 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmodal Optical Flow
Nov 13, 2023



Optical flow estimation is very challenging in situations with transparent or occluded objects. In this work, we address these challenges at the task level by introducing Amodal Optical Flow, which integrates optical flow with amodal perception. Instead of only representing the visible regions, we define amodal optical flow as a multi-layered pixel-level motion field that encompasses both visible and occluded regions of the scene. To facilitate research on this new task, we extend the AmodalSynthDrive dataset to include pixel-level labels for amodal optical flow estimation. We present several strong baselines, along with the Amodal Flow Quality metric to quantify the performance in an interpretable manner. Furthermore, we propose the novel AmodalFlowNet as an initial step toward addressing this task. AmodalFlowNet consists of a transformer-based cost-volume encoder paired with a recurrent transformer decoder which facilitates recurrent hierarchical feature propagation and amodal semantic grounding. We demonstrate the tractability of amodal optical flow in extensive experiments and show its utility for downstream tasks such as panoptic tracking. We make the dataset, code, and trained models publicly available at http://amodal-flow.cs.uni-freiburg.de.
AmodalSynthDrive: A Synthetic Amodal Perception Dataset for Autonomous Driving
Sep 12, 2023



Unlike humans, who can effortlessly estimate the entirety of objects even when partially occluded, modern computer vision algorithms still find this aspect extremely challenging. Leveraging this amodal perception for autonomous driving remains largely untapped due to the lack of suitable datasets. The curation of these datasets is primarily hindered by significant annotation costs and mitigating annotator subjectivity in accurately labeling occluded regions. To address these limitations, we introduce AmodalSynthDrive, a synthetic multi-task multi-modal amodal perception dataset. The dataset provides multi-view camera images, 3D bounding boxes, LiDAR data, and odometry for 150 driving sequences with over 1M object annotations in diverse traffic, weather, and lighting conditions. AmodalSynthDrive supports multiple amodal scene understanding tasks including the introduced amodal depth estimation for enhanced spatial understanding. We evaluate several baselines for each of these tasks to illustrate the challenges and set up public benchmarking servers. The dataset is available at http://amodalsynthdrive.cs.uni-freiburg.de.
SynWoodScape: Synthetic Surround-view Fisheye Camera Dataset for Autonomous Driving
Mar 09, 2022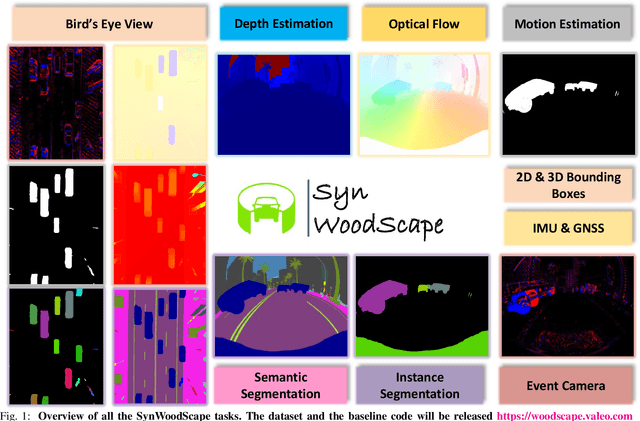
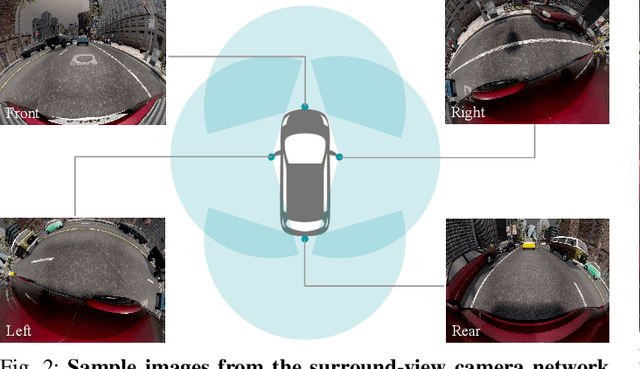
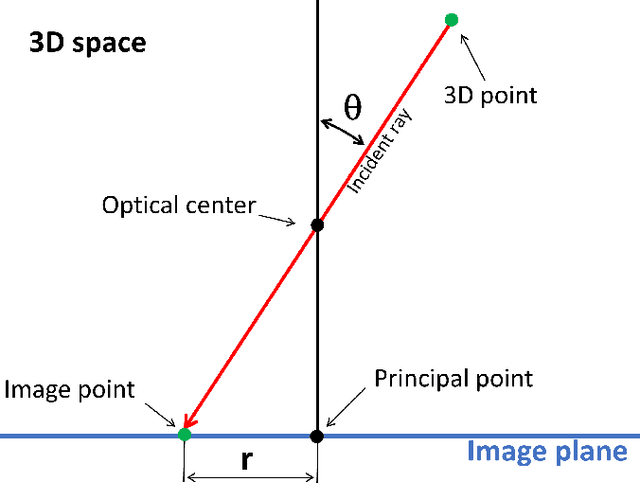
Surround-view cameras are a primary sensor for automated driving, used for near field perception. It is one of the most commonly used sensors in commercial vehicles. Four fisheye cameras with a 190{\deg} field of view cover the 360{\deg} around the vehicle. Due to its high radial distortion, the standard algorithms do not extend easily. Previously, we released the first public fisheye surround-view dataset named WoodScape. In this work, we release a synthetic version of the surround-view dataset, covering many of its weaknesses and extending it. Firstly, it is not possible to obtain ground truth for pixel-wise optical flow and depth. Secondly, WoodScape did not have all four cameras simultaneously in order to sample diverse frames. However, this means that multi-camera algorithms cannot be designed, which is enabled in the new dataset. We implemented surround-view fisheye geometric projections in CARLA Simulator matching WoodScape's configuration and created SynWoodScape. We release 80k images from the synthetic dataset with annotations for 10+ tasks. We also release the baseline code and supporting scripts.