 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Low-bitwidth Quantization on the Adversarial Robustness for Embedded Neural Networks
Paper and Code
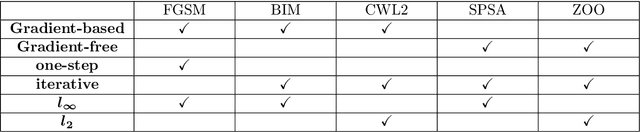
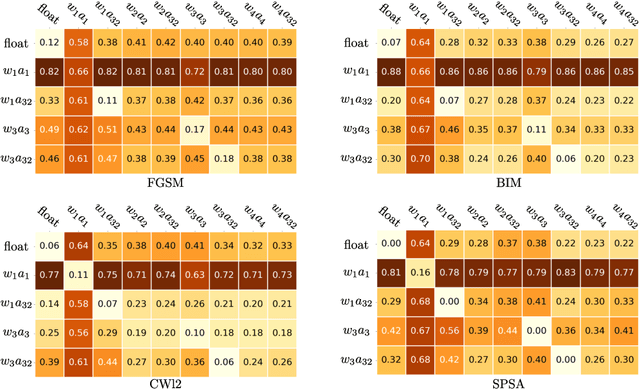

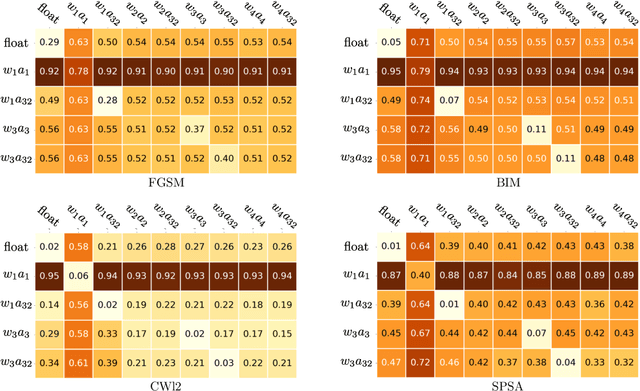
As the will to deploy neural networks models on embedded systems grows, and considering the related memory footprint and energy consumption issues, finding lighter solutions to store neural networks such as weight quantization and more efficient inference methods become major research topics. Parallel to that, adversarial machine learning has risen recently with an impressive and significant attention, unveiling some critical flaws of machine learning models, especially neural networks. In particular, perturbed inputs called adversarial examples have been shown to fool a model into making incorrect predictions. In this article, we investigate the adversarial robustness of quantized neural networks under different threat models for a classical supervised image classification task. We show that quantization does not offer any robust protection, results in severe form of gradient masking and advance some hypotheses to explain it. However, we experimentally observe poor transferability capacities which we explain by quantization value shift phenomenon and gradient misalignment and explore how these results can be exploited with an ensemble-based defense.