 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Trajectory Inference in Wasserstein Space Using Consecutive Averaging
May 30, 2024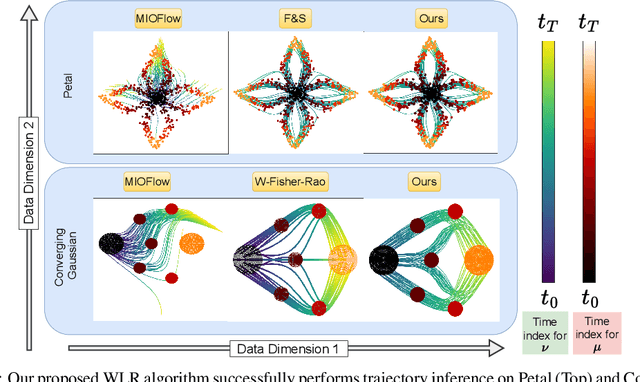
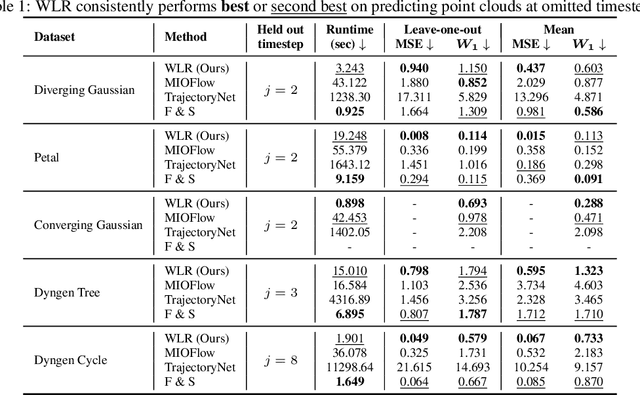
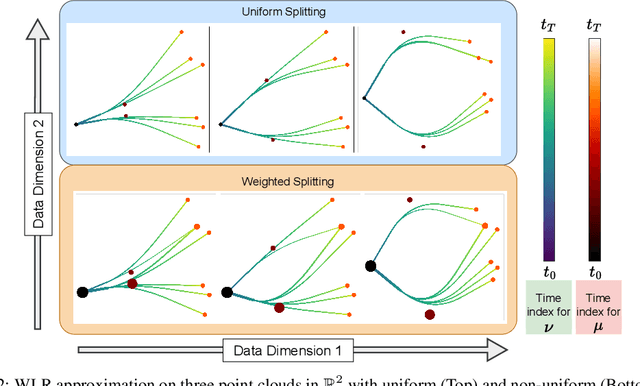

Capturing data from dynamic processes through cross-sectional measurements is seen in many fields such as computational biology. Trajectory inference deals with the challenge of reconstructing continuous processes from such observations. In this work, we propose methods for B-spline approximation and interpolation of point clouds through consecutive averaging that is instrinsic to the Wasserstein space. Combining subdivision schemes with optimal transport-based geodesic, our methods carry out trajectory inference at a chosen level of precision and smoothness, and can automatically handle scenarios where particles undergo division over time. We rigorously evaluate our method by providing convergence guarantees and testing it on simulated cell data characterized by bifurcations and merges, comparing its performance against state-of-the-art trajectory inference and interpolation methods. The results not only underscore the effectiveness of our method in inferring trajectories, but also highlight the benefit of performing interpolation and approximation that respect the inherent geometric properties of the data.
Surprisal Driven $k$-NN for Robust and Interpretable Nonparametric Learning
Nov 17, 2023Nonparametric learning is a fundamental concept in machine learning that aims to capture complex patterns and relationships in data without making strong assumptions about the underlying data distribution. Owing to simplicity and familiarity, one of the most well-known algorithms under this paradigm is the $k$-nearest neighbors ($k$-NN) algorithm. Driven by the usage of machine learning in safety-critical applications, in this work, we shed new light on the traditional nearest neighbors algorithm from the perspective of information theory and propose a robust and interpretable framework for tasks such as classification, regression, and anomaly detection using a single model. Instead of using a traditional distance measure which needs to be scaled and contextualized, we use a novel formulation of \textit{surprisal} (amount of information required to explain the difference between the observed and expected result). Finally, we demonstrate this architecture's capability to perform at-par or above the state-of-the-art on classification, regression, and anomaly detection tasks using a single model with enhanced interpretability by providing novel concepts for characterizing data and predictions.
Phoneme Hallucinator: One-shot Voice Conversion via Set Expansion
Aug 11, 2023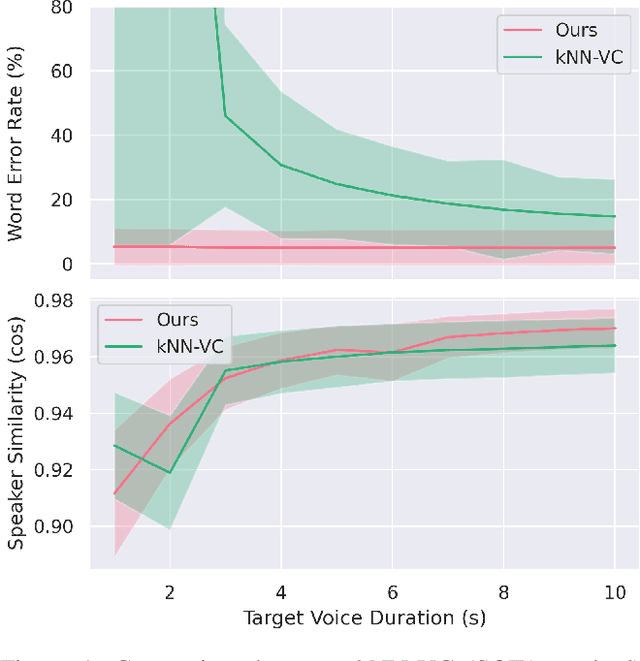
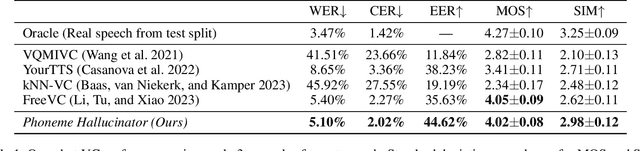
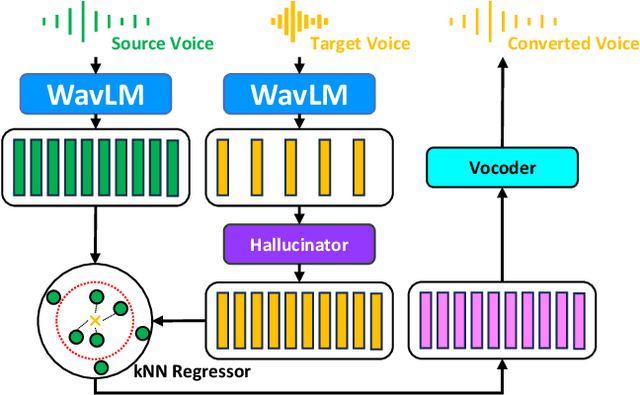

Voice conversion (VC) aims at altering a person's voice to make it sound similar to the voice of another person while preserving linguistic content. Existing methods suffer from a dilemma between content intelligibility and speaker similarity; i.e., methods with higher intelligibility usually have a lower speaker similarity, while methods with higher speaker similarity usually require plenty of target speaker voice data to achieve high intelligibility. In this work, we propose a novel method \textit{Phoneme Hallucinator} that achieves the best of both worlds. Phoneme Hallucinator is a one-shot VC model; it adopts a novel model to hallucinate diversified and high-fidelity target speaker phonemes based just on a short target speaker voice (e.g. 3 seconds). The hallucinated phonemes are then exploited to perform neighbor-based voice conversion. Our model is a text-free, any-to-any VC model that requires no text annotations and supports conversion to any unseen speaker. Objective and subjective evaluations show that \textit{Phoneme Hallucinator} outperforms existing VC methods for both intelligibility and speaker similarity.