 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Spatial Frequency Based Constraints on Adversarial Robustness
May 05, 2021
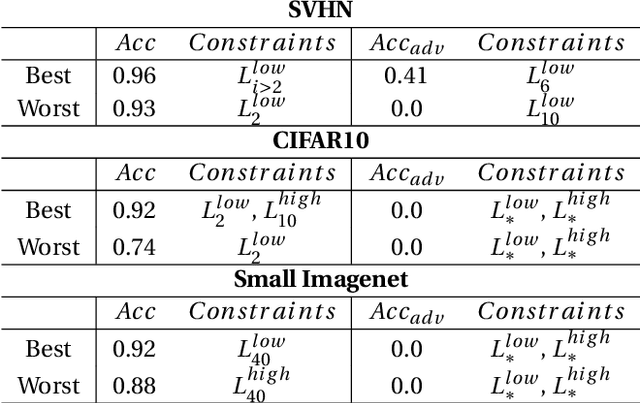
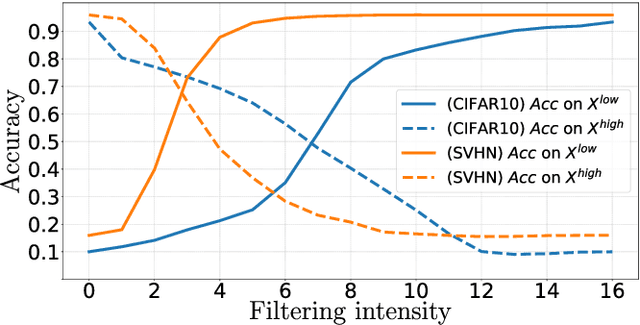
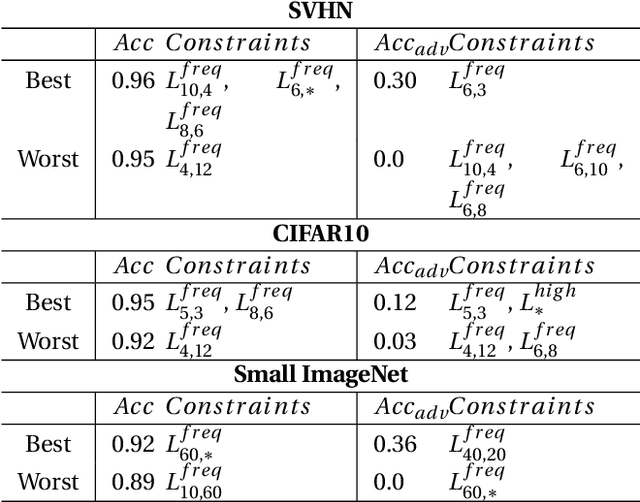
Adversarial examples mainly exploit changes to input pixels to which humans are not sensitive to, and arise from the fact that models make decisions based on uninterpretable features. Interestingly, cognitive science reports that the process of interpretability for human classification decision relies predominantly on low spatial frequency components. In this paper, we investigate the robustness to adversarial perturbations of models enforced during training to leverage information corresponding to different spatial frequency ranges. We show that it is tightly linked to the spatial frequency characteristics of the data at stake. Indeed, depending on the data set, the same constraint may results in very different level of robustness (up to 0.41 adversarial accuracy difference). To explain this phenomenon, we conduct several experiments to enlighten influential factors such as the level of sensitivity to high frequencies, and the transferability of adversarial perturbations between original and low-pass filtered inputs.
An Overview of Laser Injection against Embedded Neural Network Models
May 04, 2021



For many IoT domains, Machine Learning and more particularly Deep Learning brings very efficient solutions to handle complex data and perform challenging and mostly critical tasks. However, the deployment of models in a large variety of devices faces several obstacles related to trust and security. The latest is particularly critical since the demonstrations of severe flaws impacting the integrity, confidentiality and accessibility of neural network models. However, the attack surface of such embedded systems cannot be reduced to abstract flaws but must encompass the physical threats related to the implementation of these models within hardware platforms (e.g., 32-bit microcontrollers). Among physical attacks, Fault Injection Analysis (FIA) are known to be very powerful with a large spectrum of attack vectors. Most importantly, highly focused FIA techniques such as laser beam injection enable very accurate evaluation of the vulnerabilities as well as the robustness of embedded systems. Here, we propose to discuss how laser injection with state-of-the-art equipment, combined with theoretical evidences from Adversarial Machine Learning, highlights worrying threats against the integrity of deep learning inference and claims that join efforts from the theoretical AI and Physical Security communities are a urgent need.
A Review of Confidentiality Threats Against Embedded Neural Network Models
May 04, 2021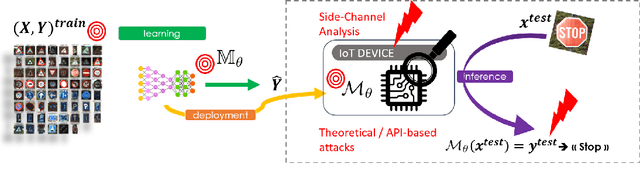


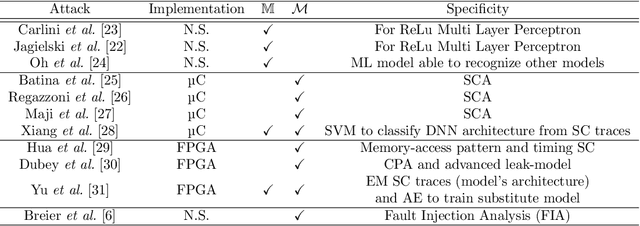
Utilization of Machine Learning (ML) algorithms, especially Deep Neural Network (DNN) models, becomes a widely accepted standard in many domains more particularly IoT-based systems. DNN models reach impressive performances in several sensitive fields such as medical diagnosis, smart transport or security threat detection, and represent a valuable piece of Intellectual Property. Over the last few years, a major trend is the large-scale deployment of models in a wide variety of devices. However, this migration to embedded systems is slowed down because of the broad spectrum of attacks threatening the integrity, confidentiality and availability of embedded models. In this review, we cover the landscape of attacks targeting the confidentiality of embedded DNN models that may have a major impact on critical IoT systems, with a particular focus on model extraction and data leakage. We highlight the fact that Side-Channel Analysis (SCA) is a relatively unexplored bias by which model's confidentiality can be compromised. Input data, architecture or parameters of a model can be extracted from power or electromagnetic observations, testifying a real need from a security point of view.
Luring of Adversarial Perturbations
Apr 10, 2020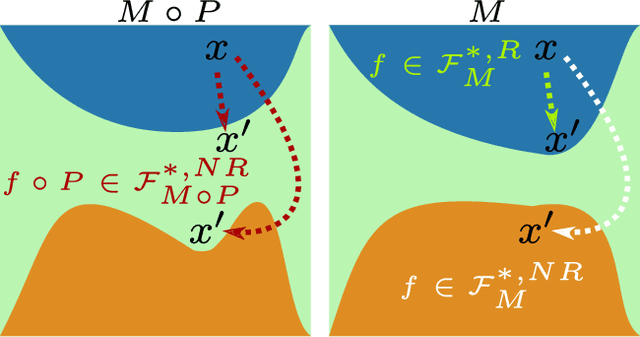
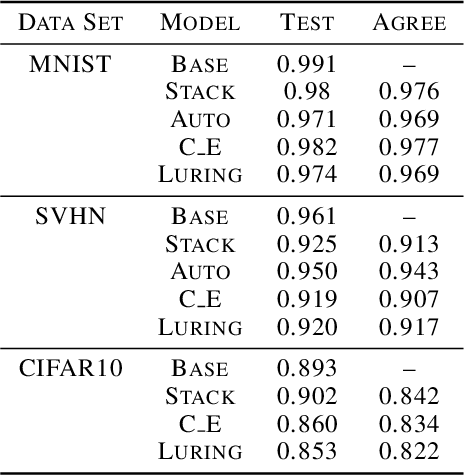

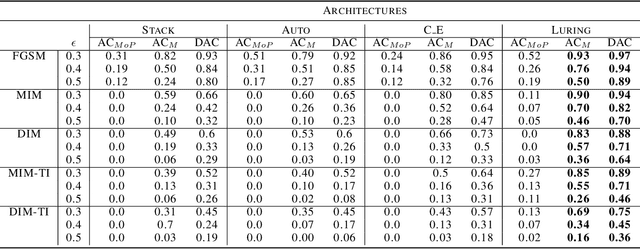
The growing interest for adversarial examples, i.e. maliciously modified examples which fool a classifier, has resulted in many defenses intended to detect them, render them inoffensive or make the model more robust against them. In this paper, we pave the way towards a new approach to defend a distant system against adversarial examples, which we name the luring of adversarial perturbations. A component is included in the target model to form an augmented and equally accurate version of it. This additional component is designed to be removable and to give false indications on the way to fool the target model alone: the adversary is tricked into fooling the augmented version of the target model, and not the target model. We explain the intuition of our defense with the principle of the luring effect, inspired by the notion of robust and non-robust features, and experimentally justify its validity. Eventually, we propose a simple prediction strategy which takes advantage of this effect, and show that our defense scheme on MNIST, SVHN and CIFAR10 can efficiently thwart an adversary using state-of-the-art attacks and allowed to perform large perturbations.
Impact of Low-bitwidth Quantization on the Adversarial Robustness for Embedded Neural Networks
Sep 27, 2019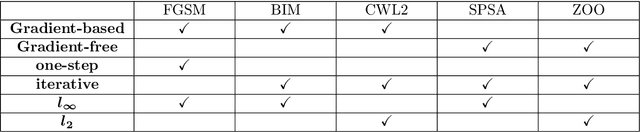
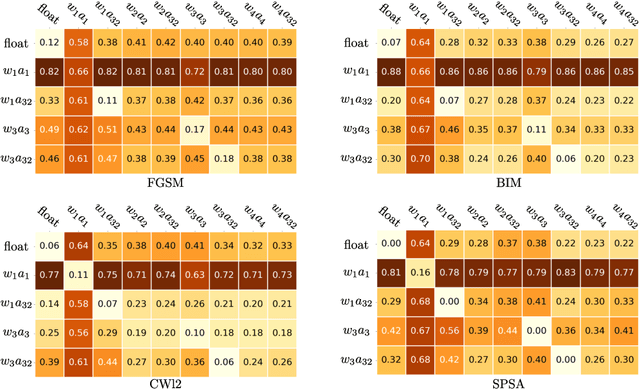

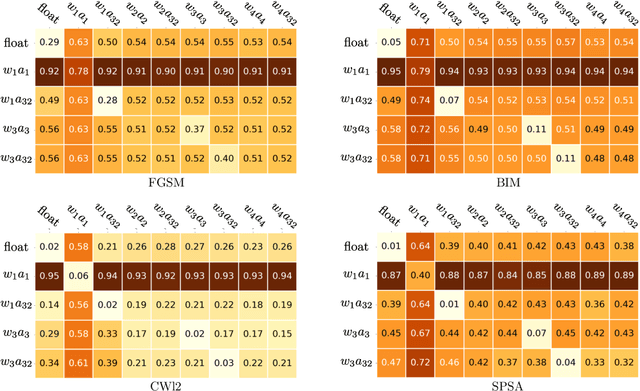
As the will to deploy neural networks models on embedded systems grows, and considering the related memory footprint and energy consumption issues, finding lighter solutions to store neural networks such as weight quantization and more efficient inference methods become major research topics. Parallel to that, adversarial machine learning has risen recently with an impressive and significant attention, unveiling some critical flaws of machine learning models, especially neural networks. In particular, perturbed inputs called adversarial examples have been shown to fool a model into making incorrect predictions. In this article, we investigate the adversarial robustness of quantized neural networks under different threat models for a classical supervised image classification task. We show that quantization does not offer any robust protection, results in severe form of gradient masking and advance some hypotheses to explain it. However, we experimentally observe poor transferability capacities which we explain by quantization value shift phenomenon and gradient misalignment and explore how these results can be exploited with an ensemble-based defense.