 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Spatial Frequency Based Constraints on Adversarial Robustness
May 05, 2021
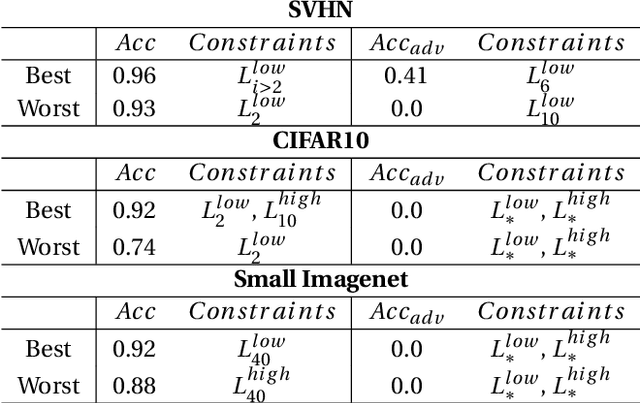
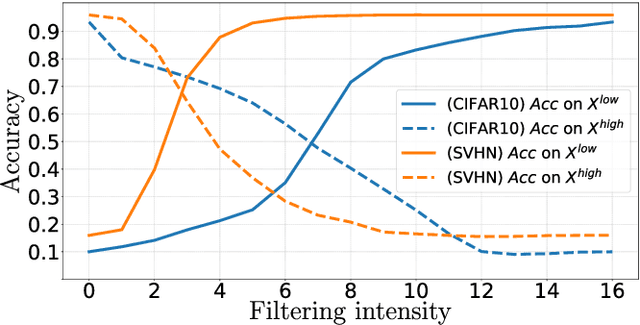
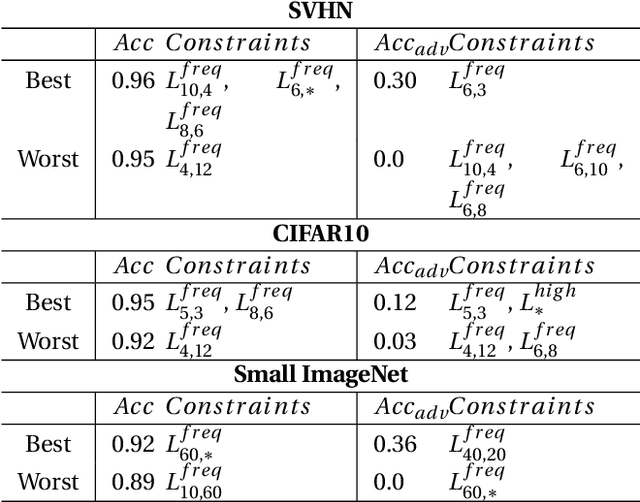
Adversarial examples mainly exploit changes to input pixels to which humans are not sensitive to, and arise from the fact that models make decisions based on uninterpretable features. Interestingly, cognitive science reports that the process of interpretability for human classification decision relies predominantly on low spatial frequency components. In this paper, we investigate the robustness to adversarial perturbations of models enforced during training to leverage information corresponding to different spatial frequency ranges. We show that it is tightly linked to the spatial frequency characteristics of the data at stake. Indeed, depending on the data set, the same constraint may results in very different level of robustness (up to 0.41 adversarial accuracy difference). To explain this phenomenon, we conduct several experiments to enlighten influential factors such as the level of sensitivity to high frequencies, and the transferability of adversarial perturbations between original and low-pass filtered inputs.
VideoMem: Constructing, Analyzing, Predicting Short-term and Long-term Video Memorability
Dec 05, 2018



Humans share a strong tendency to memorize/forget some of the visual information they encounter. This paper focuses on providing computational models for the prediction of the intrinsic memorability of visual content. To address this new challenge, we introduce a large scale dataset (VideoMem) composed of 10,000 videos annotated with memorability scores. In contrast to previous work on image memorability -- where memorability was measured a few minutes after memorization -- memory performance is measured twice: a few minutes after memorization and again 24-72 hours later. Hence, the dataset comes with short-term and long-term memorability annotations. After an in-depth analysis of the dataset, we investigate several deep neural network based models for the prediction of video memorability. Our best model using a ranking loss achieves a Spearman's rank correlation of 0.494 for short-term memorability prediction, while our proposed model with attention mechanism provides insights of what makes a content memorable. The VideoMem dataset with pre-extracted features is publicly available.
MediaEval 2018: Predicting Media Memorability Task
Jul 03, 2018In this paper, we present the Predicting Media Memorability task, which is proposed as part of the MediaEval 2018 Benchmarking Initiative for Multimedia Evaluation. Participants are expected to design systems that automatically predict memorability scores for videos, which reflect the probability of a video being remembered. In contrast to previous work in image memorability prediction, where memorability was measured a few minutes after memorization, the proposed dataset comes with short-term and long-term memorability annotations. All task characteristics are described, namely: the task's challenges and breakthrough, the released data set and ground truth, the required participant runs and the evaluation metrics.