 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCMR: High Resolution Optical Flow Estimation via Coarse-to-Fine Context-Guided Motion Reasoning
Nov 05, 2023


Attention-based motion aggregation concepts have recently shown their usefulness in optical flow estimation, in particular when it comes to handling occluded regions. However, due to their complexity, such concepts have been mainly restricted to coarse-resolution single-scale approaches that fail to provide the detailed outcome of high-resolution multi-scale networks. In this paper, we hence propose CCMR: a high-resolution coarse-to-fine approach that leverages attention-based motion grouping concepts to multi-scale optical flow estimation. CCMR relies on a hierarchical two-step attention-based context-motion grouping strategy that first computes global multi-scale context features and then uses them to guide the actual motion grouping. As we iterate both steps over all coarse-to-fine scales, we adapt cross covariance image transformers to allow for an efficient realization while maintaining scale-dependent properties. Experiments and ablations demonstrate that our efforts of combining multi-scale and attention-based concepts pay off. By providing highly detailed flow fields with strong improvements in both occluded and non-occluded regions, our CCMR approach not only outperforms both the corresponding single-scale attention-based and multi-scale attention-free baselines by up to 23.0% and 21.6%, respectively, it also achieves state-of-the-art results, ranking first on KITTI 2015 and second on MPI Sintel Clean and Final. Code and trained models are available at https://github.com/cv-stuttgart /CCMR.
High Resolution Multi-Scale RAFT (Robust Vision Challenge 2022)
Oct 30, 2022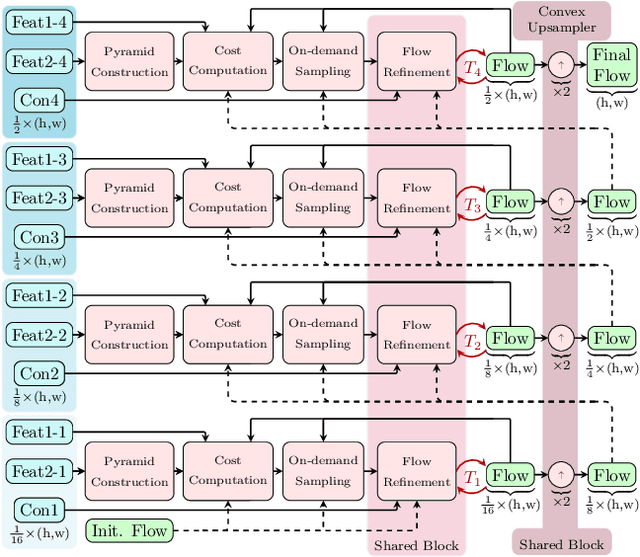
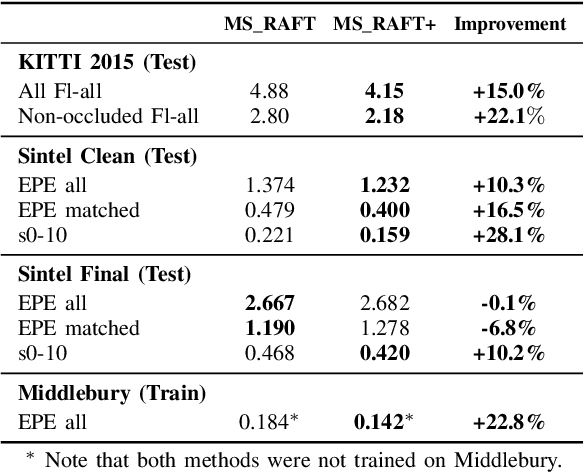
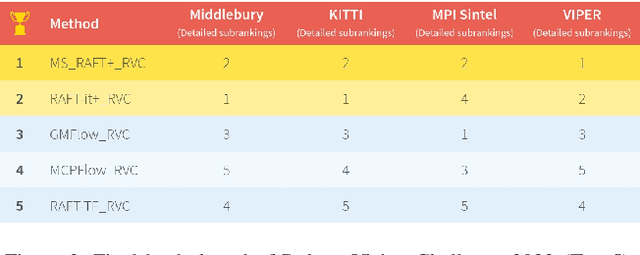
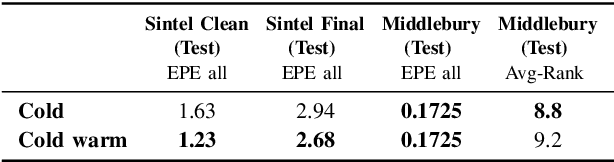
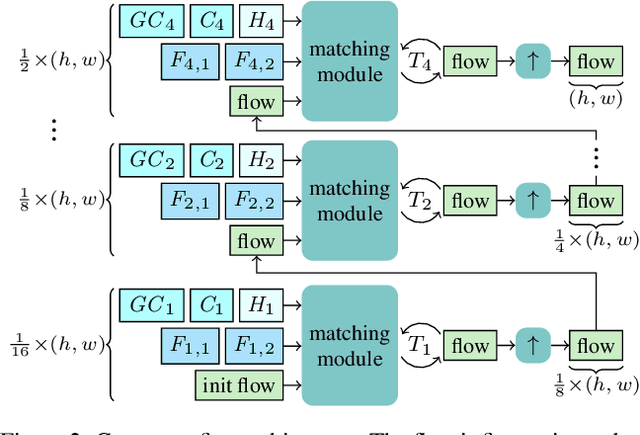
In this report, we present our optical flow approach, MS-RAFT+, that won the Robust Vision Challenge 2022. It is based on the MS-RAFT method, which successfully integrates several multi-scale concepts into single-scale RAFT. Our approach extends this method by exploiting an additional finer scale for estimating the flow, which is made feasible by on-demand cost computation. This way, it can not only operate at half the original resolution, but also use MS-RAFT's shared convex upsampler to obtain full resolution flow. Moreover, our approach relies on an adjusted fine-tuning scheme during training. This in turn aims at improving the generalization across benchmarks. Among all participating methods in the Robust Vision Challenge, our approach ranks first on VIPER and second on KITTI, Sintel, and Middlebury, resulting in the first place of the overall ranking.
Multi-Scale RAFT: Combining Hierarchical Concepts for Learning-based Optical FLow Estimation
Jul 25, 2022
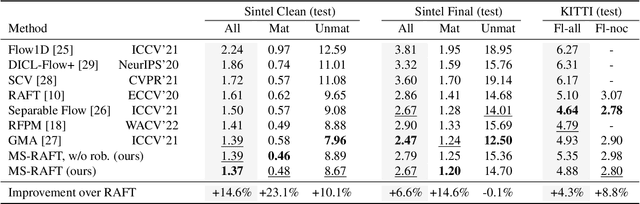
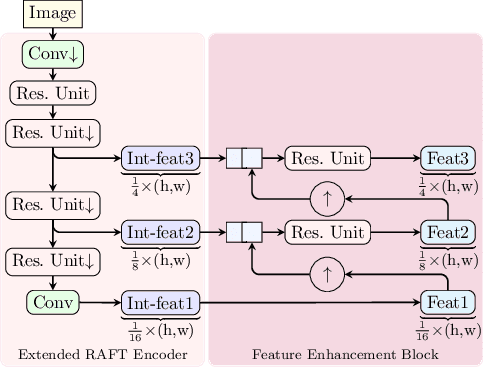
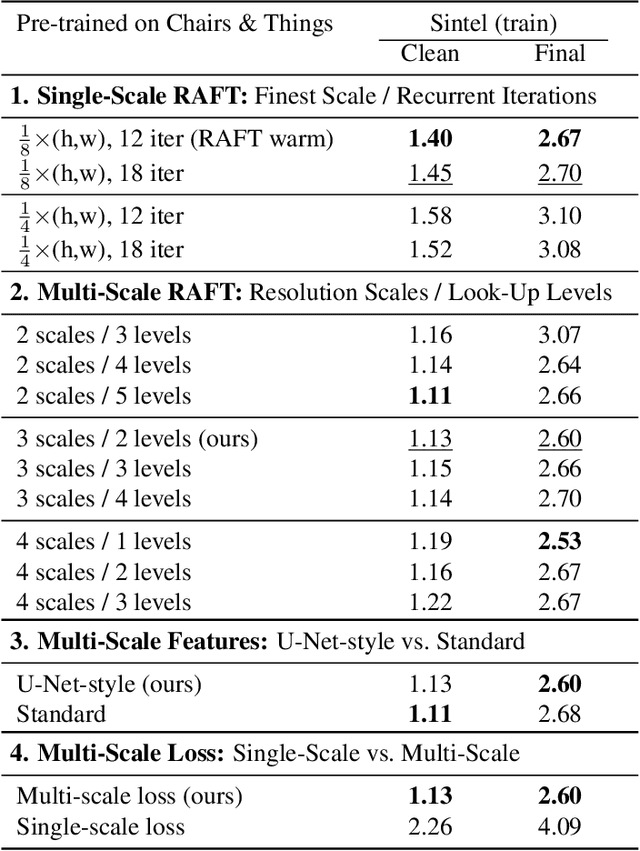
Many classical and learning-based optical flow methods rely on hierarchical concepts to improve both accuracy and robustness. However, one of the currently most successful approaches -- RAFT -- hardly exploits such concepts. In this work, we show that multi-scale ideas are still valuable. More precisely, using RAFT as a baseline, we propose a novel multi-scale neural network that combines several hierarchical concepts within a single estimation framework. These concepts include (i) a partially shared coarse-to-fine architecture, (ii) multi-scale features, (iii) a hierarchical cost volume and (iv) a multi-scale multi-iteration loss. Experiments on MPI Sintel and KITTI clearly demonstrate the benefits of our approach. They show not only substantial improvements compared to RAFT, but also state-of-the-art results -- in particular in non-occluded regions. Code will be available at https://github.com/cv-stuttgart/MS_RAFT.