 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2F2: Self-Supervised High Fidelity Face Reconstruction from Monocular Image
Apr 05, 2022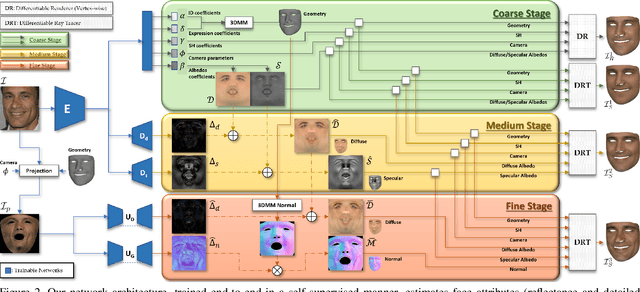


We present a novel face reconstruction method capable of reconstructing detailed face geometry, spatially varying face reflectance from a single monocular image. We build our work upon the recent advances of DNN-based auto-encoders with differentiable ray tracing image formation, trained in self-supervised manner. While providing the advantage of learning-based approaches and real-time reconstruction, the latter methods lacked fidelity. In this work, we achieve, for the first time, high fidelity face reconstruction using self-supervised learning only. Our novel coarse-to-fine deep architecture allows us to solve the challenging problem of decoupling face reflectance from geometry using a single image, at high computational speed. Compared to state-of-the-art methods, our method achieves more visually appealing reconstruction.
Towards High Fidelity Monocular Face Reconstruction with Rich Reflectance using Self-supervised Learning and Ray Tracing
Mar 29, 2021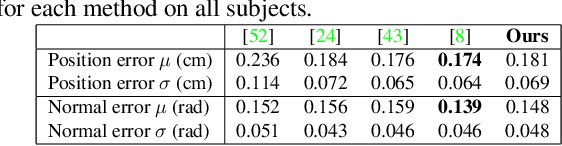
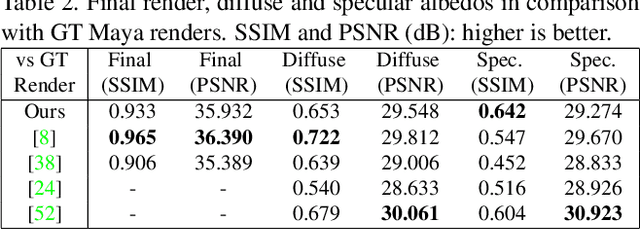
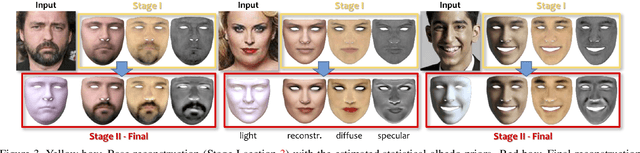
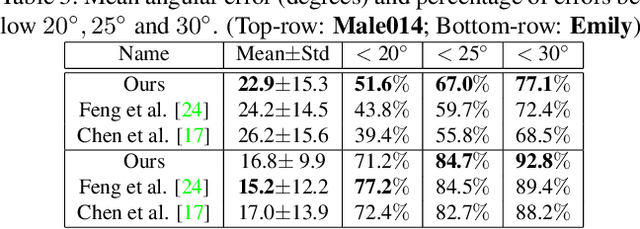
Robust face reconstruction from monocular image in general lighting conditions is challenging. Methods combining deep neural network encoders with differentiable rendering have opened up the path for very fast monocular reconstruction of geometry, lighting and reflectance. They can also be trained in self-supervised manner for increased robustness and better generalization. However, their differentiable rasterization based image formation models, as well as underlying scene parameterization, limit them to Lambertian face reflectance and to poor shape details. More recently, ray tracing was introduced for monocular face reconstruction within a classic optimization-based framework and enables state-of-the art results. However optimization-based approaches are inherently slow and lack robustness. In this paper, we build our work on the aforementioned approaches and propose a new method that greatly improves reconstruction quality and robustness in general scenes. We achieve this by combining a CNN encoder with a differentiable ray tracer, which enables us to base the reconstruction on much more advanced personalized diffuse and specular albedos, a more sophisticated illumination model and a plausible representation of self-shadows. This enables to take a big leap forward in reconstruction quality of shape, appearance and lighting even in scenes with difficult illumination. With consistent face attributes reconstruction, our method leads to practical applications such as relighting and self-shadows removal. Compared to state-of-the-art methods, our results show improved accuracy and validity of the approach.
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021
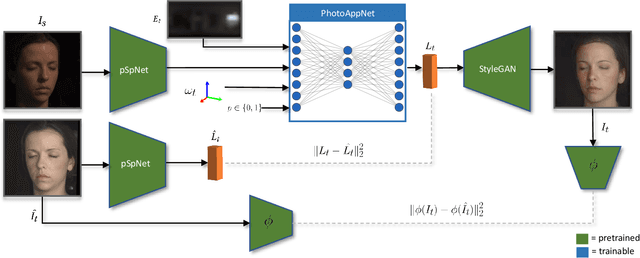
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
Practical Face Reconstruction via Differentiable Ray Tracing
Jan 13, 2021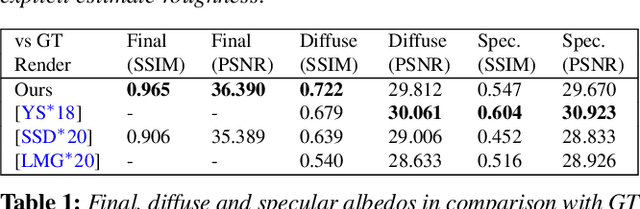
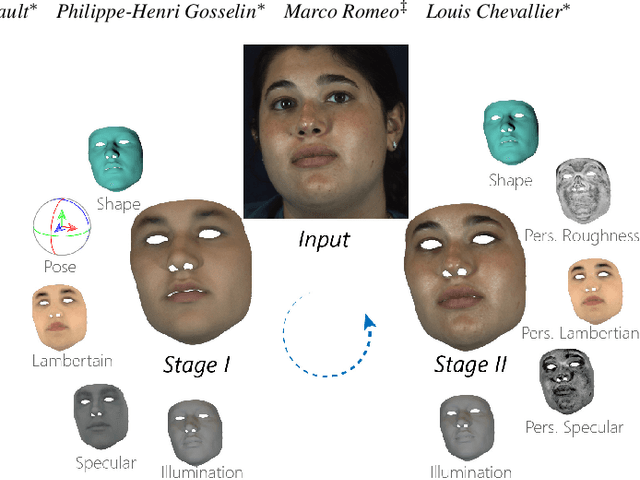
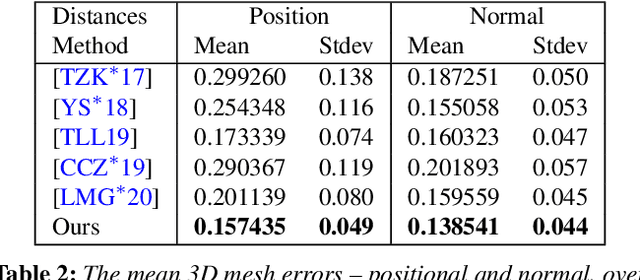
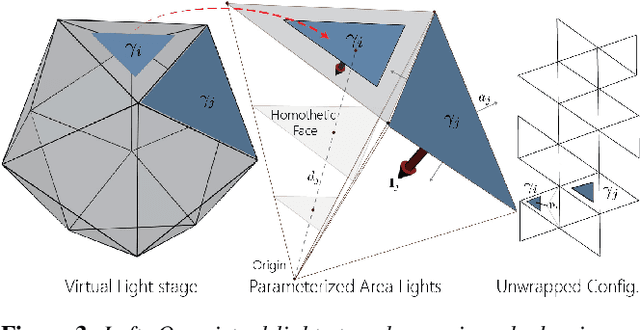
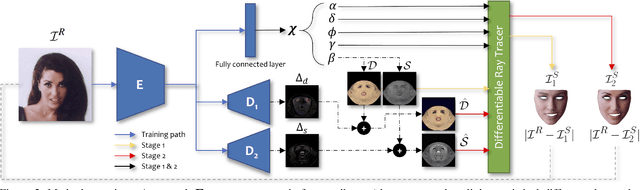
We present a differentiable ray-tracing based novel face reconstruction approach where scene attributes - 3D geometry, reflectance (diffuse, specular and roughness), pose, camera parameters, and scene illumination - are estimated from unconstrained monocular images. The proposed method models scene illumination via a novel, parameterized virtual light stage, which in-conjunction with differentiable ray-tracing, introduces a coarse-to-fine optimization formulation for face reconstruction. Our method can not only handle unconstrained illumination and self-shadows conditions, but also estimates diffuse and specular albedos. To estimate the face attributes consistently and with practical semantics, a two-stage optimization strategy systematically uses a subset of parametric attributes, where subsequent attribute estimations factor those previously estimated. For example, self-shadows estimated during the first stage, later prevent its baking into the personalized diffuse and specular albedos in the second stage. We show the efficacy of our approach in several real-world scenarios, where face attributes can be estimated even under extreme illumination conditions. Ablation studies, analyses and comparisons against several recent state-of-the-art methods show improved accuracy and versatility of our approach. With consistent face attributes reconstruction, our method leads to several style -- illumination, albedo, self-shadow -- edit and transfer applications, as discussed in the paper.
Face Reflectance and Geometry Modeling via Differentiable Ray Tracing
Oct 03, 2019
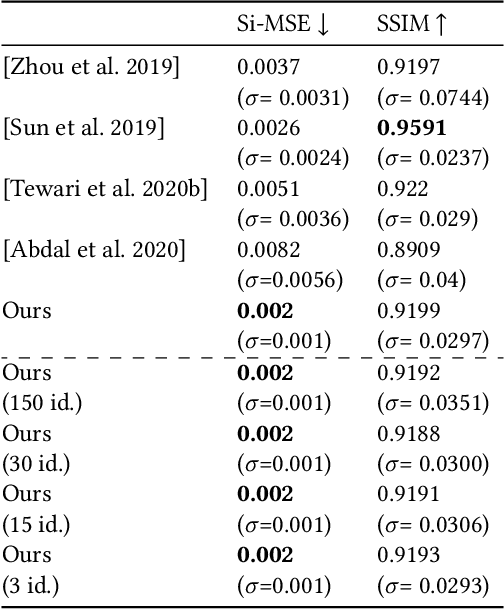
We present a novel strategy to automatically reconstruct 3D faces from monocular images with explicitly disentangled facial geometry (pose, identity and expression), reflectance (diffuse and specular albedo), and self-shadows. The scene lights are modeled as a virtual light stage with pre-oriented area lights used in conjunction with differentiable Monte-Carlo ray tracing to optimize the scene and face parameters. With correctly disentangled self-shadows and specular reflection parameters, we can not only obtain robust facial geometry reconstruction, but also gain explicit control over these parameters, with several practical applications. We can change facial expressions with accurate resultant self-shadows or relight the scene and obtain accurate specular reflection and several other parameter combinations.
SoDeep: a Sorting Deep net to learn ranking loss surrogates
Apr 08, 2019

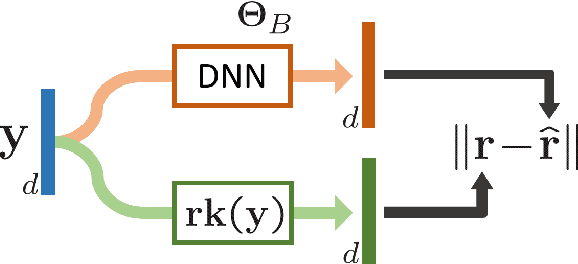
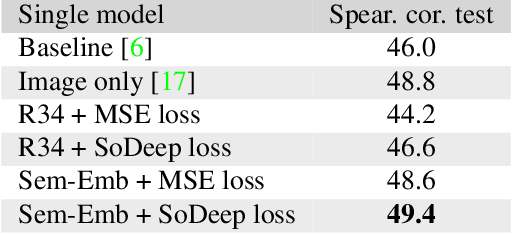
Several tasks in machine learning are evaluated using non-differentiable metrics such as mean average precision or Spearman correlation. However, their non-differentiability prevents from using them as objective functions in a learning framework. Surrogate and relaxation methods exist but tend to be specific to a given metric. In the present work, we introduce a new method to learn approximations of such non-differentiable objective functions. Our approach is based on a deep architecture that approximates the sorting of arbitrary sets of scores. It is trained virtually for free using synthetic data. This sorting deep (SoDeep) net can then be combined in a plug-and-play manner with existing deep architectures. We demonstrate the interest of our approach in three different tasks that require ranking: Cross-modal text-image retrieval, multi-label image classification and visual memorability ranking. Our approach yields very competitive results on these three tasks, which validates the merit and the flexibility of SoDeep as a proxy for sorting operation in ranking-based losses.
Finding beans in burgers: Deep semantic-visual embedding with localization
Apr 06, 2018

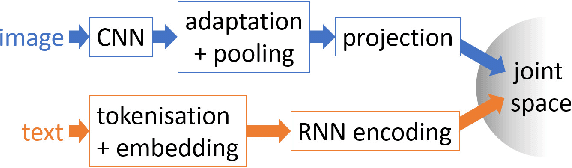

Several works have proposed to learn a two-path neural network that maps images and texts, respectively, to a same shared Euclidean space where geometry captures useful semantic relationships. Such a multi-modal embedding can be trained and used for various tasks, notably image captioning. In the present work, we introduce a new architecture of this type, with a visual path that leverages recent space-aware pooling mechanisms. Combined with a textual path which is jointly trained from scratch, our semantic-visual embedding offers a versatile model. Once trained under the supervision of captioned images, it yields new state-of-the-art performance on cross-modal retrieval. It also allows the localization of new concepts from the embedding space into any input image, delivering state-of-the-art result on the visual grounding of phrases.
Hybrid multi-layer Deep CNN/Aggregator feature for image classification
Mar 13, 2015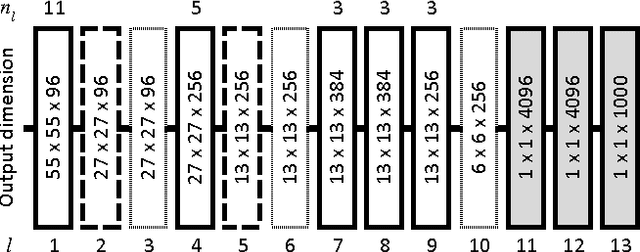

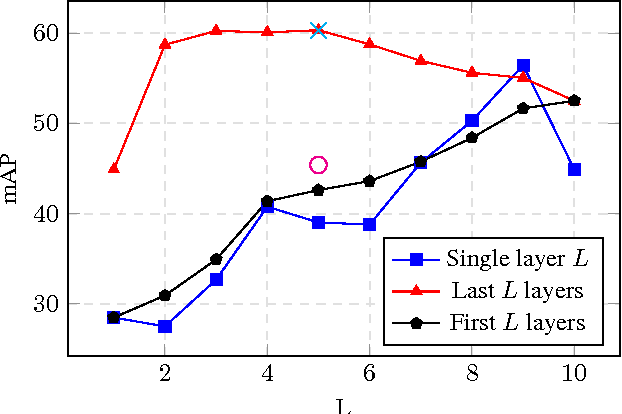
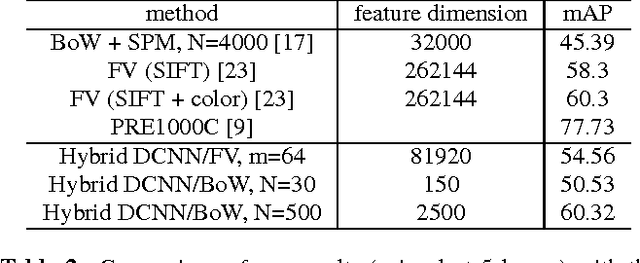
Deep Convolutional Neural Networks (DCNN) have established a remarkable performance benchmark in the field of image classification, displacing classical approaches based on hand-tailored aggregations of local descriptors. Yet DCNNs impose high computational burdens both at training and at testing time, and training them requires collecting and annotating large amounts of training data. Supervised adaptation methods have been proposed in the literature that partially re-learn a transferred DCNN structure from a new target dataset. Yet these require expensive bounding-box annotations and are still computationally expensive to learn. In this paper, we address these shortcomings of DCNN adaptation schemes by proposing a hybrid approach that combines conventional, unsupervised aggregators such as Bag-of-Words (BoW), with the DCNN pipeline by treating the output of intermediate layers as densely extracted local descriptors. We test a variant of our approach that uses only intermediate DCNN layers on the standard PASCAL VOC 2007 dataset and show performance significantly higher than the standard BoW model and comparable to Fisher vector aggregation but with a feature that is 150 times smaller. A second variant of our approach that includes the fully connected DCNN layers significantly outperforms Fisher vector schemes and performs comparably to DCNN approaches adapted to Pascal VOC 2007, yet at only a small fraction of the training and testing cost.