 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Out for the Lifespan: Evaluating Backdoor Attacks Against Federated Model Adaptation
Nov 18, 2025Large models adaptation through Federated Learning (FL) addresses a wide range of use cases and is enabled by Parameter-Efficient Fine-Tuning techniques such as Low-Rank Adaptation (LoRA). However, this distributed learning paradigm faces several security threats, particularly to its integrity, such as backdoor attacks that aim to inject malicious behavior during the local training steps of certain clients. We present the first analysis of the influence of LoRA on state-of-the-art backdoor attacks targeting model adaptation in FL. Specifically, we focus on backdoor lifespan, a critical characteristic in FL, that can vary depending on the attack scenario and the attacker's ability to effectively inject the backdoor. A key finding in our experiments is that for an optimally injected backdoor, the backdoor persistence after the attack is longer when the LoRA's rank is lower. Importantly, our work highlights evaluation issues of backdoor attacks against FL and contributes to the development of more robust and fair evaluations of backdoor attacks, enhancing the reliability of risk assessments for critical FL systems. Our code is publicly available.
Like an Open Book? Read Neural Network Architecture with Simple Power Analysis on 32-bit Microcontrollers
Nov 02, 2023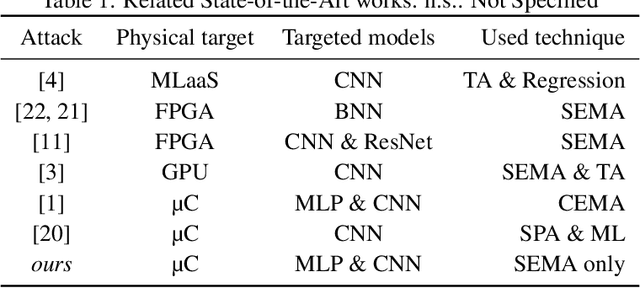
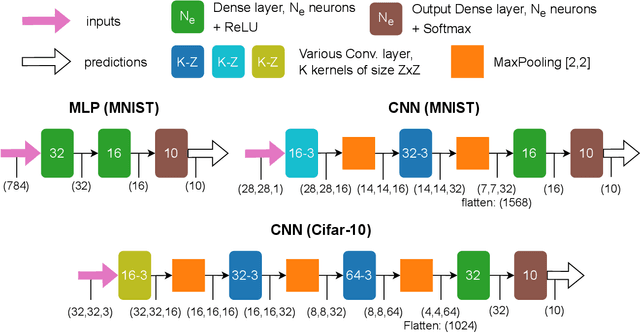

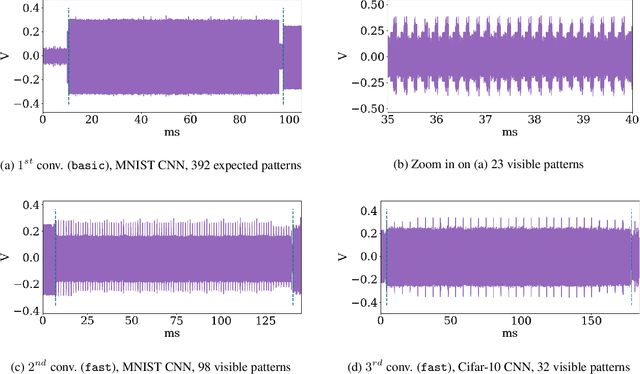
Model extraction is a growing concern for the security of AI systems. For deep neural network models, the architecture is the most important information an adversary aims to recover. Being a sequence of repeated computation blocks, neural network models deployed on edge-devices will generate distinctive side-channel leakages. The latter can be exploited to extract critical information when targeted platforms are physically accessible. By combining theoretical knowledge about deep learning practices and analysis of a widespread implementation library (ARM CMSIS-NN), our purpose is to answer this critical question: how far can we extract architecture information by simply examining an EM side-channel trace? For the first time, we propose an extraction methodology for traditional MLP and CNN models running on a high-end 32-bit microcontroller (Cortex-M7) that relies only on simple pattern recognition analysis. Despite few challenging cases, we claim that, contrary to parameters extraction, the complexity of the attack is relatively low and we highlight the urgent need for practicable protections that could fit the strong memory and latency requirements of such platforms.
Fault Injection on Embedded Neural Networks: Impact of a Single Instruction Skip
Aug 31, 2023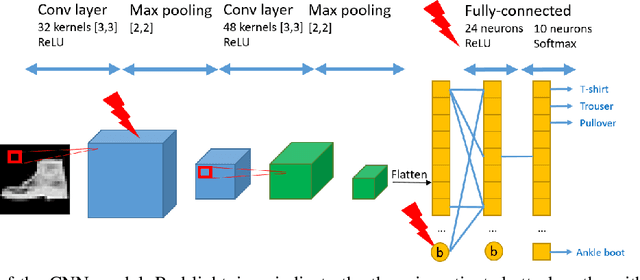
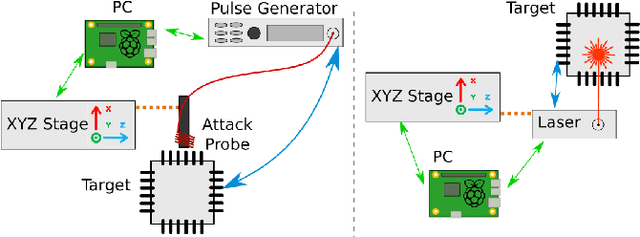

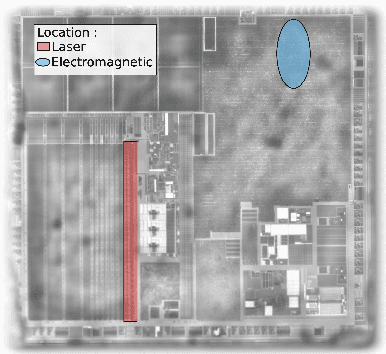
With the large-scale integration and use of neural network models, especially in critical embedded systems, their security assessment to guarantee their reliability is becoming an urgent need. More particularly, models deployed in embedded platforms, such as 32-bit microcontrollers, are physically accessible by adversaries and therefore vulnerable to hardware disturbances. We present the first set of experiments on the use of two fault injection means, electromagnetic and laser injections, applied on neural networks models embedded on a Cortex M4 32-bit microcontroller platform. Contrary to most of state-of-the-art works dedicated to the alteration of the internal parameters or input values, our goal is to simulate and experimentally demonstrate the impact of a specific fault model that is instruction skip. For that purpose, we assessed several modification attacks on the control flow of a neural network inference. We reveal integrity threats by targeting several steps in the inference program of typical convolutional neural network models, which may be exploited by an attacker to alter the predictions of the target models with different adversarial goals.
Fault Injection and Safe-Error Attack for Extraction of Embedded Neural Network Models
Aug 31, 2023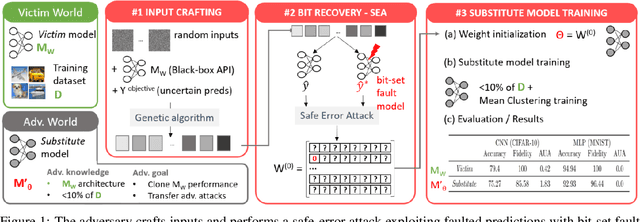

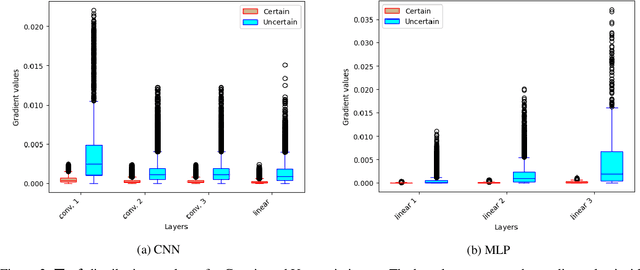
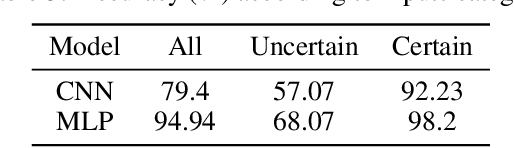
Model extraction emerges as a critical security threat with attack vectors exploiting both algorithmic and implementation-based approaches. The main goal of an attacker is to steal as much information as possible about a protected victim model, so that he can mimic it with a substitute model, even with a limited access to similar training data. Recently, physical attacks such as fault injection have shown worrying efficiency against the integrity and confidentiality of embedded models. We focus on embedded deep neural network models on 32-bit microcontrollers, a widespread family of hardware platforms in IoT, and the use of a standard fault injection strategy - Safe Error Attack (SEA) - to perform a model extraction attack with an adversary having a limited access to training data. Since the attack strongly depends on the input queries, we propose a black-box approach to craft a successful attack set. For a classical convolutional neural network, we successfully recover at least 90% of the most significant bits with about 1500 crafted inputs. These information enable to efficiently train a substitute model, with only 8% of the training dataset, that reaches high fidelity and near identical accuracy level than the victim model.
Evaluation of Parameter-based Attacks against Embedded Neural Networks with Laser Injection
Apr 25, 2023Upcoming certification actions related to the security of machine learning (ML) based systems raise major evaluation challenges that are amplified by the large-scale deployment of models in many hardware platforms. Until recently, most of research works focused on API-based attacks that consider a ML model as a pure algorithmic abstraction. However, new implementation-based threats have been revealed, emphasizing the urgency to propose both practical and simulation-based methods to properly evaluate the robustness of models. A major concern is parameter-based attacks (such as the Bit-Flip Attack, BFA) that highlight the lack of robustness of typical deep neural network models when confronted by accurate and optimal alterations of their internal parameters stored in memory. Setting in a security testing purpose, this work practically reports, for the first time, a successful variant of the BFA on a 32-bit Cortex-M microcontroller using laser fault injection. It is a standard fault injection means for security evaluation, that enables to inject spatially and temporally accurate faults. To avoid unrealistic brute-force strategies, we show how simulations help selecting the most sensitive set of bits from the parameters taking into account the laser fault model.
Evaluation of Convolution Primitives for Embedded Neural Networks on 32-bit Microcontrollers
Mar 19, 2023Deploying neural networks on constrained hardware platforms such as 32-bit microcontrollers is a challenging task because of the large memory, computing and energy requirements of their inference process. To tackle these issues, several convolution primitives have been proposed to make the standard convolution more computationally efficient. However, few of these primitives are really implemented for 32-bit microcontrollers. In this work, we collect different state-of-the-art convolutional primitives and propose an implementation for ARM Cortex-M processor family with an open source deployment platform (NNoM). Then, we carry out experimental characterization tests on these implementations. Our benchmark reveals a linear relationship between theoretical MACs and energy consumption. Thus showing the advantages of using computationally efficient primitives like shift convolution. We discuss about the significant reduction in latency and energy consumption due to the use of SIMD instructions and highlight the importance of data reuse in those performance gains. For reproducibility purpose and further experiments, codes and experiments are publicly available.
A Practical Introduction to Side-Channel Extraction of Deep Neural Network Parameters
Nov 10, 2022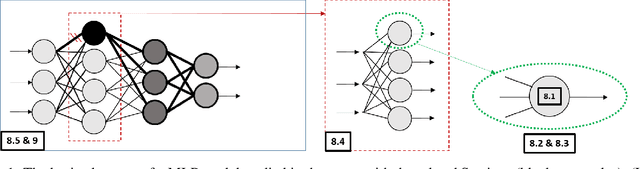


Model extraction is a major threat for embedded deep neural network models that leverages an extended attack surface. Indeed, by physically accessing a device, an adversary may exploit side-channel leakages to extract critical information of a model (i.e., its architecture or internal parameters). Different adversarial objectives are possible including a fidelity-based scenario where the architecture and parameters are precisely extracted (model cloning). We focus this work on software implementation of deep neural networks embedded in a high-end 32-bit microcontroller (Cortex-M7) and expose several challenges related to fidelity-based parameters extraction through side-channel analysis, from the basic multiplication operation to the feed-forward connection through the layers. To precisely extract the value of parameters represented in the single-precision floating point IEEE-754 standard, we propose an iterative process that is evaluated with both simulations and traces from a Cortex-M7 target. To our knowledge, this work is the first to target such an high-end 32-bit platform. Importantly, we raise and discuss the remaining challenges for the complete extraction of a deep neural network model, more particularly the critical case of biases.
A Closer Look at Evaluating the Bit-Flip Attack Against Deep Neural Networks
Sep 30, 2022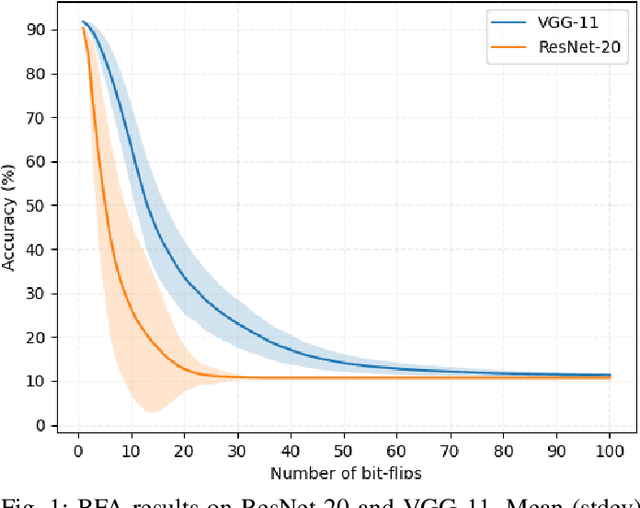
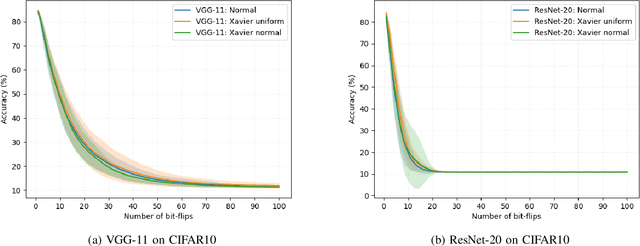
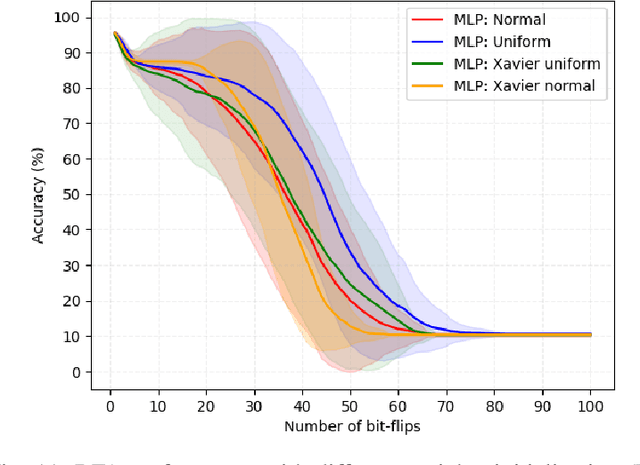

Deep neural network models are massively deployed on a wide variety of hardware platforms. This results in the appearance of new attack vectors that significantly extend the standard attack surface, extensively studied by the adversarial machine learning community. One of the first attack that aims at drastically dropping the performance of a model, by targeting its parameters (weights) stored in memory, is the Bit-Flip Attack (BFA). In this work, we point out several evaluation challenges related to the BFA. First of all, the lack of an adversary's budget in the standard threat model is problematic, especially when dealing with physical attacks. Moreover, since the BFA presents critical variability, we discuss the influence of some training parameters and the importance of the model architecture. This work is the first to present the impact of the BFA against fully-connected architectures that present different behaviors compared to convolutional neural networks. These results highlight the importance of defining robust and sound evaluation methodologies to properly evaluate the dangers of parameter-based attacks as well as measure the real level of robustness offered by a defense.
Impact of Spatial Frequency Based Constraints on Adversarial Robustness
May 05, 2021
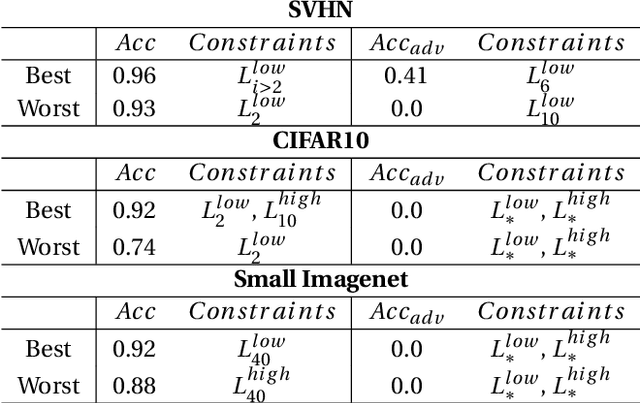
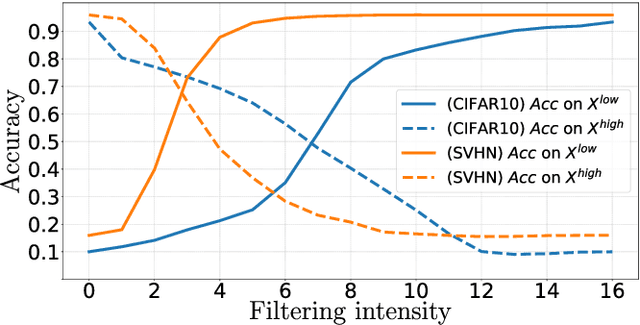
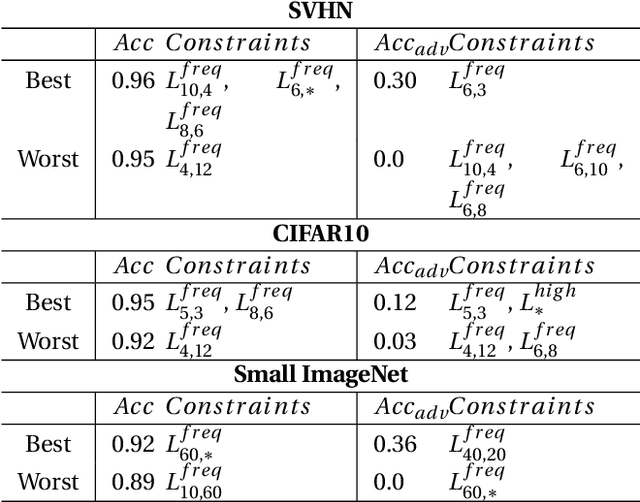
Adversarial examples mainly exploit changes to input pixels to which humans are not sensitive to, and arise from the fact that models make decisions based on uninterpretable features. Interestingly, cognitive science reports that the process of interpretability for human classification decision relies predominantly on low spatial frequency components. In this paper, we investigate the robustness to adversarial perturbations of models enforced during training to leverage information corresponding to different spatial frequency ranges. We show that it is tightly linked to the spatial frequency characteristics of the data at stake. Indeed, depending on the data set, the same constraint may results in very different level of robustness (up to 0.41 adversarial accuracy difference). To explain this phenomenon, we conduct several experiments to enlighten influential factors such as the level of sensitivity to high frequencies, and the transferability of adversarial perturbations between original and low-pass filtered inputs.
An Overview of Laser Injection against Embedded Neural Network Models
May 04, 2021



For many IoT domains, Machine Learning and more particularly Deep Learning brings very efficient solutions to handle complex data and perform challenging and mostly critical tasks. However, the deployment of models in a large variety of devices faces several obstacles related to trust and security. The latest is particularly critical since the demonstrations of severe flaws impacting the integrity, confidentiality and accessibility of neural network models. However, the attack surface of such embedded systems cannot be reduced to abstract flaws but must encompass the physical threats related to the implementation of these models within hardware platforms (e.g., 32-bit microcontrollers). Among physical attacks, Fault Injection Analysis (FIA) are known to be very powerful with a large spectrum of attack vectors. Most importantly, highly focused FIA techniques such as laser beam injection enable very accurate evaluation of the vulnerabilities as well as the robustness of embedded systems. Here, we propose to discuss how laser injection with state-of-the-art equipment, combined with theoretical evidences from Adversarial Machine Learning, highlights worrying threats against the integrity of deep learning inference and claims that join efforts from the theoretical AI and Physical Security communities are a urgent need.