 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Identity, no problem: Motion through detection for people tracking
Nov 25, 2024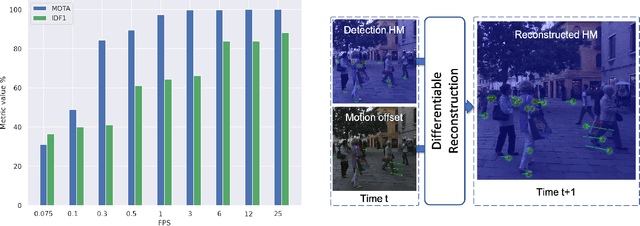
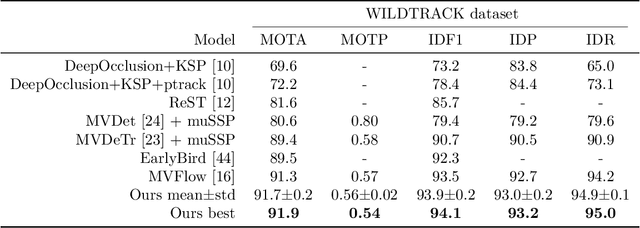
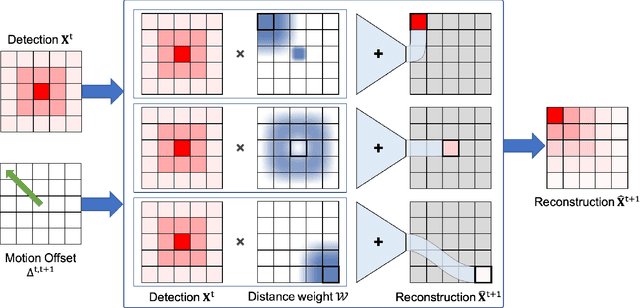
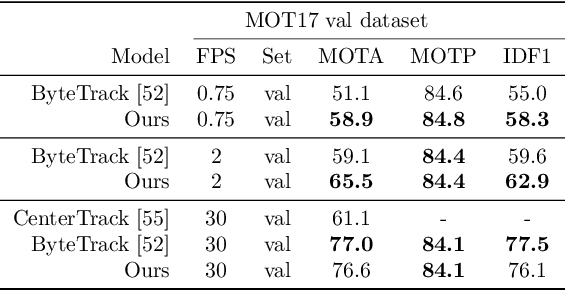
Tracking-by-detection has become the de facto standard approach to people tracking. To increase robustness, some approaches incorporate re-identification using appearance models and regressing motion offset, which requires costly identity annotations. In this paper, we propose exploiting motion clues while providing supervision only for the detections, which is much easier to do. Our algorithm predicts detection heatmaps at two different times, along with a 2D motion estimate between the two images. It then warps one heatmap using the motion estimate and enforces consistency with the other one. This provides the required supervisory signal on the motion without the need for any motion annotations. In this manner, we couple the information obtained from different images during training and increase accuracy, especially in crowded scenes and when using low frame-rate sequences. We show that our approach delivers state-of-the-art results for single- and multi-view multi-target tracking on the MOT17 and WILDTRACK datasets.
Addressing the Elephant in the Room: Robust Animal Re-Identification with Unsupervised Part-Based Feature Alignment
May 22, 2024



Animal Re-ID is crucial for wildlife conservation, yet it faces unique challenges compared to person Re-ID. First, the scarcity and lack of diversity in datasets lead to background-biased models. Second, animal Re-ID depends on subtle, species-specific cues, further complicated by variations in pose, background, and lighting. This study addresses background biases by proposing a method to systematically remove backgrounds in both training and evaluation phases. And unlike prior works that depend on pose annotations, our approach utilizes an unsupervised technique for feature alignment across body parts and pose variations, enhancing practicality. Our method achieves superior results on three key animal Re-ID datasets: ATRW, YakReID-103, and ELPephants.
CLOAF: CoLlisiOn-Aware Human Flow
Mar 14, 2024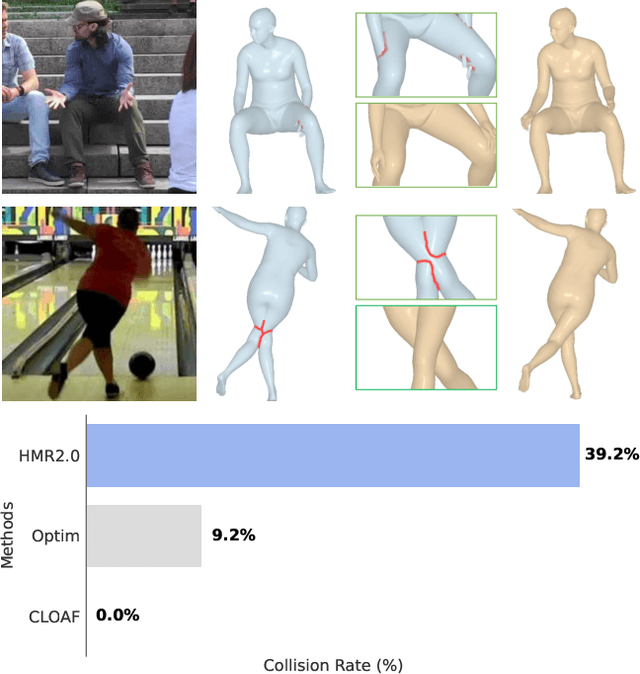
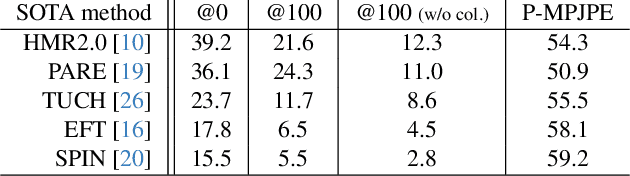


Even the best current algorithms for estimating body 3D shape and pose yield results that include body self-intersections. In this paper, we present CLOAF, which exploits the diffeomorphic nature of Ordinary Differential Equations to eliminate such self-intersections while still imposing body shape constraints. We show that, unlike earlier approaches to addressing this issue, ours completely eliminates the self-intersections without compromising the accuracy of the reconstructions. Being differentiable, CLOAF can be used to fine-tune pose and shape estimation baselines to improve their overall performance and eliminate self-intersections in their predictions. Furthermore, we demonstrate how our CLOAF strategy can be applied to practically any motion field induced by the user. CLOAF also makes it possible to edit motion to interact with the environment without worrying about potential collision or loss of body-shape prior.
Learning Transformations To Reduce the Geometric Shift in Object Detection
Jan 13, 2023



The performance of modern object detectors drops when the test distribution differs from the training one. Most of the methods that address this focus on object appearance changes caused by, e.g., different illumination conditions, or gaps between synthetic and real images. Here, by contrast, we tackle geometric shifts emerging from variations in the image capture process, or due to the constraints of the environment causing differences in the apparent geometry of the content itself. We introduce a self-training approach that learns a set of geometric transformations to minimize these shifts without leveraging any labeled data in the new domain, nor any information about the cameras. We evaluate our method on two different shifts, i.e., a camera's field of view (FoV) change and a viewpoint change. Our results evidence that learning geometric transformations helps detectors to perform better in the target domains.
CLIP the Gap: A Single Domain Generalization Approach for Object Detection
Jan 13, 2023



Single Domain Generalization (SDG) tackles the problem of training a model on a single source domain so that it generalizes to any unseen target domain. While this has been well studied for image classification, the literature on SDG object detection remains almost non-existent. To address the challenges of simultaneously learning robust object localization and representation, we propose to leverage a pre-trained vision-language model to introduce semantic domain concepts via textual prompts. We achieve this via a semantic augmentation strategy acting on the features extracted by the detector backbone, as well as a text-based classification loss. Our experiments evidence the benefits of our approach, outperforming by 10% the only existing SDG object detection method, Single-DGOD [49], on their own diverse weather-driving benchmark.
Multi-view Tracking Using Weakly Supervised Human Motion Prediction
Oct 19, 2022
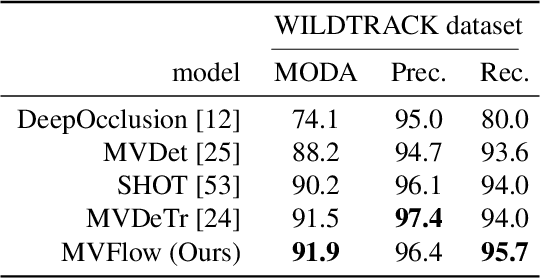
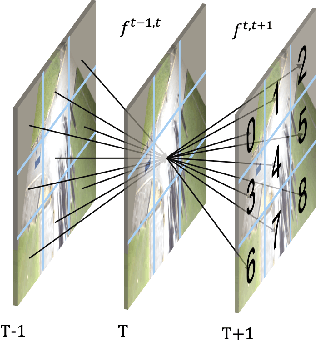
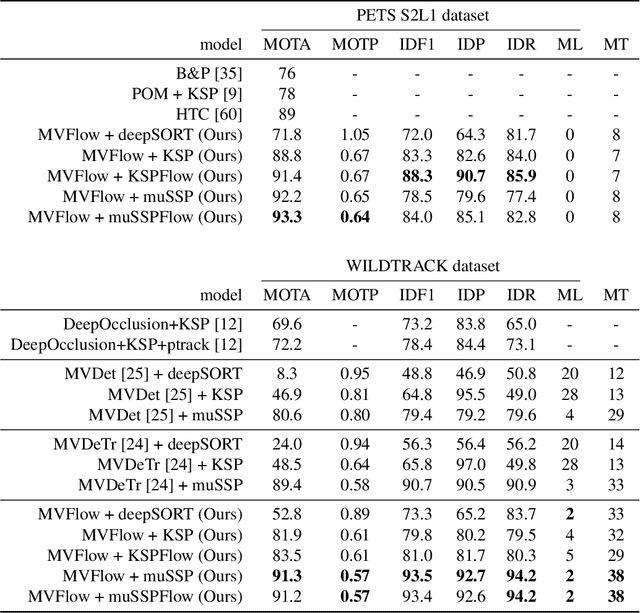
Multi-view approaches to people-tracking have the potential to better handle occlusions than single-view ones in crowded scenes. They often rely on the tracking-by-detection paradigm, which involves detecting people first and then connecting the detections. In this paper, we argue that an even more effective approach is to predict people motion over time and infer people's presence in individual frames from these. This enables to enforce consistency both over time and across views of a single temporal frame. We validate our approach on the PETS2009 and WILDTRACK datasets and demonstrate that it outperforms state-of-the-art methods.
Two-level Data Augmentation for Calibrated Multi-view Detection
Oct 19, 2022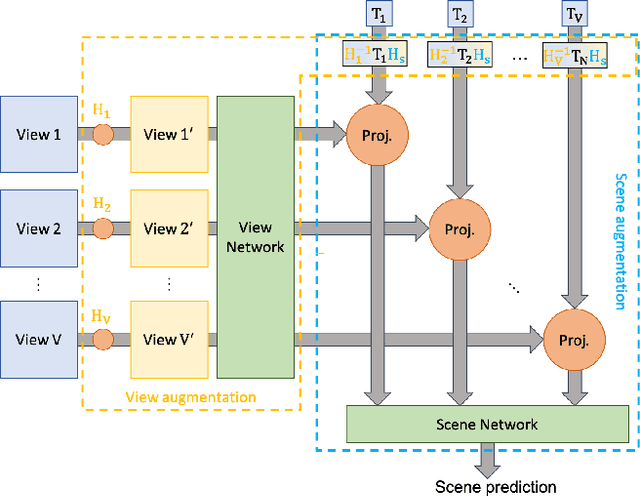
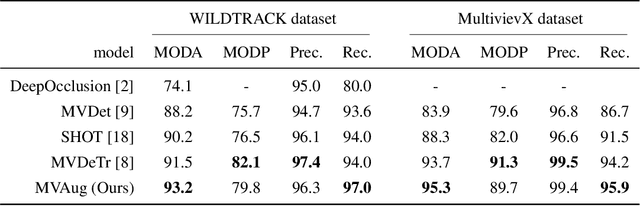


Data augmentation has proven its usefulness to improve model generalization and performance. While it is commonly applied in computer vision application when it comes to multi-view systems, it is rarely used. Indeed geometric data augmentation can break the alignment among views. This is problematic since multi-view data tend to be scarce and it is expensive to annotate. In this work we propose to solve this issue by introducing a new multi-view data augmentation pipeline that preserves alignment among views. Additionally to traditional augmentation of the input image we also propose a second level of augmentation applied directly at the scene level. When combined with our simple multi-view detection model, our two-level augmentation pipeline outperforms all existing baselines by a significant margin on the two main multi-view multi-person detection datasets WILDTRACK and MultiviewX.
SoDeep: a Sorting Deep net to learn ranking loss surrogates
Apr 08, 2019

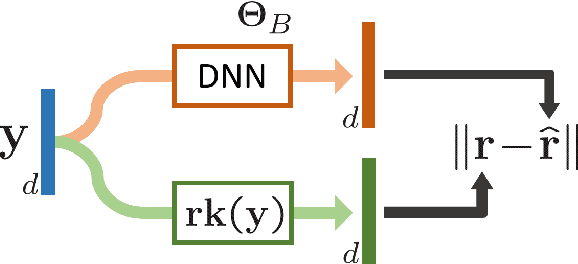
Several tasks in machine learning are evaluated using non-differentiable metrics such as mean average precision or Spearman correlation. However, their non-differentiability prevents from using them as objective functions in a learning framework. Surrogate and relaxation methods exist but tend to be specific to a given metric. In the present work, we introduce a new method to learn approximations of such non-differentiable objective functions. Our approach is based on a deep architecture that approximates the sorting of arbitrary sets of scores. It is trained virtually for free using synthetic data. This sorting deep (SoDeep) net can then be combined in a plug-and-play manner with existing deep architectures. We demonstrate the interest of our approach in three different tasks that require ranking: Cross-modal text-image retrieval, multi-label image classification and visual memorability ranking. Our approach yields very competitive results on these three tasks, which validates the merit and the flexibility of SoDeep as a proxy for sorting operation in ranking-based losses.
VideoMem: Constructing, Analyzing, Predicting Short-term and Long-term Video Memorability
Dec 05, 2018



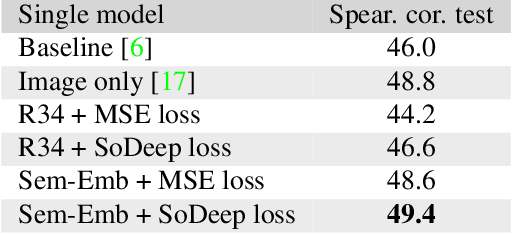
Humans share a strong tendency to memorize/forget some of the visual information they encounter. This paper focuses on providing computational models for the prediction of the intrinsic memorability of visual content. To address this new challenge, we introduce a large scale dataset (VideoMem) composed of 10,000 videos annotated with memorability scores. In contrast to previous work on image memorability -- where memorability was measured a few minutes after memorization -- memory performance is measured twice: a few minutes after memorization and again 24-72 hours later. Hence, the dataset comes with short-term and long-term memorability annotations. After an in-depth analysis of the dataset, we investigate several deep neural network based models for the prediction of video memorability. Our best model using a ranking loss achieves a Spearman's rank correlation of 0.494 for short-term memorability prediction, while our proposed model with attention mechanism provides insights of what makes a content memorable. The VideoMem dataset with pre-extracted features is publicly available.
Finding beans in burgers: Deep semantic-visual embedding with localization
Apr 06, 2018

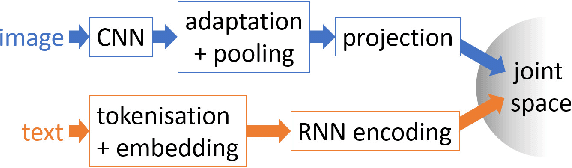

Several works have proposed to learn a two-path neural network that maps images and texts, respectively, to a same shared Euclidean space where geometry captures useful semantic relationships. Such a multi-modal embedding can be trained and used for various tasks, notably image captioning. In the present work, we introduce a new architecture of this type, with a visual path that leverages recent space-aware pooling mechanisms. Combined with a textual path which is jointly trained from scratch, our semantic-visual embedding offers a versatile model. Once trained under the supervision of captioned images, it yields new state-of-the-art performance on cross-modal retrieval. It also allows the localization of new concepts from the embedding space into any input image, delivering state-of-the-art result on the visual grounding of phrases.