 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Guidance: World Modeling in Condition Space for Action Generation
Feb 25, 2026Leveraging future observation modeling to facilitate action generation presents a promising avenue for enhancing the capabilities of Vision-Language-Action (VLA) models. However, existing approaches struggle to strike a balance between maintaining efficient, predictable future representations and preserving sufficient fine-grained information to guide precise action generation. To address this limitation, we propose WoG (World Guidance), a framework that maps future observations into compact conditions by injecting them into the action inference pipeline. The VLA is then trained to simultaneously predict these compressed conditions alongside future actions, thereby achieving effective world modeling within the condition space for action inference. We demonstrate that modeling and predicting this condition space not only facilitates fine-grained action generation but also exhibits superior generalization capabilities. Moreover, it learns effectively from substantial human manipulation videos. Extensive experiments across both simulation and real-world environments validate that our method significantly outperforms existing methods based on future prediction. Project page is available at: https://selen-suyue.github.io/WoGNet/
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
May 10, 2024



We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
Two-level Data Augmentation for Calibrated Multi-view Detection
Oct 19, 2022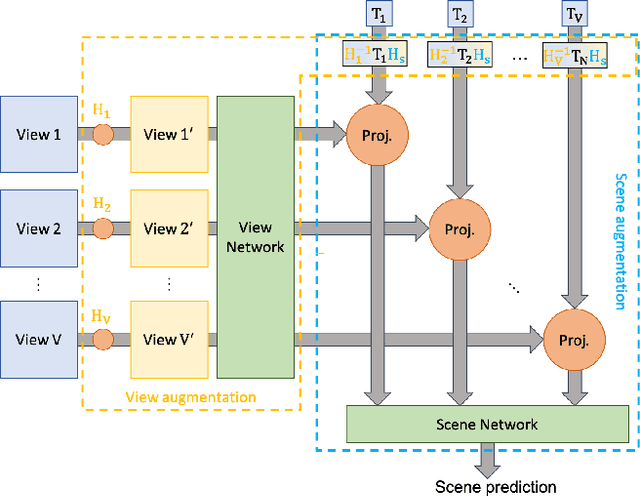
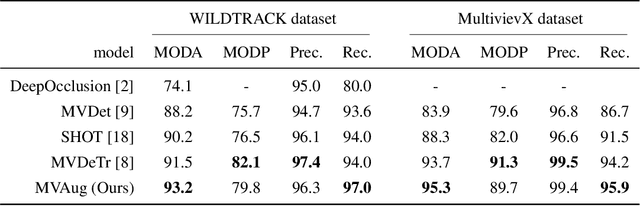


Data augmentation has proven its usefulness to improve model generalization and performance. While it is commonly applied in computer vision application when it comes to multi-view systems, it is rarely used. Indeed geometric data augmentation can break the alignment among views. This is problematic since multi-view data tend to be scarce and it is expensive to annotate. In this work we propose to solve this issue by introducing a new multi-view data augmentation pipeline that preserves alignment among views. Additionally to traditional augmentation of the input image we also propose a second level of augmentation applied directly at the scene level. When combined with our simple multi-view detection model, our two-level augmentation pipeline outperforms all existing baselines by a significant margin on the two main multi-view multi-person detection datasets WILDTRACK and MultiviewX.