 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeαDepth: Learning Single-Pass Soft Boundary Decomposition for Stereo Conversion
May 29, 2026Accurately modeling soft boundaries, e.g., hair and defocus blur, is a fundamental challenge in stereo conversion due to the ambiguous blending of foreground and background. Existing depth models primarily predict single-layer depth, leading to ambiguity in depth correspondence at soft boundaries. While matting techniques can capture opacity for layered modeling, they often struggle in complex scenes with multiple targets and usually require user intervention. This paper introduces αDepth, a layered representation that decomposes soft boundaries for high-fidelity stereo conversion. Specifically, we first resolve mixed color and depth ambiguity by estimating layered color and depth values at soft boundaries. Considering complex multi-target scenes, we design a Circular Alpha Representation (CAR) that shifts the paradigm from global target extraction to local boundary decomposition. Unlike prior matting methods restricted to a single foreground/background, CAR enables efficient scene-level inference without manual guidance. Extensive evaluations demonstrate that αDepth achieves state-of-the-art performance in stereo conversion, eliminating background bleeding and structural distortions at soft boundaries.
Guardians of the Hair: Rescuing Soft Boundaries in Depth, Stereo, and Novel Views
Jan 06, 2026Soft boundaries, like thin hairs, are commonly observed in natural and computer-generated imagery, but they remain challenging for 3D vision due to the ambiguous mixing of foreground and background cues. This paper introduces Guardians of the Hair (HairGuard), a framework designed to recover fine-grained soft boundary details in 3D vision tasks. Specifically, we first propose a novel data curation pipeline that leverages image matting datasets for training and design a depth fixer network to automatically identify soft boundary regions. With a gated residual module, the depth fixer refines depth precisely around soft boundaries while maintaining global depth quality, allowing plug-and-play integration with state-of-the-art depth models. For view synthesis, we perform depth-based forward warping to retain high-fidelity textures, followed by a generative scene painter that fills disoccluded regions and eliminates redundant background artifacts within soft boundaries. Finally, a color fuser adaptively combines warped and inpainted results to produce novel views with consistent geometry and fine-grained details. Extensive experiments demonstrate that HairGuard achieves state-of-the-art performance across monocular depth estimation, stereo image/video conversion, and novel view synthesis, with significant improvements in soft boundary regions.
RobustSpring: Benchmarking Robustness to Image Corruptions for Optical Flow, Scene Flow and Stereo
May 14, 2025

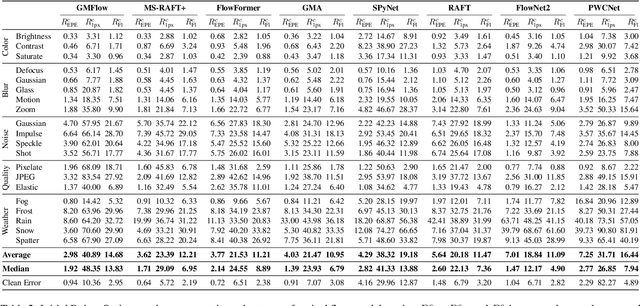

Standard benchmarks for optical flow, scene flow, and stereo vision algorithms generally focus on model accuracy rather than robustness to image corruptions like noise or rain. Hence, the resilience of models to such real-world perturbations is largely unquantified. To address this, we present RobustSpring, a comprehensive dataset and benchmark for evaluating robustness to image corruptions for optical flow, scene flow, and stereo models. RobustSpring applies 20 different image corruptions, including noise, blur, color changes, quality degradations, and weather distortions, in a time-, stereo-, and depth-consistent manner to the high-resolution Spring dataset, creating a suite of 20,000 corrupted images that reflect challenging conditions. RobustSpring enables comparisons of model robustness via a new corruption robustness metric. Integration with the Spring benchmark enables public two-axis evaluations of both accuracy and robustness. We benchmark a curated selection of initial models, observing that accurate models are not necessarily robust and that robustness varies widely by corruption type. RobustSpring is a new computer vision benchmark that treats robustness as a first-class citizen to foster models that combine accuracy with resilience. It will be available at https://spring-benchmark.org.
High-Fidelity Novel View Synthesis via Splatting-Guided Diffusion
Feb 18, 2025



Despite recent advances in Novel View Synthesis (NVS), generating high-fidelity views from single or sparse observations remains a significant challenge. Existing splatting-based approaches often produce distorted geometry due to splatting errors. While diffusion-based methods leverage rich 3D priors to achieve improved geometry, they often suffer from texture hallucination. In this paper, we introduce SplatDiff, a pixel-splatting-guided video diffusion model designed to synthesize high-fidelity novel views from a single image. Specifically, we propose an aligned synthesis strategy for precise control of target viewpoints and geometry-consistent view synthesis. To mitigate texture hallucination, we design a texture bridge module that enables high-fidelity texture generation through adaptive feature fusion. In this manner, SplatDiff leverages the strengths of splatting and diffusion to generate novel views with consistent geometry and high-fidelity details. Extensive experiments verify the state-of-the-art performance of SplatDiff in single-view NVS. Additionally, without extra training, SplatDiff shows remarkable zero-shot performance across diverse tasks, including sparse-view NVS and stereo video conversion.
Distracting Downpour: Adversarial Weather Attacks for Motion Estimation
May 11, 2023



Current adversarial attacks on motion estimation, or optical flow, optimize small per-pixel perturbations, which are unlikely to appear in the real world. In contrast, adverse weather conditions constitute a much more realistic threat scenario. Hence, in this work, we present a novel attack on motion estimation that exploits adversarially optimized particles to mimic weather effects like snowflakes, rain streaks or fog clouds. At the core of our attack framework is a differentiable particle rendering system that integrates particles (i) consistently over multiple time steps (ii) into the 3D space (iii) with a photo-realistic appearance. Through optimization, we obtain adversarial weather that significantly impacts the motion estimation. Surprisingly, methods that previously showed good robustness towards small per-pixel perturbations are particularly vulnerable to adversarial weather. At the same time, augmenting the training with non-optimized weather increases a method's robustness towards weather effects and improves generalizability at almost no additional cost.
Spring: A High-Resolution High-Detail Dataset and Benchmark for Scene Flow, Optical Flow and Stereo
Mar 03, 2023



While recent methods for motion and stereo estimation recover an unprecedented amount of details, such highly detailed structures are neither adequately reflected in the data of existing benchmarks nor their evaluation methodology. Hence, we introduce Spring $-$ a large, high-resolution, high-detail, computer-generated benchmark for scene flow, optical flow, and stereo. Based on rendered scenes from the open-source Blender movie "Spring", it provides photo-realistic HD datasets with state-of-the-art visual effects and ground truth training data. Furthermore, we provide a website to upload, analyze and compare results. Using a novel evaluation methodology based on a super-resolved UHD ground truth, our Spring benchmark can assess the quality of fine structures and provides further detailed performance statistics on different image regions. Regarding the number of ground truth frames, Spring is 60$\times$ larger than the only scene flow benchmark, KITTI 2015, and 15$\times$ larger than the well-established MPI Sintel optical flow benchmark. Initial results for recent methods on our benchmark show that estimating fine details is indeed challenging, as their accuracy leaves significant room for improvement. The Spring benchmark and the corresponding datasets are available at http://spring-benchmark.org.
High Resolution Multi-Scale RAFT (Robust Vision Challenge 2022)
Oct 30, 2022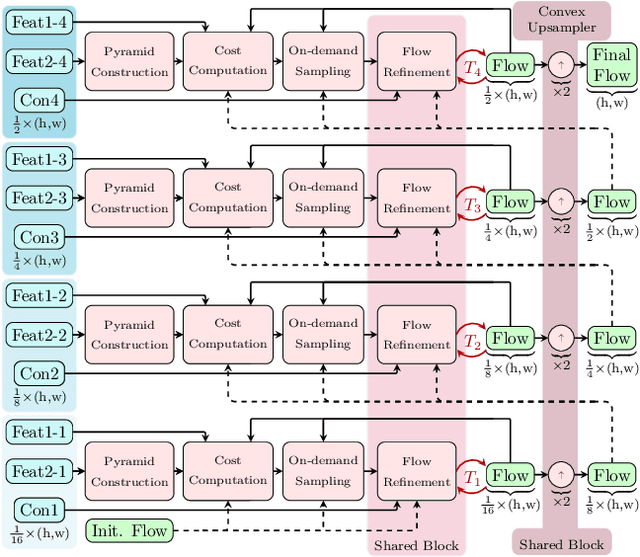
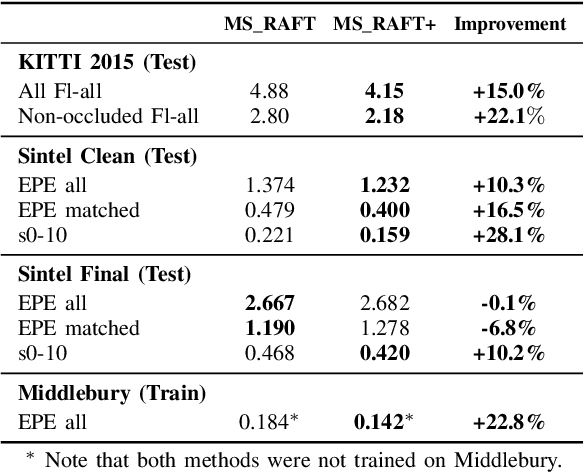
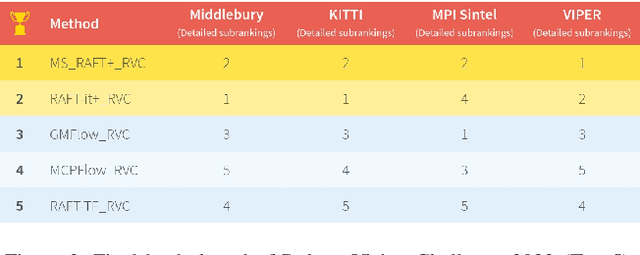
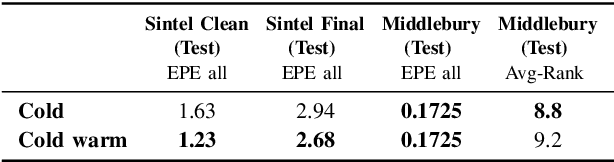
In this report, we present our optical flow approach, MS-RAFT+, that won the Robust Vision Challenge 2022. It is based on the MS-RAFT method, which successfully integrates several multi-scale concepts into single-scale RAFT. Our approach extends this method by exploiting an additional finer scale for estimating the flow, which is made feasible by on-demand cost computation. This way, it can not only operate at half the original resolution, but also use MS-RAFT's shared convex upsampler to obtain full resolution flow. Moreover, our approach relies on an adjusted fine-tuning scheme during training. This in turn aims at improving the generalization across benchmarks. Among all participating methods in the Robust Vision Challenge, our approach ranks first on VIPER and second on KITTI, Sintel, and Middlebury, resulting in the first place of the overall ranking.
Attacking Motion Estimation with Adversarial Snow
Oct 20, 2022
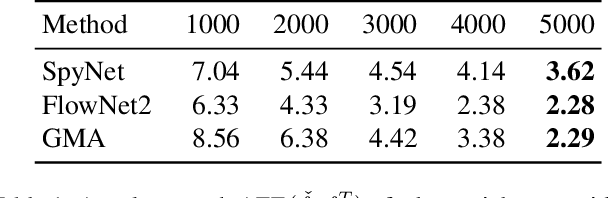
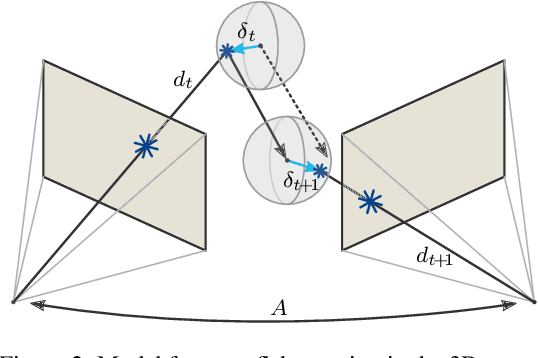
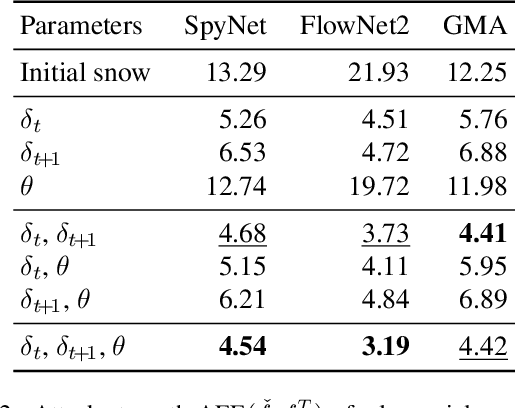
Current adversarial attacks for motion estimation (optical flow) optimize small per-pixel perturbations, which are unlikely to appear in the real world. In contrast, we exploit a real-world weather phenomenon for a novel attack with adversarially optimized snow. At the core of our attack is a differentiable renderer that consistently integrates photorealistic snowflakes with realistic motion into the 3D scene. Through optimization we obtain adversarial snow that significantly impacts the optical flow while being indistinguishable from ordinary snow. Surprisingly, the impact of our novel attack is largest on methods that previously showed a high robustness to small L_p perturbations.
Multi-Scale RAFT: Combining Hierarchical Concepts for Learning-based Optical FLow Estimation
Jul 25, 2022
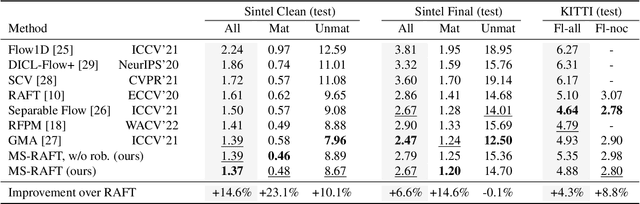
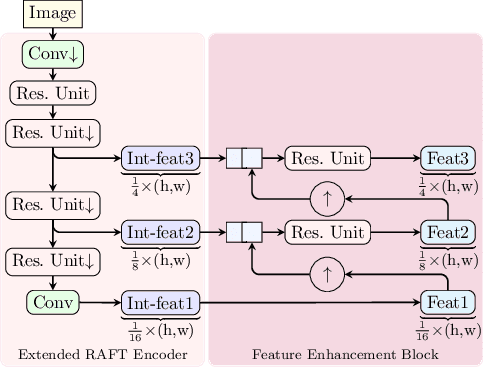
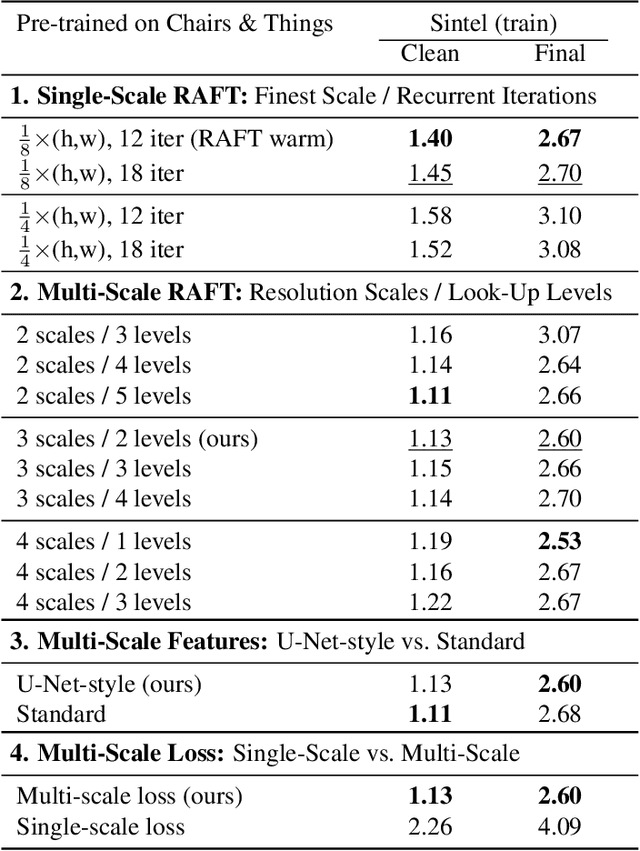
Many classical and learning-based optical flow methods rely on hierarchical concepts to improve both accuracy and robustness. However, one of the currently most successful approaches -- RAFT -- hardly exploits such concepts. In this work, we show that multi-scale ideas are still valuable. More precisely, using RAFT as a baseline, we propose a novel multi-scale neural network that combines several hierarchical concepts within a single estimation framework. These concepts include (i) a partially shared coarse-to-fine architecture, (ii) multi-scale features, (iii) a hierarchical cost volume and (iv) a multi-scale multi-iteration loss. Experiments on MPI Sintel and KITTI clearly demonstrate the benefits of our approach. They show not only substantial improvements compared to RAFT, but also state-of-the-art results -- in particular in non-occluded regions. Code will be available at https://github.com/cv-stuttgart/MS_RAFT.
M-FUSE: Multi-frame Fusion for Scene Flow Estimation
Jul 12, 2022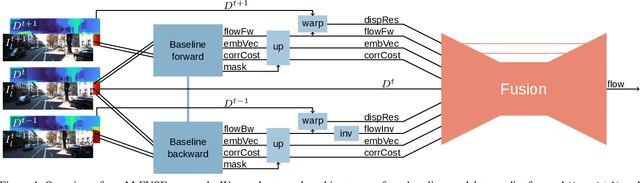
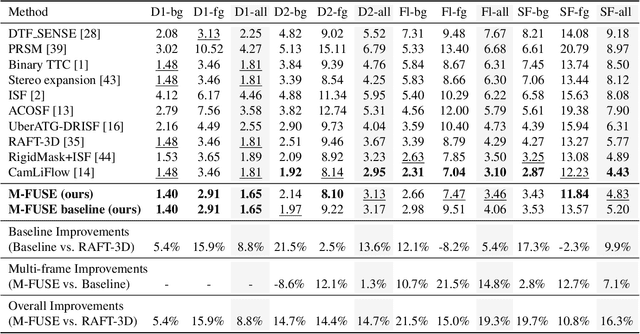

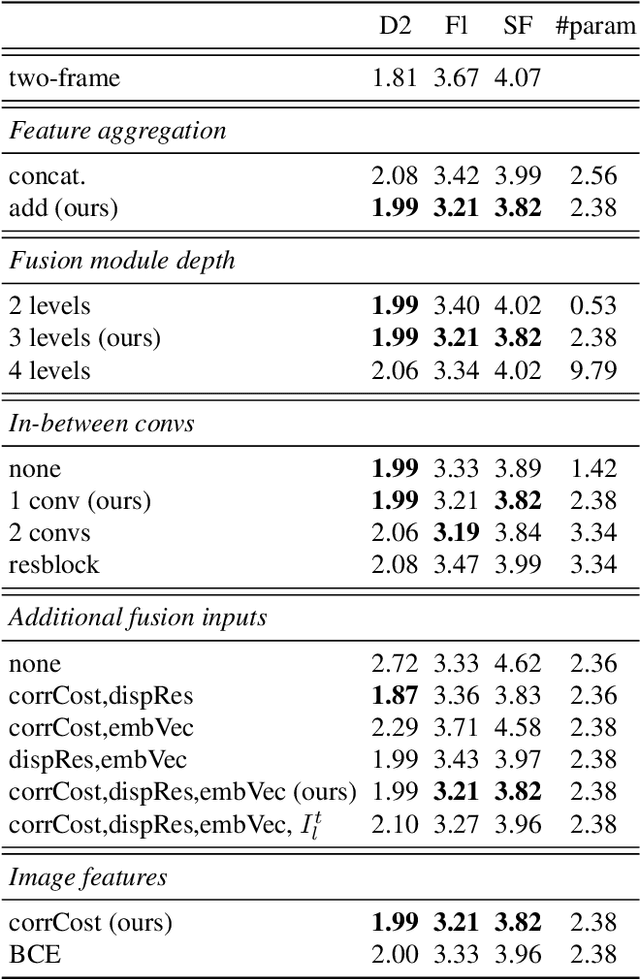
Recently, neural network for scene flow estimation show impressive results on automotive data such as the KITTI benchmark. However, despite of using sophisticated rigidity assumptions and parametrizations, such networks are typically limited to only two frame pairs which does not allow them to exploit temporal information. In our paper we address this shortcoming by proposing a novel multi-frame approach that considers an additional preceding stereo pair. To this end, we proceed in two steps: Firstly, building upon the recent RAFT-3D approach, we develop an advanced two-frame baseline by incorporating an improved stereo method. Secondly, and even more importantly, exploiting the specific modeling concepts of RAFT-3D, we propose a U-Net like architecture that performs a fusion of forward and backward flow estimates and hence allows to integrate temporal information on demand. Experiments on the KITTI benchmark do not only show that the advantages of the improved baseline and the temporal fusion approach complement each other, they also demonstrate that the computed scene flow is highly accurate. More precisely, our approach ranks second overall and first for the even more challenging foreground objects, in total outperforming the original RAFT-3D method by more than 16%. Code is available at https://github.com/cv-stuttgart/M-FUSE.