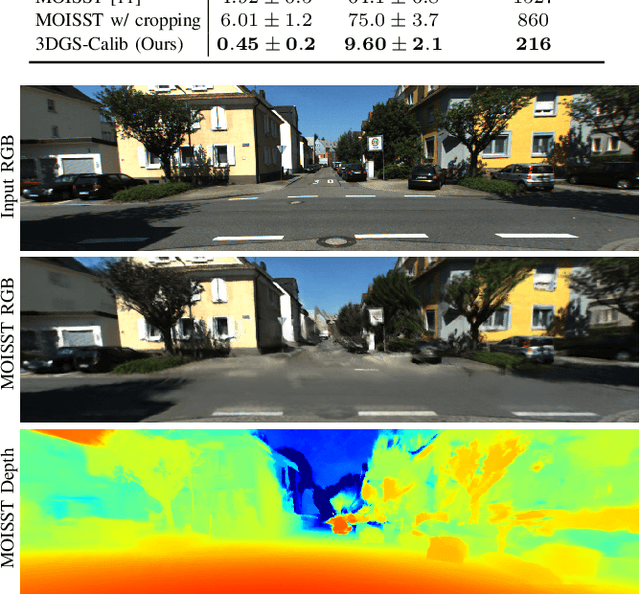
Reliable multimodal sensor fusion algorithms require accurate spatiotemporal calibration. Recently, targetless calibration techniques based on implicit neural representations have proven to provide precise and robust results. Nevertheless, such methods are inherently slow to train given the high computational overhead caused by the large number of sampled points required for volume rendering. With the recent introduction of 3D Gaussian Splatting as a faster alternative to implicit representation methods, we propose to leverage this new rendering approach to achieve faster multi-sensor calibration. We introduce 3DGS-Calib, a new calibration method that relies on the speed and rendering accuracy of 3D Gaussian Splatting to achieve multimodal spatiotemporal calibration that is accurate, robust, and with a substantial speed-up compared to methods relying on implicit neural representations. We demonstrate the superiority of our proposal with experimental results on sequences from KITTI-360, a widely used driving dataset.
SOAC: Spatio-Temporal Overlap-Aware Multi-Sensor Calibration using Neural Radiance Fields
Nov 27, 2023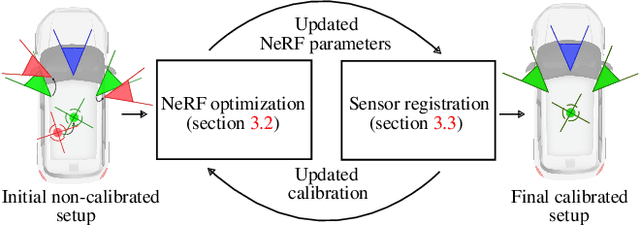

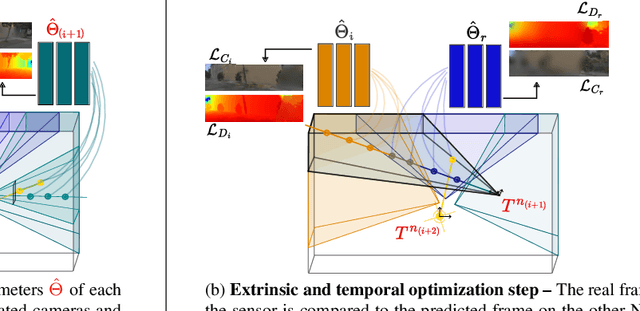

In rapidly-evolving domains such as autonomous driving, the use of multiple sensors with different modalities is crucial to ensure high operational precision and stability. To correctly exploit the provided information by each sensor in a single common frame, it is essential for these sensors to be accurately calibrated. In this paper, we leverage the ability of Neural Radiance Fields (NeRF) to represent different sensors modalities in a common volumetric representation to achieve robust and accurate spatio-temporal sensor calibration. By designing a partitioning approach based on the visible part of the scene for each sensor, we formulate the calibration problem using only the overlapping areas. This strategy results in a more robust and accurate calibration that is less prone to failure. We demonstrate that our approach works on outdoor urban scenes by validating it on multiple established driving datasets. Results show that our method is able to get better accuracy and robustness compared to existing methods.
MOISST: Multi-modal Optimization of Implicit Scene for SpatioTemporal calibration
Mar 07, 2023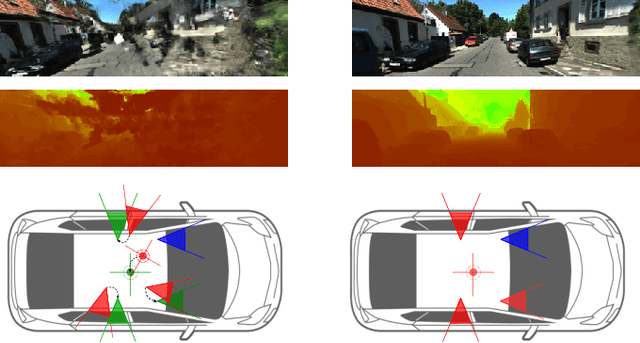
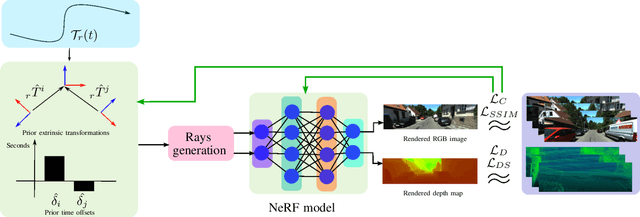

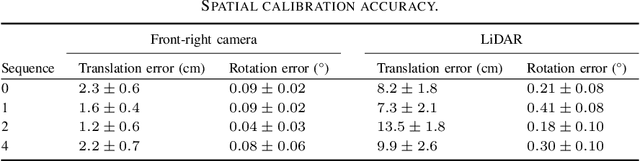
With the recent advances in autonomous driving and the decreasing cost of LiDARs, the use of multi-modal sensor systems is on the rise. However, in order to make use of the information provided by a variety of complimentary sensors, it is necessary to accurately calibrate them. We take advantage of recent advances in computer graphics and implicit volumetric scene representation to tackle the problem of multi-sensor spatial and temporal calibration. Thanks to a new formulation of the implicit model optimization, we are able to jointly optimize calibration parameters along with scene representation based on radiometric and geometric measurements. Our method enables accurate and robust calibration from data captured in uncontrolled and unstructured urban environments, making our solution more scalable than existing calibration solutions. We demonstrate the accuracy and robustness of our method in urban scenes typically encountered in autonomous driving scenarios.
SynWoodScape: Synthetic Surround-view Fisheye Camera Dataset for Autonomous Driving
Mar 09, 2022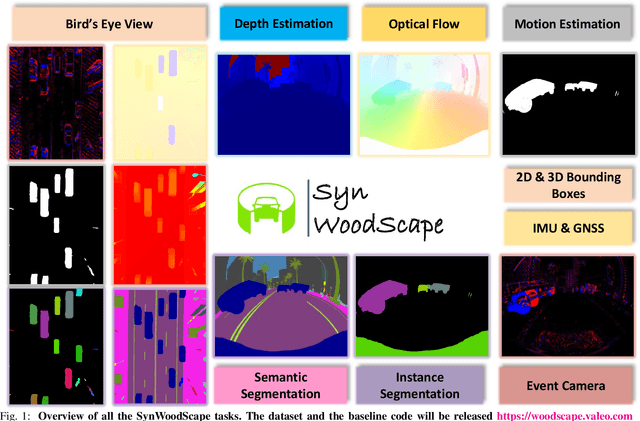
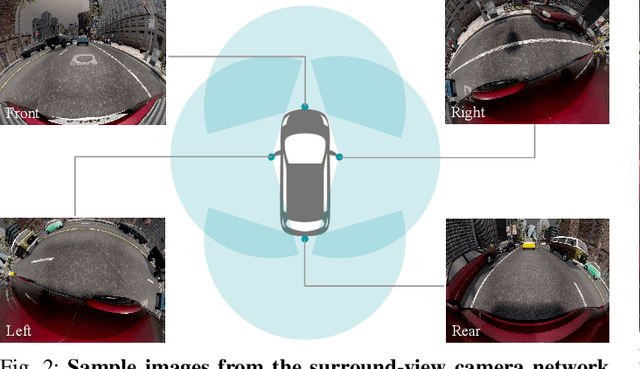
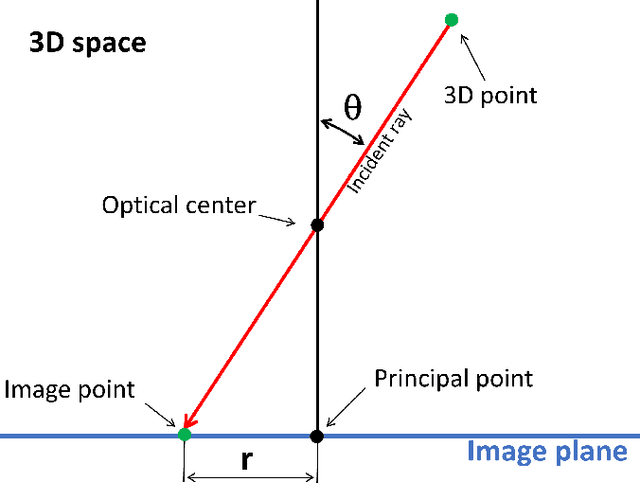
Surround-view cameras are a primary sensor for automated driving, used for near field perception. It is one of the most commonly used sensors in commercial vehicles. Four fisheye cameras with a 190{\deg} field of view cover the 360{\deg} around the vehicle. Due to its high radial distortion, the standard algorithms do not extend easily. Previously, we released the first public fisheye surround-view dataset named WoodScape. In this work, we release a synthetic version of the surround-view dataset, covering many of its weaknesses and extending it. Firstly, it is not possible to obtain ground truth for pixel-wise optical flow and depth. Secondly, WoodScape did not have all four cameras simultaneously in order to sample diverse frames. However, this means that multi-camera algorithms cannot be designed, which is enabled in the new dataset. We implemented surround-view fisheye geometric projections in CARLA Simulator matching WoodScape's configuration and created SynWoodScape. We release 80k images from the synthetic dataset with annotations for 10+ tasks. We also release the baseline code and supporting scripts.
N-QGN: Navigation Map from a Monocular Camera using Quadtree Generating Networks
Feb 24, 2022
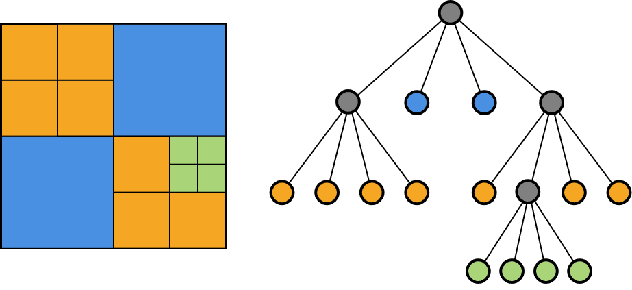
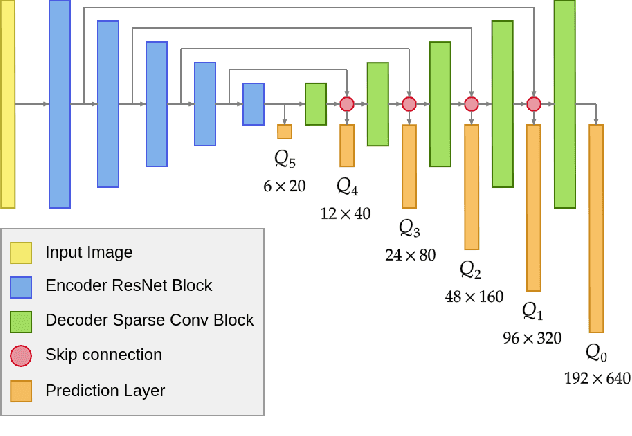
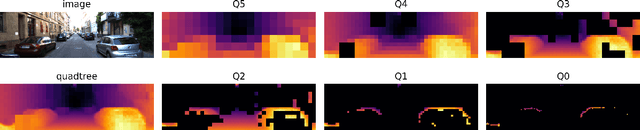
Monocular depth estimation has been a popular area of research for several years, especially since self-supervised networks have shown increasingly good results in bridging the gap with supervised and stereo methods. However, these approaches focus their interest on dense 3D reconstruction and sometimes on tiny details that are superfluous for autonomous navigation. In this paper, we propose to address this issue by estimating the navigation map under a quadtree representation. The objective is to create an adaptive depth map prediction that only extract details that are essential for the obstacle avoidance. Other 3D space which leaves large room for navigation will be provided with approximate distance. Experiment on KITTI dataset shows that our method can significantly reduce the number of output information without major loss of accuracy.
Breaking the Limits of Message Passing Graph Neural Networks
Jun 08, 2021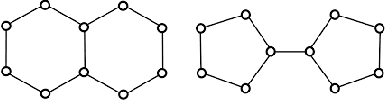
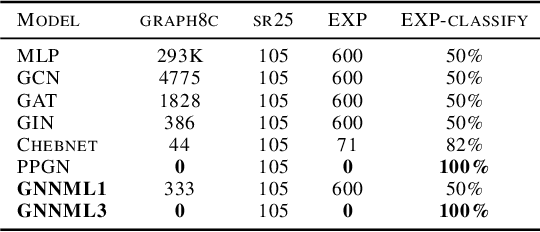
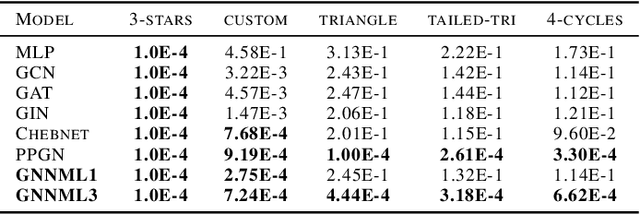
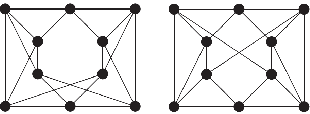
Since the Message Passing (Graph) Neural Networks (MPNNs) have a linear complexity with respect to the number of nodes when applied to sparse graphs, they have been widely implemented and still raise a lot of interest even though their theoretical expressive power is limited to the first order Weisfeiler-Lehman test (1-WL). In this paper, we show that if the graph convolution supports are designed in spectral-domain by a non-linear custom function of eigenvalues and masked with an arbitrary large receptive field, the MPNN is theoretically more powerful than the 1-WL test and experimentally as powerful as a 3-WL existing models, while remaining spatially localized. Moreover, by designing custom filter functions, outputs can have various frequency components that allow the convolution process to learn different relationships between a given input graph signal and its associated properties. So far, the best 3-WL equivalent graph neural networks have a computational complexity in $\mathcal{O}(n^3)$ with memory usage in $\mathcal{O}(n^2)$, consider non-local update mechanism and do not provide the spectral richness of output profile. The proposed method overcomes all these aforementioned problems and reaches state-of-the-art results in many downstream tasks.
LiDAR point clouds correction acquired from a moving car based on CAN-bus data
Jun 19, 2017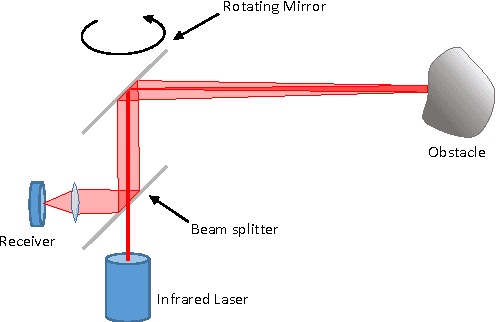
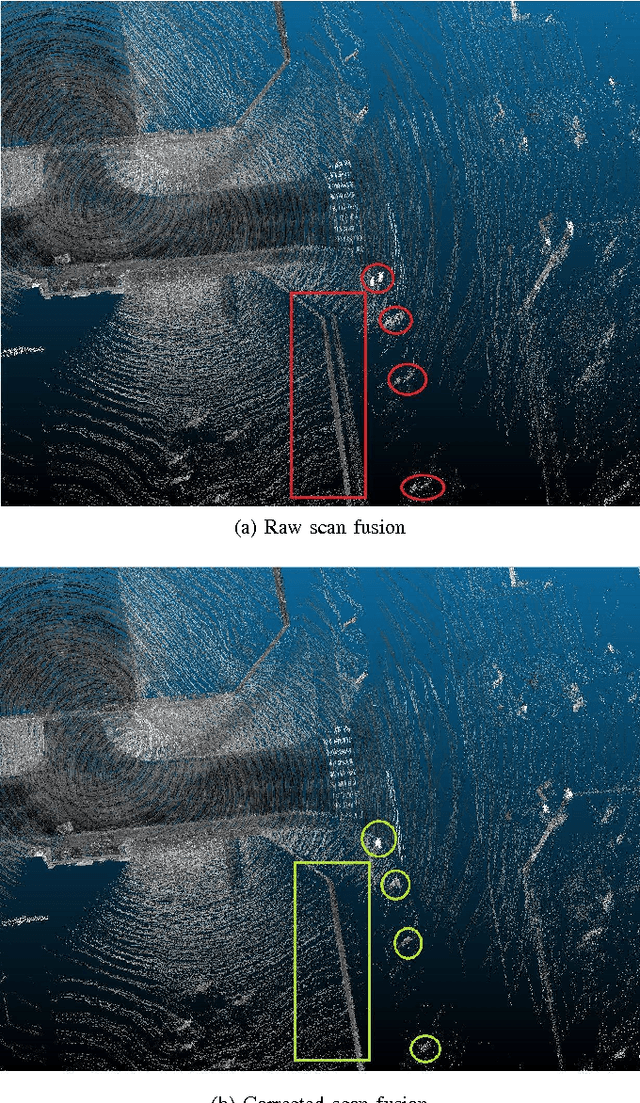
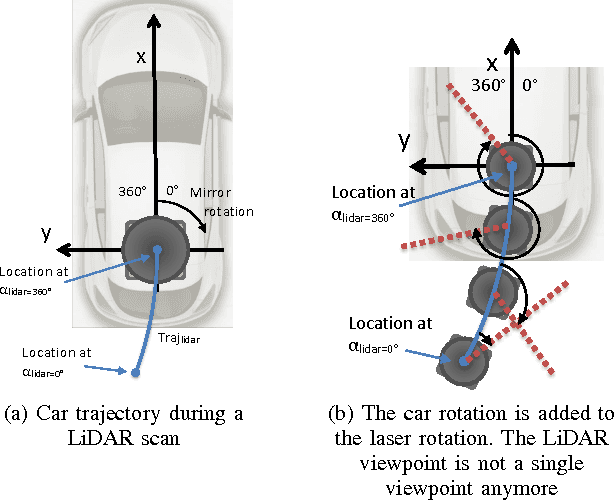
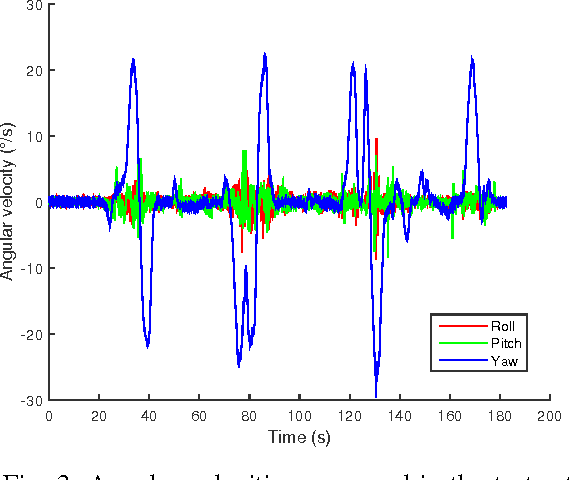
In this paper, we investigate the impact of different kind of car trajectories on LiDAR scans. In fact, LiDAR scanning speeds are considerably slower than car speeds introducing distortions. We propose a method to overcome this issue as well as new metrics based on CAN bus data. Our results suggest that the vehicle trajectory should be taken into account when building 3D large-scale maps from a LiDAR mounted on a moving vehicle.