 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Gaussian Splatting for 4D Panoptic Occupancy Tracking
Feb 26, 2026Capturing 4D spatiotemporal surroundings is crucial for the safe and reliable operation of robots in dynamic environments. However, most existing methods address only one side of the problem: they either provide coarse geometric tracking via bounding boxes, or detailed 3D structures like voxel-based occupancy that lack explicit temporal association. In this work, we present Latent Gaussian Splatting for 4D Panoptic Occupancy Tracking (LaGS) that advances spatiotemporal scene understanding in a holistic direction. Our approach incorporates camera-based end-to-end tracking with mask-based multi-view panoptic occupancy prediction, and addresses the key challenge of efficiently aggregating multi-view information into 3D voxel grids via a novel latent Gaussian splatting approach. Specifically, we first fuse observations into 3D Gaussians that serve as a sparse point-centric latent representation of the 3D scene, and then splat the aggregated features onto a 3D voxel grid that is decoded by a mask-based segmentation head. We evaluate LaGS on the Occ3D nuScenes and Waymo datasets, achieving state-of-the-art performance for 4D panoptic occupancy tracking. We make our code available at https://lags.cs.uni-freiburg.de/.
Amodal Optical Flow
Nov 13, 2023



Optical flow estimation is very challenging in situations with transparent or occluded objects. In this work, we address these challenges at the task level by introducing Amodal Optical Flow, which integrates optical flow with amodal perception. Instead of only representing the visible regions, we define amodal optical flow as a multi-layered pixel-level motion field that encompasses both visible and occluded regions of the scene. To facilitate research on this new task, we extend the AmodalSynthDrive dataset to include pixel-level labels for amodal optical flow estimation. We present several strong baselines, along with the Amodal Flow Quality metric to quantify the performance in an interpretable manner. Furthermore, we propose the novel AmodalFlowNet as an initial step toward addressing this task. AmodalFlowNet consists of a transformer-based cost-volume encoder paired with a recurrent transformer decoder which facilitates recurrent hierarchical feature propagation and amodal semantic grounding. We demonstrate the tractability of amodal optical flow in extensive experiments and show its utility for downstream tasks such as panoptic tracking. We make the dataset, code, and trained models publicly available at http://amodal-flow.cs.uni-freiburg.de.
CCMR: High Resolution Optical Flow Estimation via Coarse-to-Fine Context-Guided Motion Reasoning
Nov 05, 2023


Attention-based motion aggregation concepts have recently shown their usefulness in optical flow estimation, in particular when it comes to handling occluded regions. However, due to their complexity, such concepts have been mainly restricted to coarse-resolution single-scale approaches that fail to provide the detailed outcome of high-resolution multi-scale networks. In this paper, we hence propose CCMR: a high-resolution coarse-to-fine approach that leverages attention-based motion grouping concepts to multi-scale optical flow estimation. CCMR relies on a hierarchical two-step attention-based context-motion grouping strategy that first computes global multi-scale context features and then uses them to guide the actual motion grouping. As we iterate both steps over all coarse-to-fine scales, we adapt cross covariance image transformers to allow for an efficient realization while maintaining scale-dependent properties. Experiments and ablations demonstrate that our efforts of combining multi-scale and attention-based concepts pay off. By providing highly detailed flow fields with strong improvements in both occluded and non-occluded regions, our CCMR approach not only outperforms both the corresponding single-scale attention-based and multi-scale attention-free baselines by up to 23.0% and 21.6%, respectively, it also achieves state-of-the-art results, ranking first on KITTI 2015 and second on MPI Sintel Clean and Final. Code and trained models are available at https://github.com/cv-stuttgart /CCMR.
High Resolution Multi-Scale RAFT (Robust Vision Challenge 2022)
Oct 30, 2022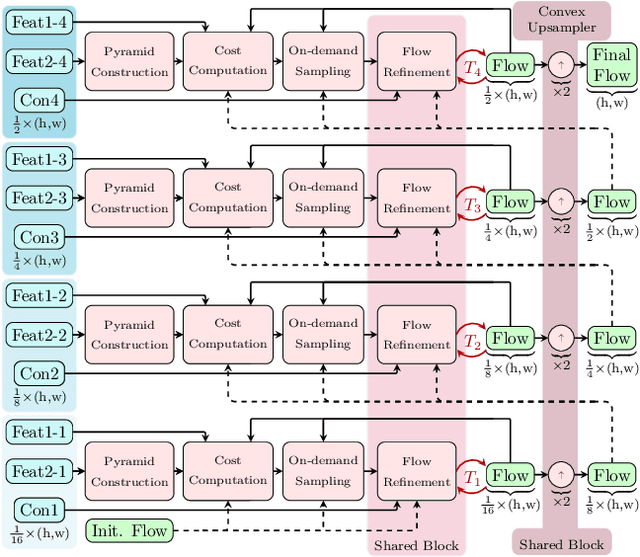
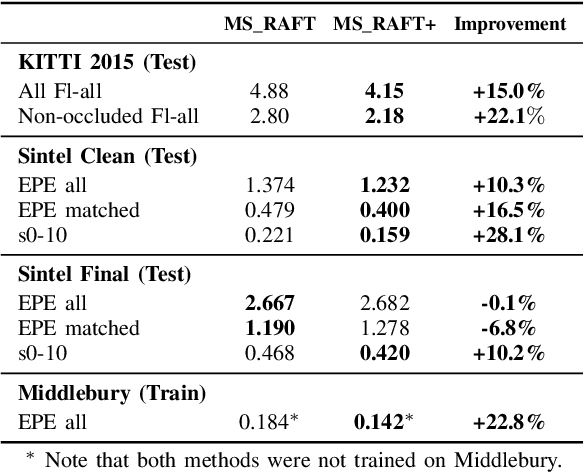
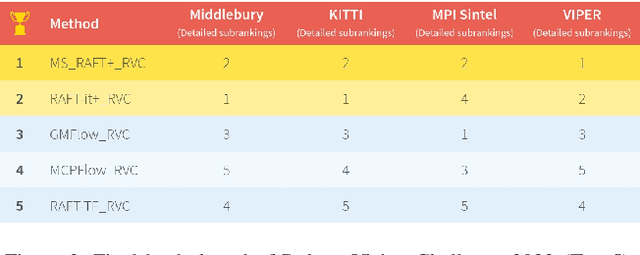
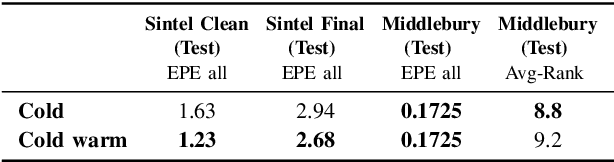
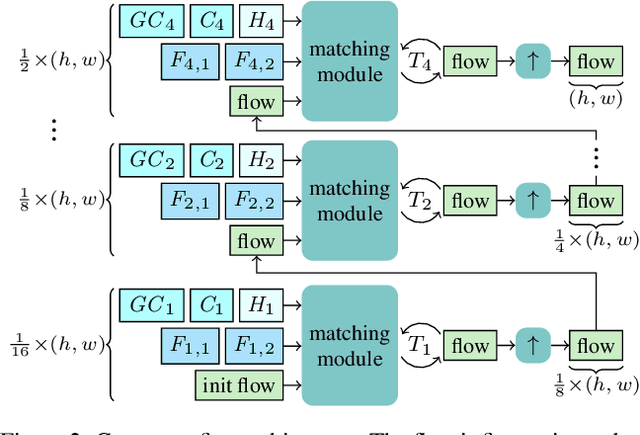
In this report, we present our optical flow approach, MS-RAFT+, that won the Robust Vision Challenge 2022. It is based on the MS-RAFT method, which successfully integrates several multi-scale concepts into single-scale RAFT. Our approach extends this method by exploiting an additional finer scale for estimating the flow, which is made feasible by on-demand cost computation. This way, it can not only operate at half the original resolution, but also use MS-RAFT's shared convex upsampler to obtain full resolution flow. Moreover, our approach relies on an adjusted fine-tuning scheme during training. This in turn aims at improving the generalization across benchmarks. Among all participating methods in the Robust Vision Challenge, our approach ranks first on VIPER and second on KITTI, Sintel, and Middlebury, resulting in the first place of the overall ranking.