 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Out for the Lifespan: Evaluating Backdoor Attacks Against Federated Model Adaptation
Nov 18, 2025Large models adaptation through Federated Learning (FL) addresses a wide range of use cases and is enabled by Parameter-Efficient Fine-Tuning techniques such as Low-Rank Adaptation (LoRA). However, this distributed learning paradigm faces several security threats, particularly to its integrity, such as backdoor attacks that aim to inject malicious behavior during the local training steps of certain clients. We present the first analysis of the influence of LoRA on state-of-the-art backdoor attacks targeting model adaptation in FL. Specifically, we focus on backdoor lifespan, a critical characteristic in FL, that can vary depending on the attack scenario and the attacker's ability to effectively inject the backdoor. A key finding in our experiments is that for an optimally injected backdoor, the backdoor persistence after the attack is longer when the LoRA's rank is lower. Importantly, our work highlights evaluation issues of backdoor attacks against FL and contributes to the development of more robust and fair evaluations of backdoor attacks, enhancing the reliability of risk assessments for critical FL systems. Our code is publicly available.
Fault Injection on Embedded Neural Networks: Impact of a Single Instruction Skip
Aug 31, 2023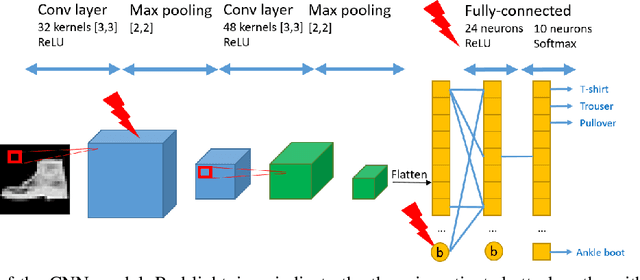
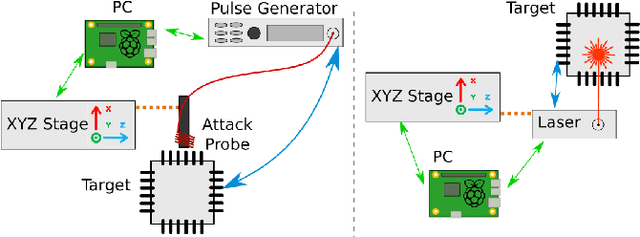

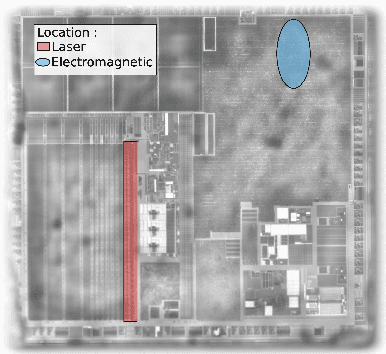
With the large-scale integration and use of neural network models, especially in critical embedded systems, their security assessment to guarantee their reliability is becoming an urgent need. More particularly, models deployed in embedded platforms, such as 32-bit microcontrollers, are physically accessible by adversaries and therefore vulnerable to hardware disturbances. We present the first set of experiments on the use of two fault injection means, electromagnetic and laser injections, applied on neural networks models embedded on a Cortex M4 32-bit microcontroller platform. Contrary to most of state-of-the-art works dedicated to the alteration of the internal parameters or input values, our goal is to simulate and experimentally demonstrate the impact of a specific fault model that is instruction skip. For that purpose, we assessed several modification attacks on the control flow of a neural network inference. We reveal integrity threats by targeting several steps in the inference program of typical convolutional neural network models, which may be exploited by an attacker to alter the predictions of the target models with different adversarial goals.
Fault Injection and Safe-Error Attack for Extraction of Embedded Neural Network Models
Aug 31, 2023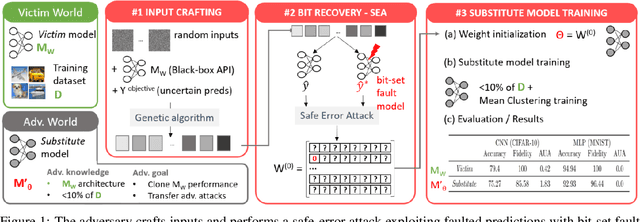

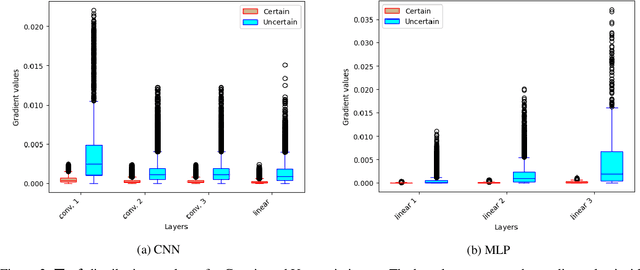
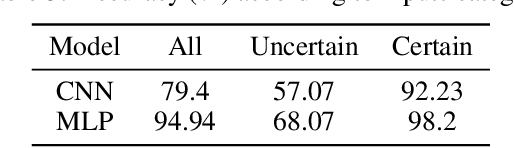
Model extraction emerges as a critical security threat with attack vectors exploiting both algorithmic and implementation-based approaches. The main goal of an attacker is to steal as much information as possible about a protected victim model, so that he can mimic it with a substitute model, even with a limited access to similar training data. Recently, physical attacks such as fault injection have shown worrying efficiency against the integrity and confidentiality of embedded models. We focus on embedded deep neural network models on 32-bit microcontrollers, a widespread family of hardware platforms in IoT, and the use of a standard fault injection strategy - Safe Error Attack (SEA) - to perform a model extraction attack with an adversary having a limited access to training data. Since the attack strongly depends on the input queries, we propose a black-box approach to craft a successful attack set. For a classical convolutional neural network, we successfully recover at least 90% of the most significant bits with about 1500 crafted inputs. These information enable to efficiently train a substitute model, with only 8% of the training dataset, that reaches high fidelity and near identical accuracy level than the victim model.
Evaluation of Parameter-based Attacks against Embedded Neural Networks with Laser Injection
Apr 25, 2023Upcoming certification actions related to the security of machine learning (ML) based systems raise major evaluation challenges that are amplified by the large-scale deployment of models in many hardware platforms. Until recently, most of research works focused on API-based attacks that consider a ML model as a pure algorithmic abstraction. However, new implementation-based threats have been revealed, emphasizing the urgency to propose both practical and simulation-based methods to properly evaluate the robustness of models. A major concern is parameter-based attacks (such as the Bit-Flip Attack, BFA) that highlight the lack of robustness of typical deep neural network models when confronted by accurate and optimal alterations of their internal parameters stored in memory. Setting in a security testing purpose, this work practically reports, for the first time, a successful variant of the BFA on a 32-bit Cortex-M microcontroller using laser fault injection. It is a standard fault injection means for security evaluation, that enables to inject spatially and temporally accurate faults. To avoid unrealistic brute-force strategies, we show how simulations help selecting the most sensitive set of bits from the parameters taking into account the laser fault model.
A Closer Look at Evaluating the Bit-Flip Attack Against Deep Neural Networks
Sep 30, 2022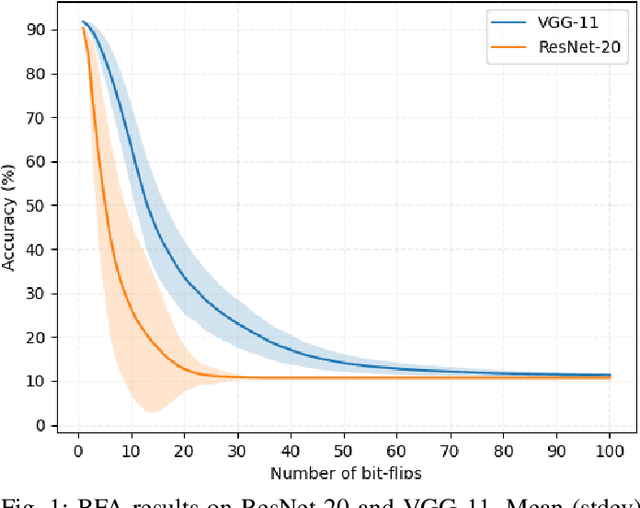
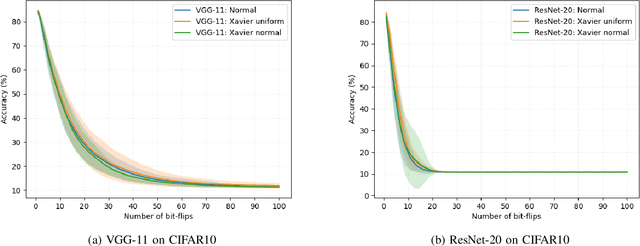
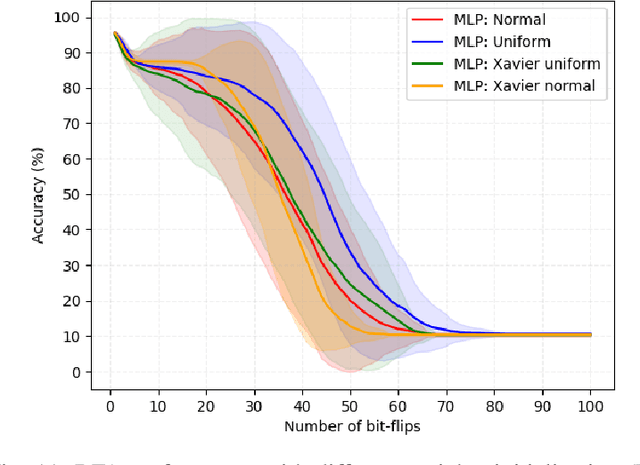

Deep neural network models are massively deployed on a wide variety of hardware platforms. This results in the appearance of new attack vectors that significantly extend the standard attack surface, extensively studied by the adversarial machine learning community. One of the first attack that aims at drastically dropping the performance of a model, by targeting its parameters (weights) stored in memory, is the Bit-Flip Attack (BFA). In this work, we point out several evaluation challenges related to the BFA. First of all, the lack of an adversary's budget in the standard threat model is problematic, especially when dealing with physical attacks. Moreover, since the BFA presents critical variability, we discuss the influence of some training parameters and the importance of the model architecture. This work is the first to present the impact of the BFA against fully-connected architectures that present different behaviors compared to convolutional neural networks. These results highlight the importance of defining robust and sound evaluation methodologies to properly evaluate the dangers of parameter-based attacks as well as measure the real level of robustness offered by a defense.
An Overview of Laser Injection against Embedded Neural Network Models
May 04, 2021



For many IoT domains, Machine Learning and more particularly Deep Learning brings very efficient solutions to handle complex data and perform challenging and mostly critical tasks. However, the deployment of models in a large variety of devices faces several obstacles related to trust and security. The latest is particularly critical since the demonstrations of severe flaws impacting the integrity, confidentiality and accessibility of neural network models. However, the attack surface of such embedded systems cannot be reduced to abstract flaws but must encompass the physical threats related to the implementation of these models within hardware platforms (e.g., 32-bit microcontrollers). Among physical attacks, Fault Injection Analysis (FIA) are known to be very powerful with a large spectrum of attack vectors. Most importantly, highly focused FIA techniques such as laser beam injection enable very accurate evaluation of the vulnerabilities as well as the robustness of embedded systems. Here, we propose to discuss how laser injection with state-of-the-art equipment, combined with theoretical evidences from Adversarial Machine Learning, highlights worrying threats against the integrity of deep learning inference and claims that join efforts from the theoretical AI and Physical Security communities are a urgent need.
Luring of Adversarial Perturbations
Apr 10, 2020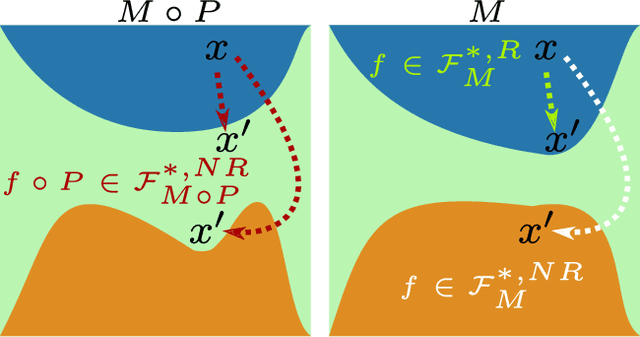
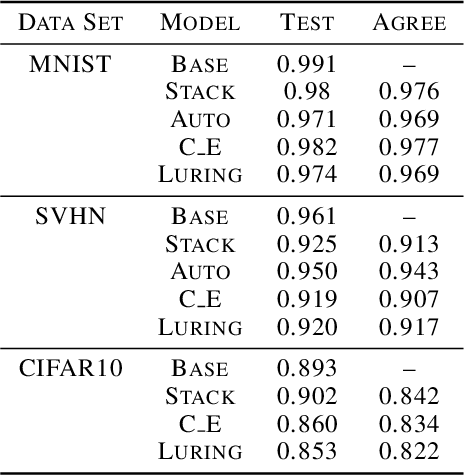

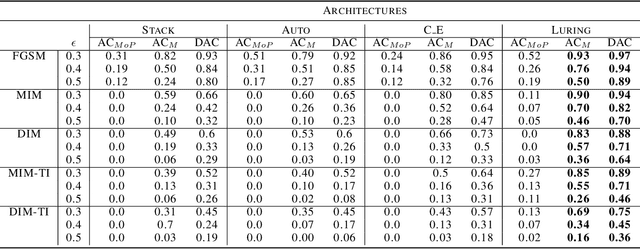
The growing interest for adversarial examples, i.e. maliciously modified examples which fool a classifier, has resulted in many defenses intended to detect them, render them inoffensive or make the model more robust against them. In this paper, we pave the way towards a new approach to defend a distant system against adversarial examples, which we name the luring of adversarial perturbations. A component is included in the target model to form an augmented and equally accurate version of it. This additional component is designed to be removable and to give false indications on the way to fool the target model alone: the adversary is tricked into fooling the augmented version of the target model, and not the target model. We explain the intuition of our defense with the principle of the luring effect, inspired by the notion of robust and non-robust features, and experimentally justify its validity. Eventually, we propose a simple prediction strategy which takes advantage of this effect, and show that our defense scheme on MNIST, SVHN and CIFAR10 can efficiently thwart an adversary using state-of-the-art attacks and allowed to perform large perturbations.
Impact of Low-bitwidth Quantization on the Adversarial Robustness for Embedded Neural Networks
Sep 27, 2019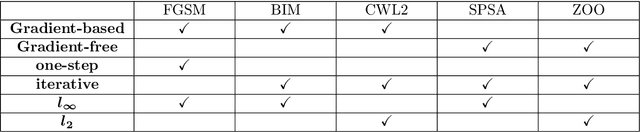
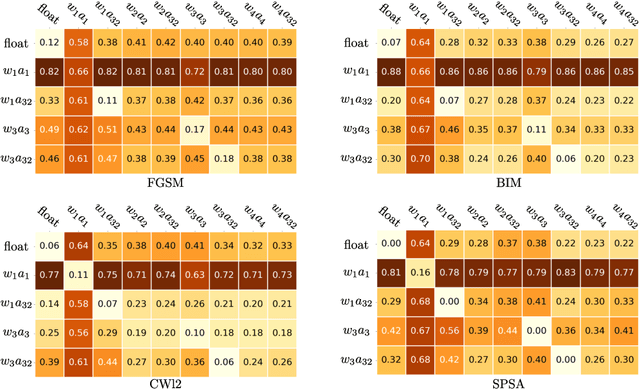

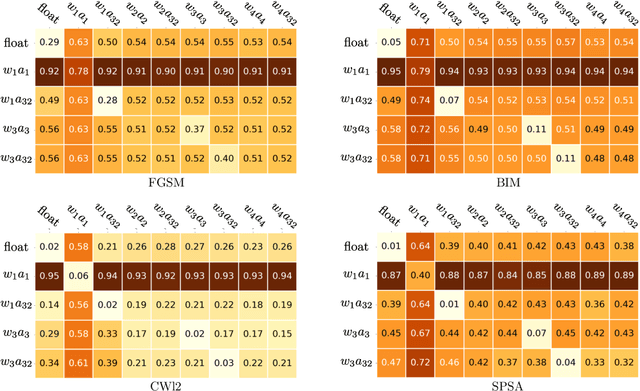
As the will to deploy neural networks models on embedded systems grows, and considering the related memory footprint and energy consumption issues, finding lighter solutions to store neural networks such as weight quantization and more efficient inference methods become major research topics. Parallel to that, adversarial machine learning has risen recently with an impressive and significant attention, unveiling some critical flaws of machine learning models, especially neural networks. In particular, perturbed inputs called adversarial examples have been shown to fool a model into making incorrect predictions. In this article, we investigate the adversarial robustness of quantized neural networks under different threat models for a classical supervised image classification task. We show that quantization does not offer any robust protection, results in severe form of gradient masking and advance some hypotheses to explain it. However, we experimentally observe poor transferability capacities which we explain by quantization value shift phenomenon and gradient misalignment and explore how these results can be exploited with an ensemble-based defense.