 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Information Sub-Selection for Decision Support
Oct 30, 2024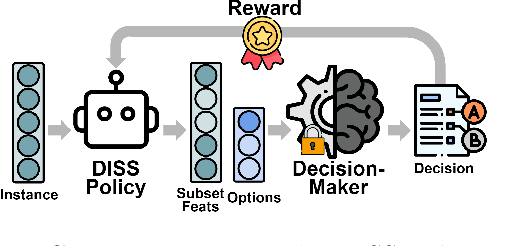
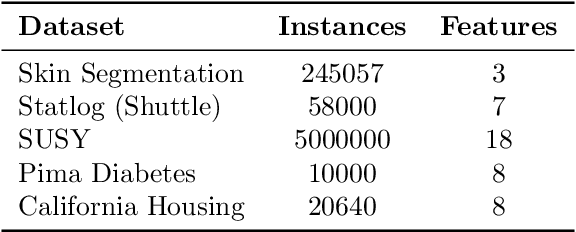
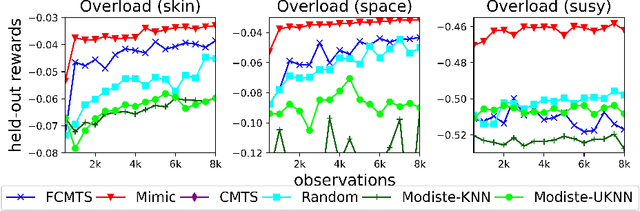
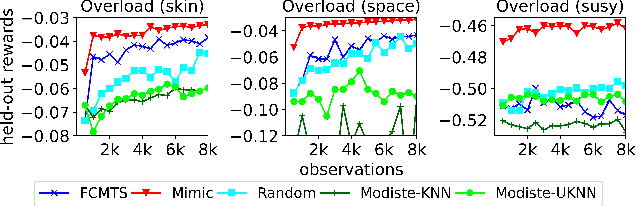
We introduce Dynamic Information Sub-Selection (DISS), a novel framework of AI assistance designed to enhance the performance of black-box decision-makers by tailoring their information processing on a per-instance basis. Blackbox decision-makers (e.g., humans or real-time systems) often face challenges in processing all possible information at hand (e.g., due to cognitive biases or resource constraints), which can degrade decision efficacy. DISS addresses these challenges through policies that dynamically select the most effective features and options to forward to the black-box decision-maker for prediction. We develop a scalable frequentist data acquisition strategy and a decision-maker mimicking technique for enhanced budget efficiency. We explore several impactful applications of DISS, including biased decision-maker support, expert assignment optimization, large language model decision support, and interpretability. Empirical validation of our proposed DISS methodology shows superior performance to state-of-the-art methods across various applications.
Phoneme Hallucinator: One-shot Voice Conversion via Set Expansion
Aug 11, 2023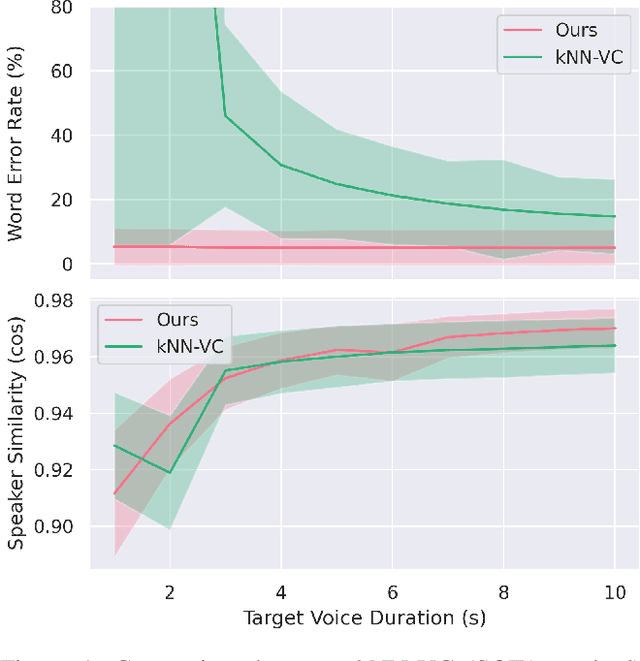
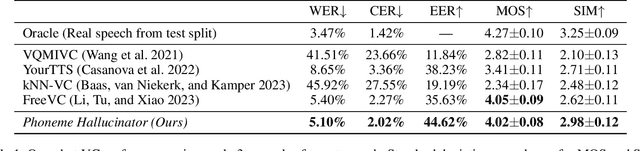
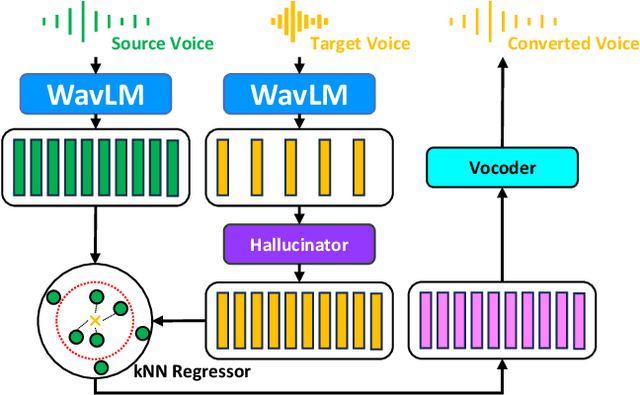

Voice conversion (VC) aims at altering a person's voice to make it sound similar to the voice of another person while preserving linguistic content. Existing methods suffer from a dilemma between content intelligibility and speaker similarity; i.e., methods with higher intelligibility usually have a lower speaker similarity, while methods with higher speaker similarity usually require plenty of target speaker voice data to achieve high intelligibility. In this work, we propose a novel method \textit{Phoneme Hallucinator} that achieves the best of both worlds. Phoneme Hallucinator is a one-shot VC model; it adopts a novel model to hallucinate diversified and high-fidelity target speaker phonemes based just on a short target speaker voice (e.g. 3 seconds). The hallucinated phonemes are then exploited to perform neighbor-based voice conversion. Our model is a text-free, any-to-any VC model that requires no text annotations and supports conversion to any unseen speaker. Objective and subjective evaluations show that \textit{Phoneme Hallucinator} outperforms existing VC methods for both intelligibility and speaker similarity.
Distribution-based Sketching of Single-Cell Samples
Jun 30, 2022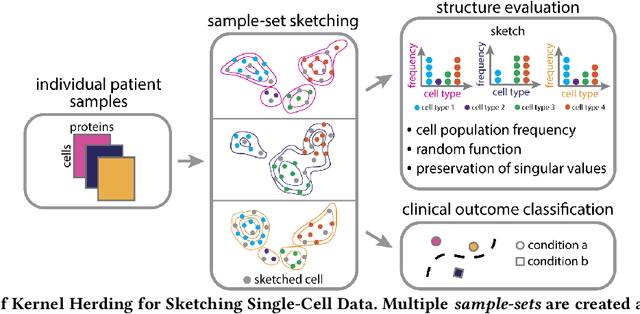
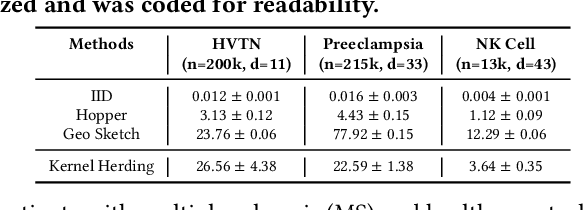
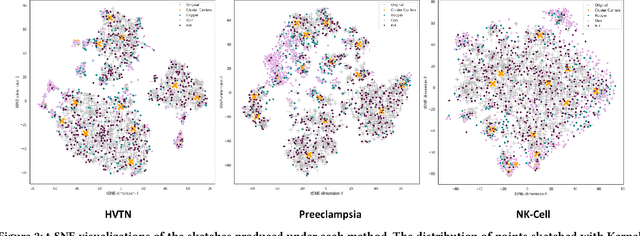
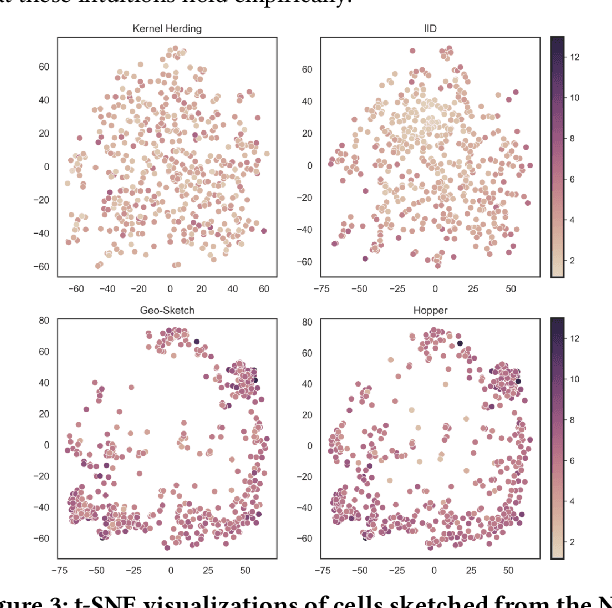
Modern high-throughput single-cell immune profiling technologies, such as flow and mass cytometry and single-cell RNA sequencing can readily measure the expression of a large number of protein or gene features across the millions of cells in a multi-patient cohort. While bioinformatics approaches can be used to link immune cell heterogeneity to external variables of interest, such as, clinical outcome or experimental label, they often struggle to accommodate such a large number of profiled cells. To ease this computational burden, a limited number of cells are typically \emph{sketched} or subsampled from each patient. However, existing sketching approaches fail to adequately subsample rare cells from rare cell-populations, or fail to preserve the true frequencies of particular immune cell-types. Here, we propose a novel sketching approach based on Kernel Herding that selects a limited subsample of all cells while preserving the underlying frequencies of immune cell-types. We tested our approach on three flow and mass cytometry datasets and on one single-cell RNA sequencing dataset and demonstrate that the sketched cells (1) more accurately represent the overall cellular landscape and (2) facilitate increased performance in downstream analysis tasks, such as classifying patients according to their clinical outcome. An implementation of sketching with Kernel Herding is publicly available at \url{https://github.com/vishalathreya/Set-Summarization}.
Any Variational Autoencoder Can Do Arbitrary Conditioning
Jan 28, 2022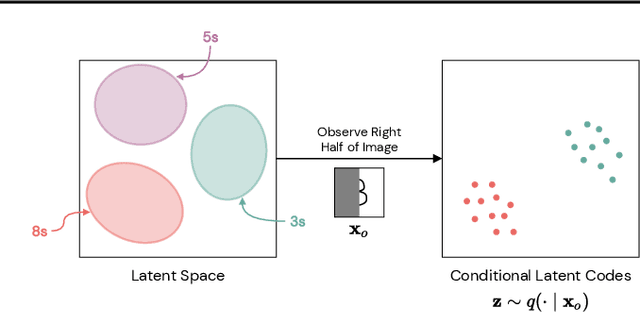

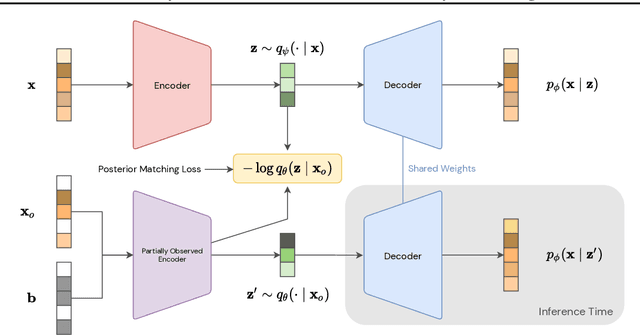

Arbitrary conditioning is an important problem in unsupervised learning, where we seek to model the conditional densities $p(\mathbf{x}_u \mid \mathbf{x}_o)$ that underly some data, for all possible non-intersecting subsets $o, u \subset \{1, \dots , d\}$. However, the vast majority of density estimation only focuses on modeling the joint distribution $p(\mathbf{x})$, in which important conditional dependencies between features are opaque. We propose a simple and general framework, coined Posterior Matching, that enables any Variational Autoencoder (VAE) to perform arbitrary conditioning, without modification to the VAE itself. Posterior Matching applies to the numerous existing VAE-based approaches to joint density estimation, thereby circumventing the specialized models required by previous approaches to arbitrary conditioning. We find that Posterior Matching achieves performance that is comparable or superior to current state-of-the-art methods for a variety of tasks.
Adversarial Scrubbing of Demographic Information for Text Classification
Sep 17, 2021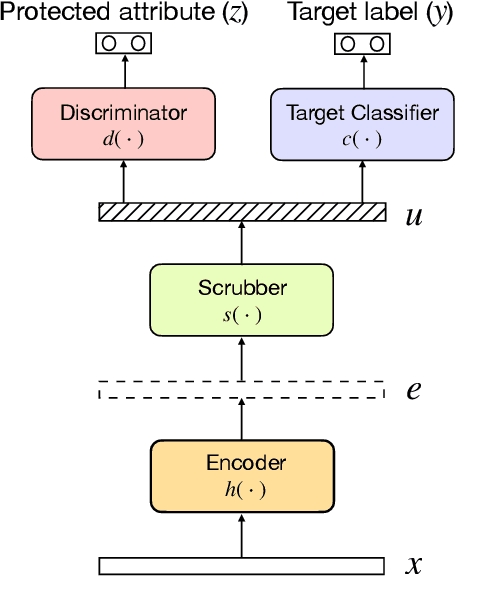
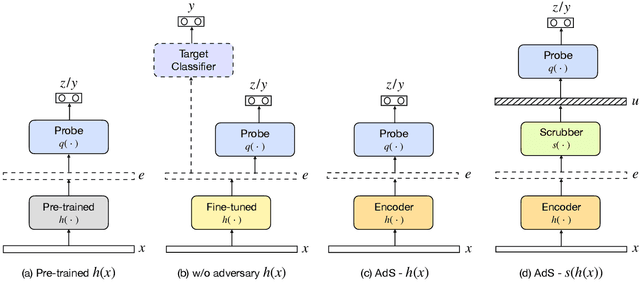
Contextual representations learned by language models can often encode undesirable attributes, like demographic associations of the users, while being trained for an unrelated target task. We aim to scrub such undesirable attributes and learn fair representations while maintaining performance on the target task. In this paper, we present an adversarial learning framework "Adversarial Scrubber" (ADS), to debias contextual representations. We perform theoretical analysis to show that our framework converges without leaking demographic information under certain conditions. We extend previous evaluation techniques by evaluating debiasing performance using Minimum Description Length (MDL) probing. Experimental evaluations on 8 datasets show that ADS generates representations with minimal information about demographic attributes while being maximally informative about the target task.
Towards Robust Active Feature Acquisition
Jul 09, 2021

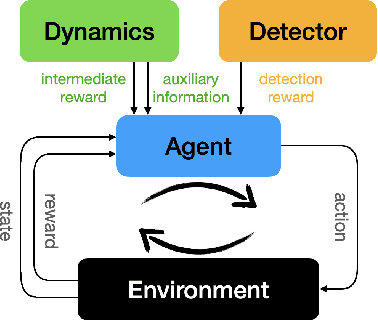
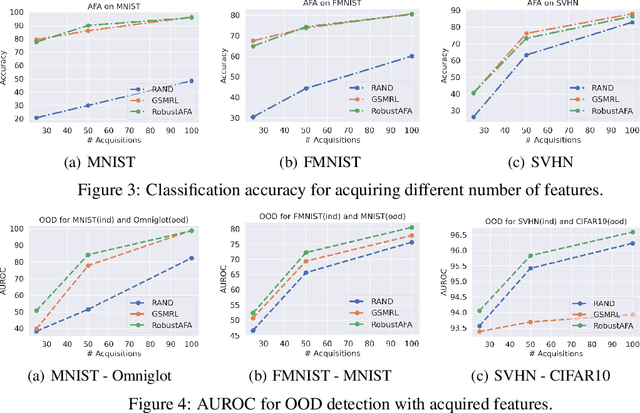
Truly intelligent systems are expected to make critical decisions with incomplete and uncertain data. Active feature acquisition (AFA), where features are sequentially acquired to improve the prediction, is a step towards this goal. However, current AFA models all deal with a small set of candidate features and have difficulty scaling to a large feature space. Moreover, they are ignorant about the valid domains where they can predict confidently, thus they can be vulnerable to out-of-distribution (OOD) inputs. In order to remedy these deficiencies and bring AFA models closer to practical use, we propose several techniques to advance the current AFA approaches. Our framework can easily handle a large number of features using a hierarchical acquisition policy and is more robust to OOD inputs with the help of an OOD detector for partially observed data. Extensive experiments demonstrate the efficacy of our framework over strong baselines.
NRTSI: Non-Recurrent Time Series Imputation for Irregularly-sampled Data
Feb 17, 2021
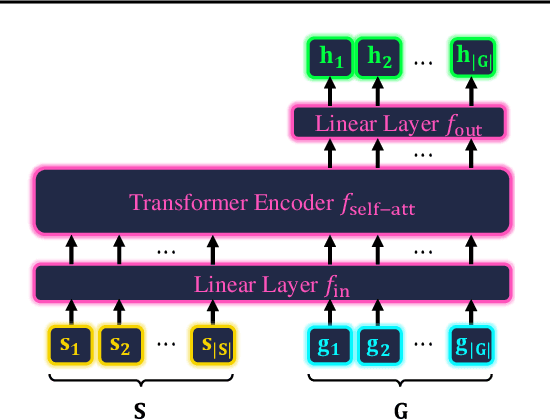

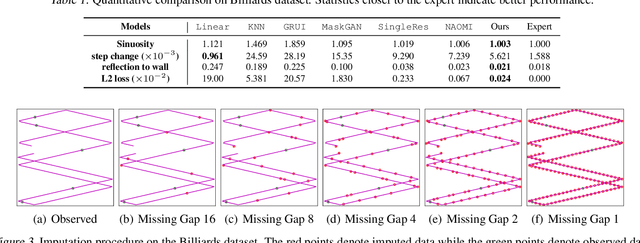
Time series imputation is a fundamental task for understanding time series with missing data. Existing imputation methods often rely on recurrent models such as RNNs and ordinary differential equations, both of which suffer from the error compounding problems of recurrent models. In this work, we view the imputation task from the perspective of permutation equivariant modeling of sets and propose a novel imputation model called NRTSI without any recurrent modules. Taking advantage of the permutation equivariant nature of NRTSI, we design a principled and efficient hierarchical imputation procedure. NRTSI can easily handle irregularly-sampled data, perform multiple-mode stochastic imputation, and handle the scenario where dimensions are partially observed. We show that NRTSI achieves state-of-the-art performance across a wide range of commonly used time series imputation benchmarks.
Partially Observed Exchangeable Modeling
Feb 11, 2021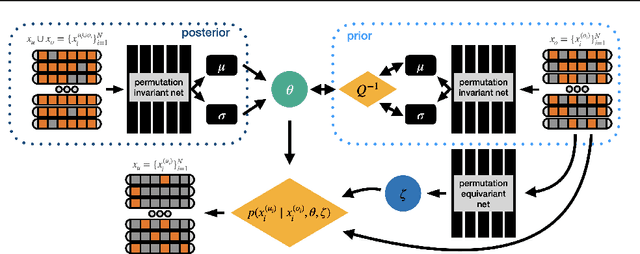
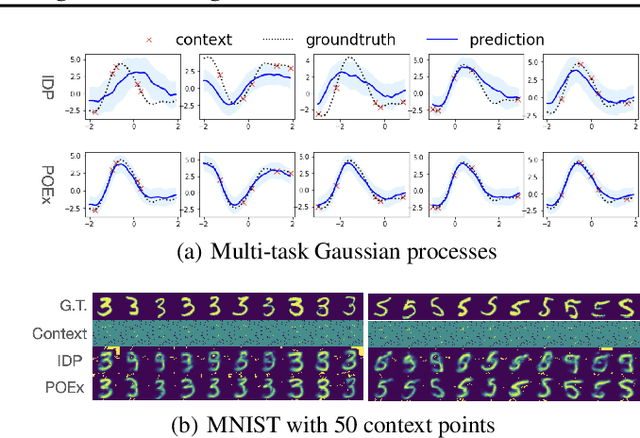


Modeling dependencies among features is fundamental for many machine learning tasks. Although there are often multiple related instances that may be leveraged to inform conditional dependencies, typical approaches only model conditional dependencies over individual instances. In this work, we propose a novel framework, partially observed exchangeable modeling (POEx) that takes in a set of related partially observed instances and infers the conditional distribution for the unobserved dimensions over multiple elements. Our approach jointly models the intra-instance (among features in a point) and inter-instance (among multiple points in a set) dependencies in data. POEx is a general framework that encompasses many existing tasks such as point cloud expansion and few-shot generation, as well as new tasks like few-shot imputation. Despite its generality, extensive empirical evaluations show that our model achieves state-of-the-art performance across a range of applications.
Arbitrary Conditional Distributions with Energy
Feb 08, 2021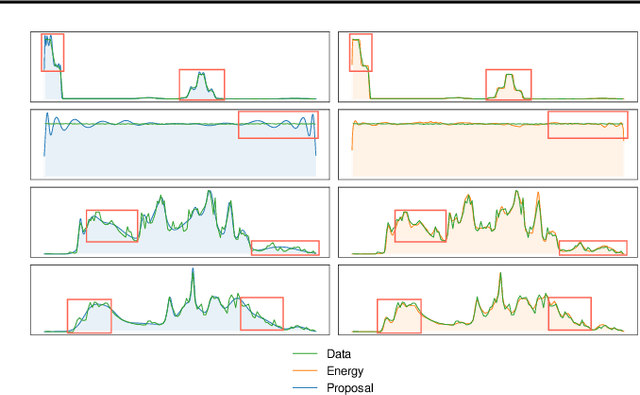


Modeling distributions of covariates, or density estimation, is a core challenge in unsupervised learning. However, the majority of work only considers the joint distribution, which has limited relevance to practical situations. A more general and useful problem is arbitrary conditional density estimation, which aims to model any possible conditional distribution over a set of covariates, reflecting the more realistic setting of inference based on prior knowledge. We propose a novel method, Arbitrary Conditioning with Energy (ACE), that can simultaneously estimate the distribution $p(\mathbf{x}_u \mid \mathbf{x}_o)$ for all possible subsets of features $\mathbf{x}_u$ and $\mathbf{x}_o$. ACE uses an energy function to specify densities, bypassing the architectural restrictions imposed by alternative methods and the biases imposed by tractable parametric distributions. We also simplify the learning problem by only learning one-dimensional conditionals, from which more complex distributions can be recovered during inference. Empirically, we show that ACE achieves state-of-the-art for arbitrary conditional and marginal likelihood estimation and for tabular data imputation.
Handling Non-ignorably Missing Features in Electronic Health Records Data Using Importance-Weighted Autoencoders
Feb 05, 2021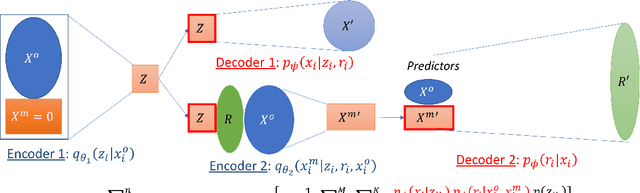
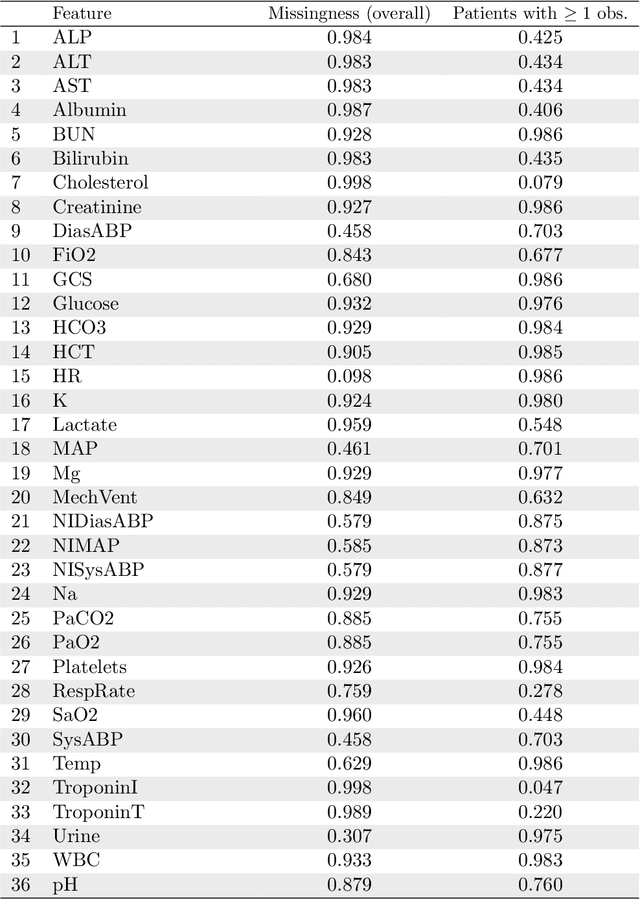
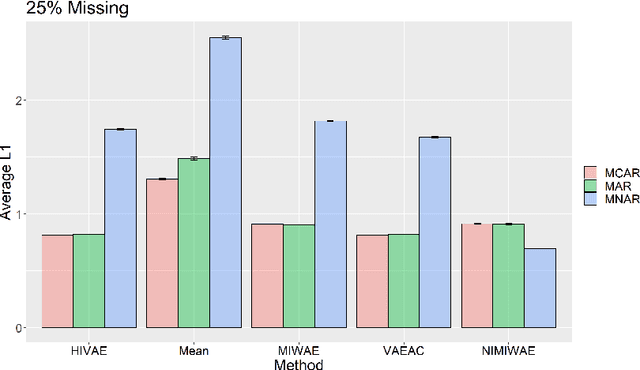
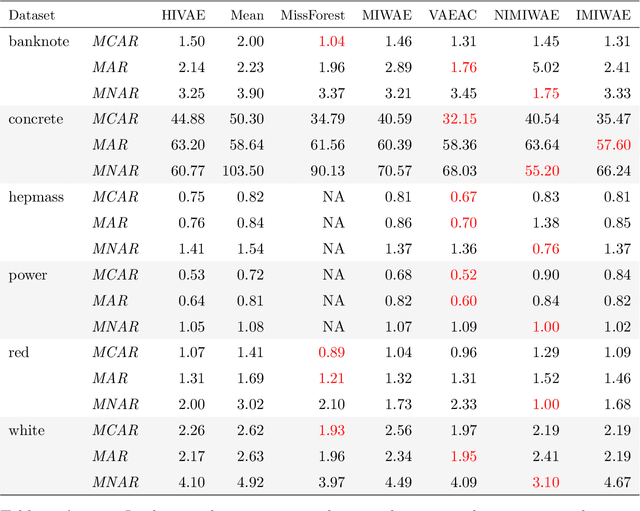
Electronic Health Records (EHRs) are commonly used to investigate relationships between patient health information and outcomes. Deep learning methods are emerging as powerful tools to learn such relationships, given the characteristic high dimension and large sample size of EHR datasets. The Physionet 2012 Challenge involves an EHR dataset pertaining to 12,000 ICU patients, where researchers investigated the relationships between clinical measurements, and in-hospital mortality. However, the prevalence and complexity of missing data in the Physionet data present significant challenges for the application of deep learning methods, such as Variational Autoencoders (VAEs). Although a rich literature exists regarding the treatment of missing data in traditional statistical models, it is unclear how this extends to deep learning architectures. To address these issues, we propose a novel extension of VAEs called Importance-Weighted Autoencoders (IWAEs) to flexibly handle Missing Not At Random (MNAR) patterns in the Physionet data. Our proposed method models the missingness mechanism using an embedded neural network, eliminating the need to specify the exact form of the missingness mechanism a priori. We show that the use of our method leads to more realistic imputed values relative to the state-of-the-art, as well as significant differences in fitted downstream models for mortality.