 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Injection and Safe-Error Attack for Extraction of Embedded Neural Network Models
Aug 31, 2023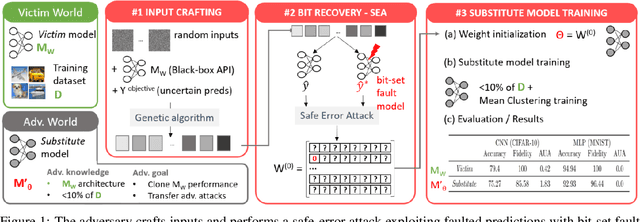

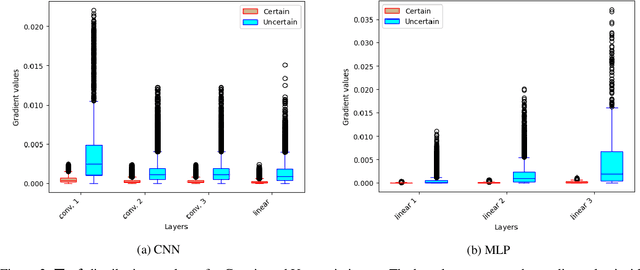
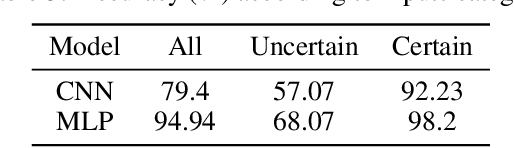
Model extraction emerges as a critical security threat with attack vectors exploiting both algorithmic and implementation-based approaches. The main goal of an attacker is to steal as much information as possible about a protected victim model, so that he can mimic it with a substitute model, even with a limited access to similar training data. Recently, physical attacks such as fault injection have shown worrying efficiency against the integrity and confidentiality of embedded models. We focus on embedded deep neural network models on 32-bit microcontrollers, a widespread family of hardware platforms in IoT, and the use of a standard fault injection strategy - Safe Error Attack (SEA) - to perform a model extraction attack with an adversary having a limited access to training data. Since the attack strongly depends on the input queries, we propose a black-box approach to craft a successful attack set. For a classical convolutional neural network, we successfully recover at least 90% of the most significant bits with about 1500 crafted inputs. These information enable to efficiently train a substitute model, with only 8% of the training dataset, that reaches high fidelity and near identical accuracy level than the victim model.
Evaluation of Parameter-based Attacks against Embedded Neural Networks with Laser Injection
Apr 25, 2023Upcoming certification actions related to the security of machine learning (ML) based systems raise major evaluation challenges that are amplified by the large-scale deployment of models in many hardware platforms. Until recently, most of research works focused on API-based attacks that consider a ML model as a pure algorithmic abstraction. However, new implementation-based threats have been revealed, emphasizing the urgency to propose both practical and simulation-based methods to properly evaluate the robustness of models. A major concern is parameter-based attacks (such as the Bit-Flip Attack, BFA) that highlight the lack of robustness of typical deep neural network models when confronted by accurate and optimal alterations of their internal parameters stored in memory. Setting in a security testing purpose, this work practically reports, for the first time, a successful variant of the BFA on a 32-bit Cortex-M microcontroller using laser fault injection. It is a standard fault injection means for security evaluation, that enables to inject spatially and temporally accurate faults. To avoid unrealistic brute-force strategies, we show how simulations help selecting the most sensitive set of bits from the parameters taking into account the laser fault model.
A Closer Look at Evaluating the Bit-Flip Attack Against Deep Neural Networks
Sep 30, 2022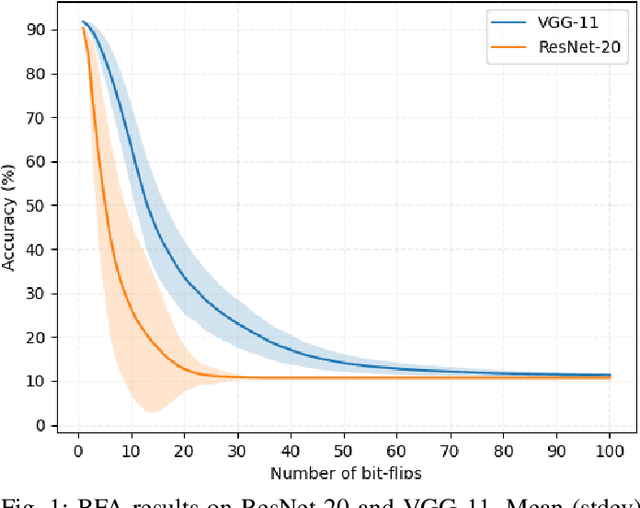
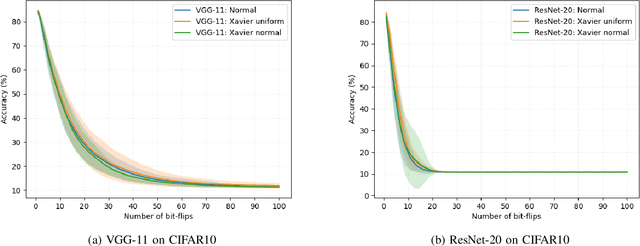
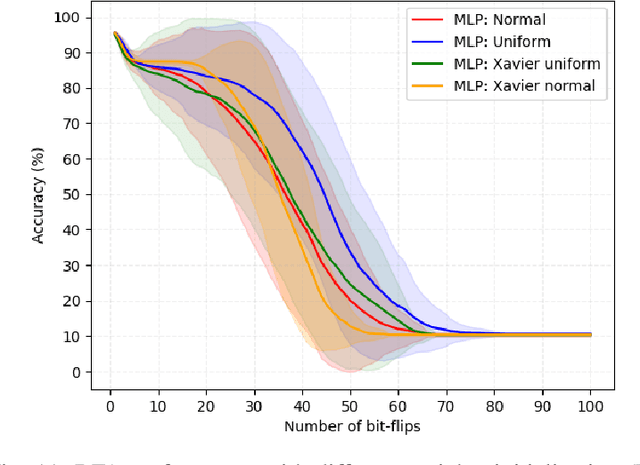

Deep neural network models are massively deployed on a wide variety of hardware platforms. This results in the appearance of new attack vectors that significantly extend the standard attack surface, extensively studied by the adversarial machine learning community. One of the first attack that aims at drastically dropping the performance of a model, by targeting its parameters (weights) stored in memory, is the Bit-Flip Attack (BFA). In this work, we point out several evaluation challenges related to the BFA. First of all, the lack of an adversary's budget in the standard threat model is problematic, especially when dealing with physical attacks. Moreover, since the BFA presents critical variability, we discuss the influence of some training parameters and the importance of the model architecture. This work is the first to present the impact of the BFA against fully-connected architectures that present different behaviors compared to convolutional neural networks. These results highlight the importance of defining robust and sound evaluation methodologies to properly evaluate the dangers of parameter-based attacks as well as measure the real level of robustness offered by a defense.