 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing the Elephant in the Room: Robust Animal Re-Identification with Unsupervised Part-Based Feature Alignment
May 22, 2024



Animal Re-ID is crucial for wildlife conservation, yet it faces unique challenges compared to person Re-ID. First, the scarcity and lack of diversity in datasets lead to background-biased models. Second, animal Re-ID depends on subtle, species-specific cues, further complicated by variations in pose, background, and lighting. This study addresses background biases by proposing a method to systematically remove backgrounds in both training and evaluation phases. And unlike prior works that depend on pose annotations, our approach utilizes an unsupervised technique for feature alignment across body parts and pose variations, enhancing practicality. Our method achieves superior results on three key animal Re-ID datasets: ATRW, YakReID-103, and ELPephants.
CLOAF: CoLlisiOn-Aware Human Flow
Mar 14, 2024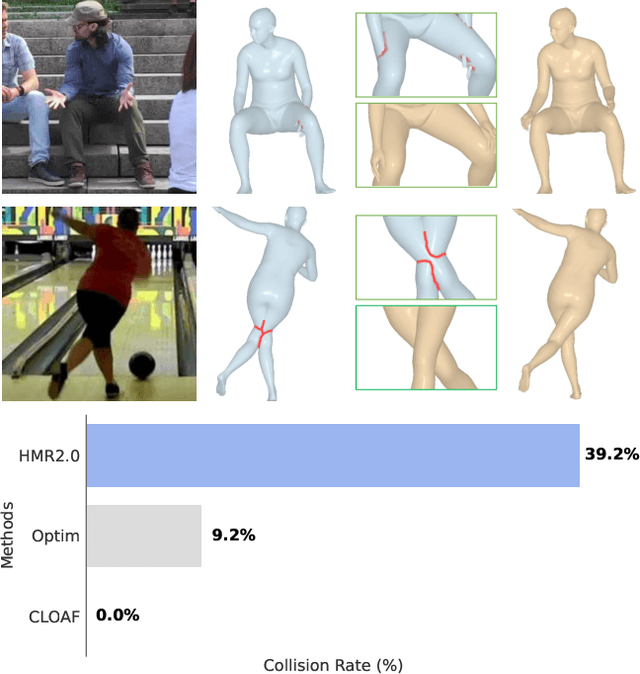
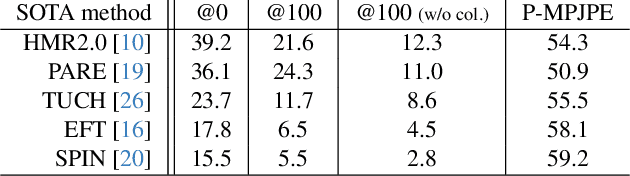


Even the best current algorithms for estimating body 3D shape and pose yield results that include body self-intersections. In this paper, we present CLOAF, which exploits the diffeomorphic nature of Ordinary Differential Equations to eliminate such self-intersections while still imposing body shape constraints. We show that, unlike earlier approaches to addressing this issue, ours completely eliminates the self-intersections without compromising the accuracy of the reconstructions. Being differentiable, CLOAF can be used to fine-tune pose and shape estimation baselines to improve their overall performance and eliminate self-intersections in their predictions. Furthermore, we demonstrate how our CLOAF strategy can be applied to practically any motion field induced by the user. CLOAF also makes it possible to edit motion to interact with the environment without worrying about potential collision or loss of body-shape prior.
Using Motion Cues to Supervise Single-Frame Body Pose and Shape Estimation in Low Data Regimes
Feb 05, 2024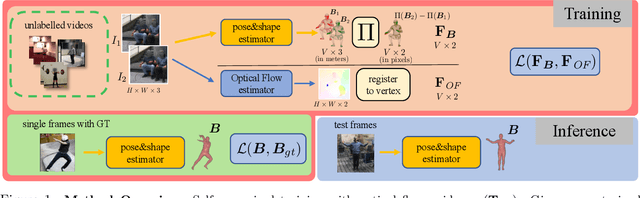
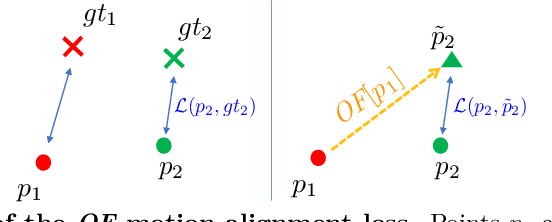
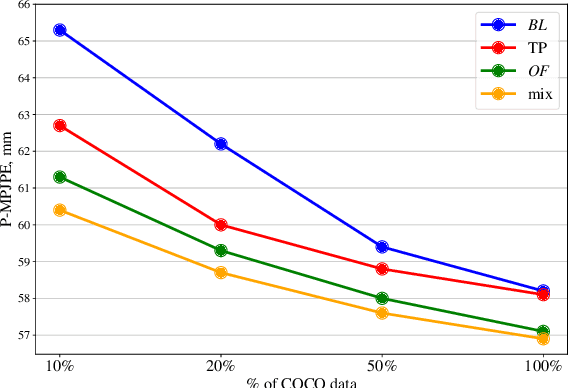
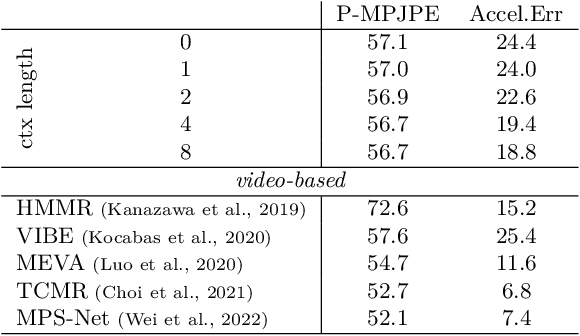
When enough annotated training data is available, supervised deep-learning algorithms excel at estimating human body pose and shape using a single camera. The effects of too little such data being available can be mitigated by using other information sources, such as databases of body shapes, to learn priors. Unfortunately, such sources are not always available either. We show that, in such cases, easy-to-obtain unannotated videos can be used instead to provide the required supervisory signals. Given a trained model using too little annotated data, we compute poses in consecutive frames along with the optical flow between them. We then enforce consistency between the image optical flow and the one that can be inferred from the change in pose from one frame to the next. This provides enough additional supervision to effectively refine the network weights and to perform on par with methods trained using far more annotated data.
Adversarial Parametric Pose Prior
Dec 08, 2021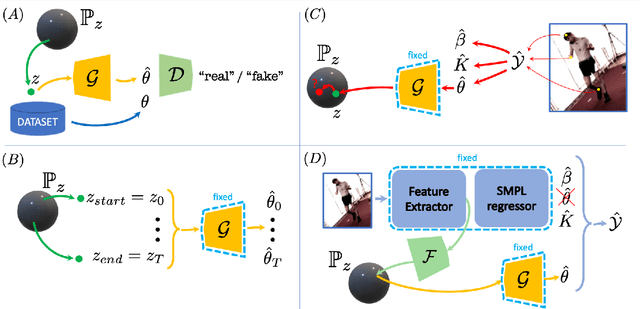
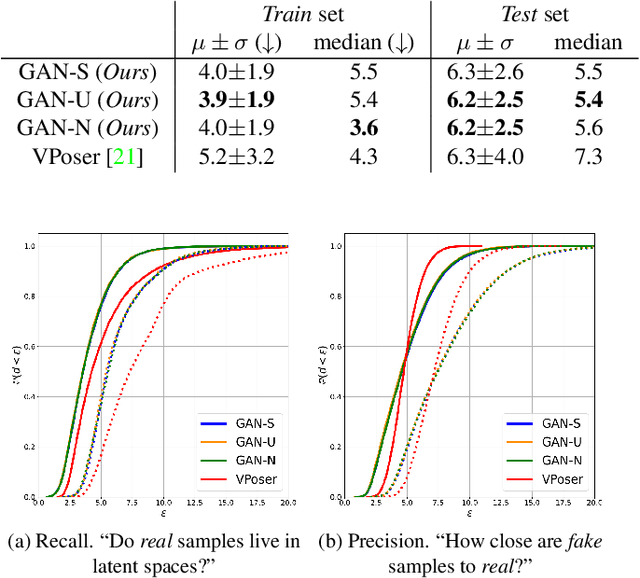
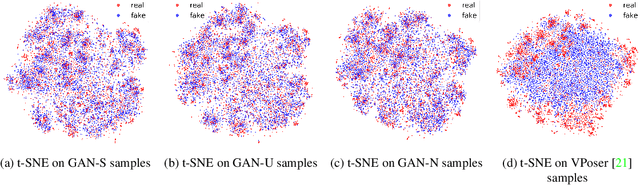
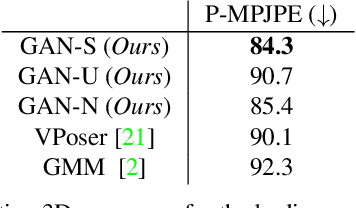
The Skinned Multi-Person Linear (SMPL) model can represent a human body by mapping pose and shape parameters to body meshes. This has been shown to facilitate inferring 3D human pose and shape from images via different learning models. However, not all pose and shape parameter values yield physically-plausible or even realistic body meshes. In other words, SMPL is under-constrained and may thus lead to invalid results when used to reconstruct humans from images, either by directly optimizing its parameters, or by learning a mapping from the image to these parameters. In this paper, we therefore learn a prior that restricts the SMPL parameters to values that produce realistic poses via adversarial training. We show that our learned prior covers the diversity of the real-data distribution, facilitates optimization for 3D reconstruction from 2D keypoints, and yields better pose estimates when used for regression from images. We found that the prior based on spherical distribution gets the best results. Furthermore, in all these tasks, it outperforms the state-of-the-art VAE-based approach to constraining the SMPL parameters.