 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuring of Adversarial Perturbations
Paper and Code
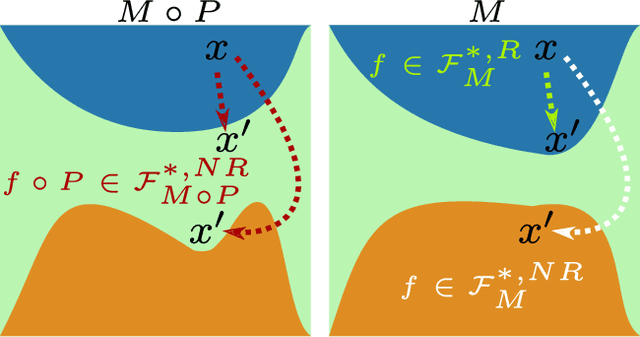
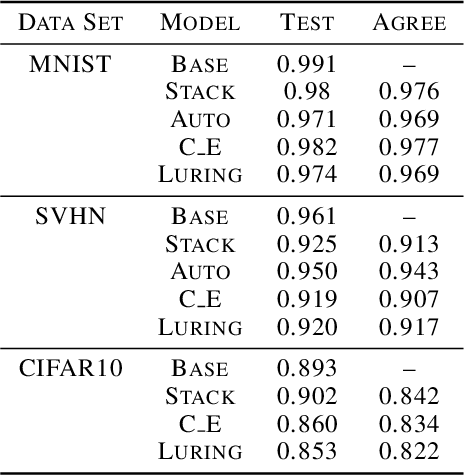

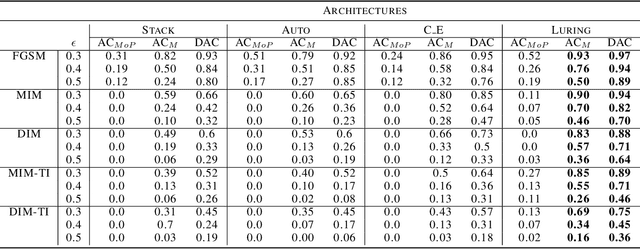
The growing interest for adversarial examples, i.e. maliciously modified examples which fool a classifier, has resulted in many defenses intended to detect them, render them inoffensive or make the model more robust against them. In this paper, we pave the way towards a new approach to defend a distant system against adversarial examples, which we name the luring of adversarial perturbations. A component is included in the target model to form an augmented and equally accurate version of it. This additional component is designed to be removable and to give false indications on the way to fool the target model alone: the adversary is tricked into fooling the augmented version of the target model, and not the target model. We explain the intuition of our defense with the principle of the luring effect, inspired by the notion of robust and non-robust features, and experimentally justify its validity. Eventually, we propose a simple prediction strategy which takes advantage of this effect, and show that our defense scheme on MNIST, SVHN and CIFAR10 can efficiently thwart an adversary using state-of-the-art attacks and allowed to perform large perturbations.