 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of the Mechanics of Information: Generalization Through Measurement of Uncertainty (Learning is Measuring)
Oct 26, 2025Traditional machine learning relies on explicit models and domain assumptions, limiting flexibility and interpretability. We introduce a model-free framework using surprisal (information theoretic uncertainty) to directly analyze and perform inferences from raw data, eliminating distribution modeling, reducing bias, and enabling efficient updates including direct edits and deletion of training data. By quantifying relevance through uncertainty, the approach enables generalizable inference across tasks including generative inference, causal discovery, anomaly detection, and time series forecasting. It emphasizes traceability, interpretability, and data-driven decision making, offering a unified, human-understandable framework for machine learning, and achieves at or near state-of-the-art performance across most common machine learning tasks. The mathematical foundations create a ``physics'' of information, which enable these techniques to apply effectively to a wide variety of complex data types, including missing data. Empirical results indicate that this may be a viable alternative path to neural networks with regard to scalable machine learning and artificial intelligence that can maintain human understandability of the underlying mechanics.
Surprisal Driven $k$-NN for Robust and Interpretable Nonparametric Learning
Nov 17, 2023Nonparametric learning is a fundamental concept in machine learning that aims to capture complex patterns and relationships in data without making strong assumptions about the underlying data distribution. Owing to simplicity and familiarity, one of the most well-known algorithms under this paradigm is the $k$-nearest neighbors ($k$-NN) algorithm. Driven by the usage of machine learning in safety-critical applications, in this work, we shed new light on the traditional nearest neighbors algorithm from the perspective of information theory and propose a robust and interpretable framework for tasks such as classification, regression, and anomaly detection using a single model. Instead of using a traditional distance measure which needs to be scaled and contextualized, we use a novel formulation of \textit{surprisal} (amount of information required to explain the difference between the observed and expected result). Finally, we demonstrate this architecture's capability to perform at-par or above the state-of-the-art on classification, regression, and anomaly detection tasks using a single model with enhanced interpretability by providing novel concepts for characterizing data and predictions.
Linguistic Characterization of Divisive Topics Online: Case Studies on Contentiousness in Abortion, Climate Change, and Gun Control
Aug 30, 2021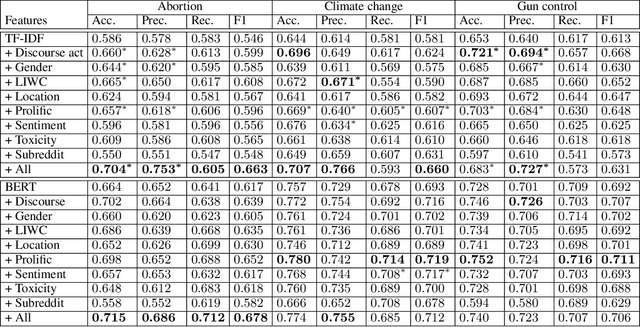
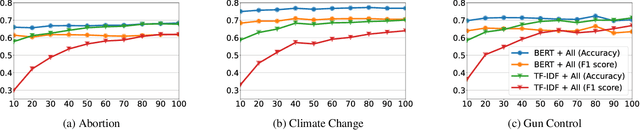
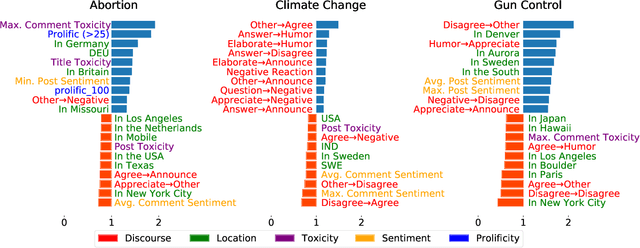
As public discourse continues to move and grow online, conversations about divisive topics on social media platforms have also increased. These divisive topics prompt both contentious and non-contentious conversations. Although what distinguishes these conversations, often framed as what makes these conversations contentious, is known in broad strokes, much less is known about the linguistic signature of these conversations. Prior work has shown that contentious content and structure can be a predictor for this task, however, most of them have been focused on conversation in general, very specific events, or complex structural analysis. Additionally, many models used in prior work have lacked interpret-ability, a key factor in online moderation. Our work fills these gaps by focusing on conversations from highly divisive topics (abortion, climate change, and gun control), operationalizing a set of novel linguistic and conversational characteristics and user factors, and incorporating them to build interpretable models. We demonstrate that such characteristics can largely improve the performance of prediction on this task, and also enable nuanced interpretability. Our case studies on these three contentious topics suggest that certain generic linguistic characteristics are highly correlated with contentiousness in conversations while others demonstrate significant contextual influences on specific divisive topics.