 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords and Action: Modeling Linguistic Leadership in #BlackLivesMatter Communities
Dec 03, 2024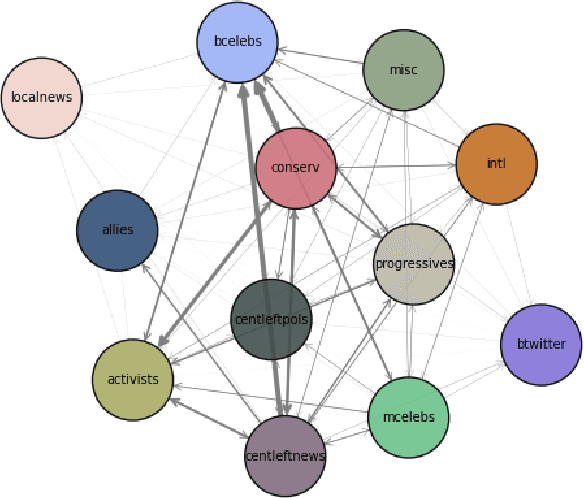



In this project, we describe a method of modeling semantic leadership across a set of communities associated with the #BlackLivesMatter movement, which has been informed by qualitative research on the structure of social media and Black Twitter in particular. We describe our bespoke approaches to time-binning, community clustering, and connecting communities over time, as well as our adaptation of state-of-the-art approaches to semantic change detection and semantic leadership induction. We find substantial evidence of the leadership role of BLM activists and progressives, as well as Black celebrities. We also find evidence of the sustained engagement of the conservative community with this discourse, suggesting an alternative explanation for how we arrived at the present moment, in which "anti-woke" and "anti-CRT" bills are being enacted nationwide.
Grounding Characters and Places in Narrative Texts
May 27, 2023

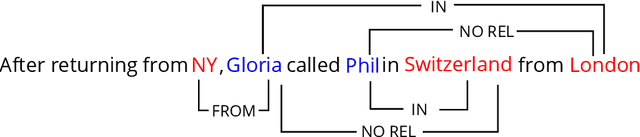

Tracking characters and locations throughout a story can help improve the understanding of its plot structure. Prior research has analyzed characters and locations from text independently without grounding characters to their locations in narrative time. Here, we address this gap by proposing a new spatial relationship categorization task. The objective of the task is to assign a spatial relationship category for every character and location co-mention within a window of text, taking into consideration linguistic context, narrative tense, and temporal scope. To this end, we annotate spatial relationships in approximately 2500 book excerpts and train a model using contextual embeddings as features to predict these relationships. When applied to a set of books, this model allows us to test several hypotheses on mobility and domestic space, revealing that protagonists are more mobile than non-central characters and that women as characters tend to occupy more interior space than men. Overall, our work is the first step towards joint modeling and analysis of characters and places in narrative text.
Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4
Apr 28, 2023



In this work, we carry out a data archaeology to infer books that are known to ChatGPT and GPT-4 using a name cloze membership inference query. We find that OpenAI models have memorized a wide collection of copyrighted materials, and that the degree of memorization is tied to the frequency with which passages of those books appear on the web. The ability of these models to memorize an unknown set of books complicates assessments of measurement validity for cultural analytics by contaminating test data; we show that models perform much better on memorized books than on non-memorized books for downstream tasks. We argue that this supports a case for open models whose training data is known.
Predicting Long-Term Citations from Short-Term Linguistic Influence
Oct 24, 2022



A standard measure of the influence of a research paper is the number of times it is cited. However, papers may be cited for many reasons, and citation count offers limited information about the extent to which a paper affected the content of subsequent publications. We therefore propose a novel method to quantify linguistic influence in timestamped document collections. There are two main steps: first, identify lexical and semantic changes using contextual embeddings and word frequencies; second, aggregate information about these changes into per-document influence scores by estimating a high-dimensional Hawkes process with a low-rank parameter matrix. We show that this measure of linguistic influence is predictive of $\textit{future}$ citations: the estimate of linguistic influence from the two years after a paper's publication is correlated with and predictive of its citation count in the following three years. This is demonstrated using an online evaluation with incremental temporal training/test splits, in comparison with a strong baseline that includes predictors for initial citation counts, topics, and lexical features.
Linguistic Characterization of Divisive Topics Online: Case Studies on Contentiousness in Abortion, Climate Change, and Gun Control
Aug 30, 2021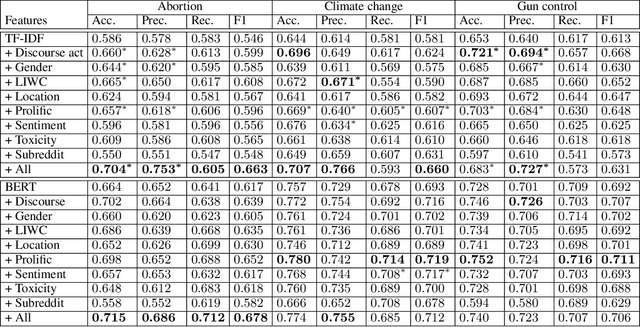
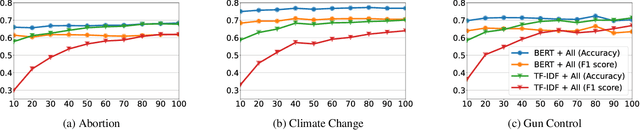
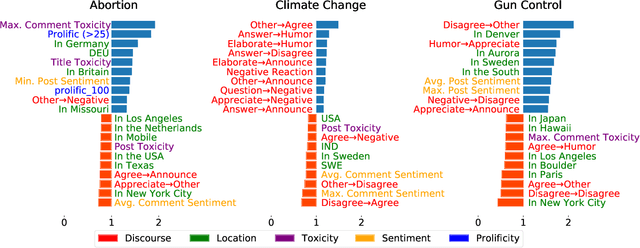
As public discourse continues to move and grow online, conversations about divisive topics on social media platforms have also increased. These divisive topics prompt both contentious and non-contentious conversations. Although what distinguishes these conversations, often framed as what makes these conversations contentious, is known in broad strokes, much less is known about the linguistic signature of these conversations. Prior work has shown that contentious content and structure can be a predictor for this task, however, most of them have been focused on conversation in general, very specific events, or complex structural analysis. Additionally, many models used in prior work have lacked interpret-ability, a key factor in online moderation. Our work fills these gaps by focusing on conversations from highly divisive topics (abortion, climate change, and gun control), operationalizing a set of novel linguistic and conversational characteristics and user factors, and incorporating them to build interpretable models. We demonstrate that such characteristics can largely improve the performance of prediction on this task, and also enable nuanced interpretability. Our case studies on these three contentious topics suggest that certain generic linguistic characteristics are highly correlated with contentiousness in conversations while others demonstrate significant contextual influences on specific divisive topics.
Abolitionist Networks: Modeling Language Change in Nineteenth-Century Activist Newspapers
Mar 12, 2021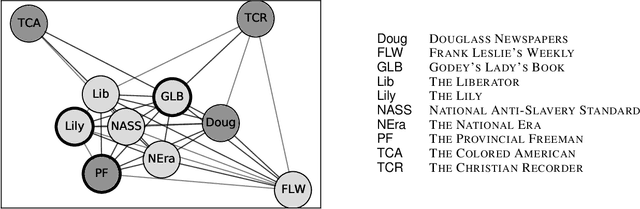
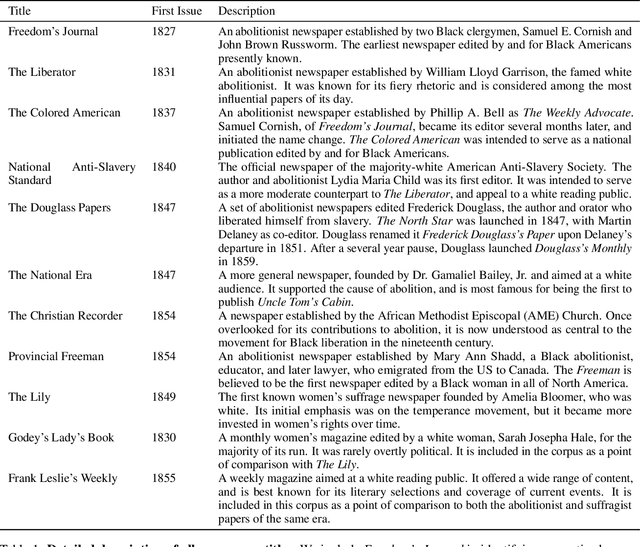


The abolitionist movement of the nineteenth-century United States remains among the most significant social and political movements in US history. Abolitionist newspapers played a crucial role in spreading information and shaping public opinion around a range of issues relating to the abolition of slavery. These newspapers also serve as a primary source of information about the movement for scholars today, resulting in powerful new accounts of the movement and its leaders. This paper supplements recent qualitative work on the role of women in abolition's vanguard, as well as the role of the Black press, with a quantitative text modeling approach. Using diachronic word embeddings, we identify which newspapers tended to lead lexical semantic innovations -- the introduction of new usages of specific words -- and which newspapers tended to follow. We then aggregate the evidence across hundreds of changes into a weighted network with the newspapers as nodes; directed edge weights represent the frequency with which each newspaper led the other in the adoption of a lexical semantic change. Analysis of this network reveals pathways of lexical semantic influence, distinguishing leaders from followers, as well as others who stood apart from the semantic changes that swept through this period. More specifically, we find that two newspapers edited by women -- THE PROVINCIAL FREEMAN and THE LILY -- led a large number of semantic changes in our corpus, lending additional credence to the argument that a multiracial coalition of women led the abolitionist movement in terms of both thought and action. It also contributes additional complexity to the scholarship that has sought to tease apart the relation of the abolitionist movement to the women's suffrage movement, and the vexed racial politics that characterized their relation.
* 23 pages, 6 figures, 2 tables
Racism is a Virus: Anti-Asian Hate and Counterhate in Social Media during the COVID-19 Crisis
May 25, 2020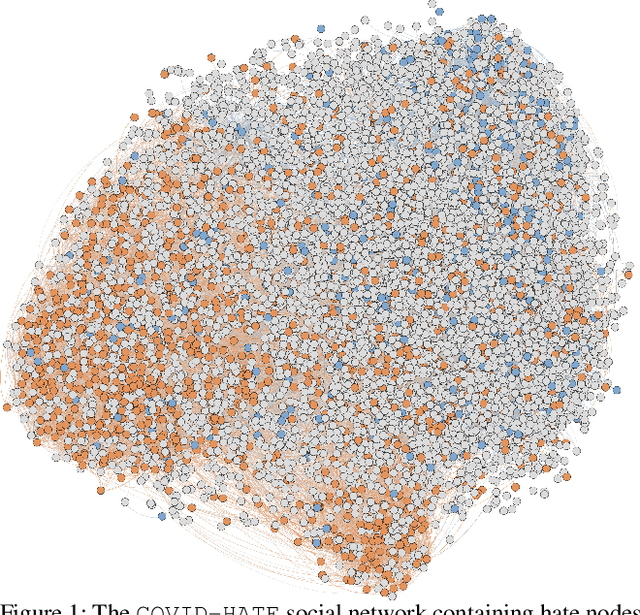
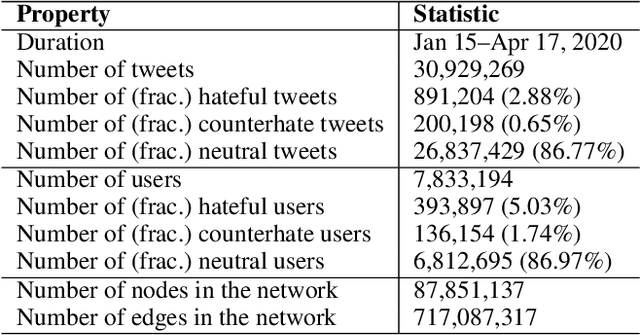


The spread of COVID-19 has sparked racism, hate, and xenophobia in social media targeted at Chinese and broader Asian communities. However, little is known about how racial hate spreads during a pandemic and the role of counterhate speech in mitigating the spread. Here we study the evolution and spread of anti-Asian hate speech through the lens of Twitter. We create COVID-HATE, the largest dataset of anti-Asian hate and counterhate spanning three months, containing over 30 million tweets, and a social network with over 87 million nodes. By creating a novel hand-labeled dataset of 2,400 tweets, we train a text classifier to identify hate and counterhate tweets that achieves an average AUROC of 0.852. We identify 891,204 hate and 200,198 counterhate tweets in COVID-HATE. Using this data to conduct longitudinal analysis, we find that while hateful users are less engaged in the COVID-19 discussions prior to their first anti-Asian tweet, they become more vocal and engaged afterwards compared to counterhate users. We find that bots comprise 10.4% of hateful users and are more vocal and hateful compared to non-bot users. Comparing bot accounts, we show that hateful bots are more successful in attracting followers compared to counterhate bots. Analysis of the social network reveals that hateful and counterhate users interact and engage extensively with one another, instead of living in isolated polarized communities. Furthermore, we find that hate is contagious and nodes are highly likely to become hateful after being exposed to hateful content. Importantly, our analysis reveals that counterhate messages can discourage users from turning hateful in the first place. Overall, this work presents a comprehensive overview of anti-Asian hate and counterhate content during a pandemic. The COVID-HATE dataset is available at http://claws.cc.gatech.edu/covid.
Follow the Leader: Documents on the Leading Edge of Semantic Change Get More Citations
Sep 09, 2019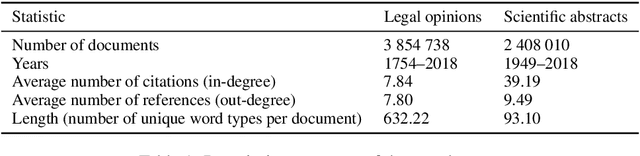

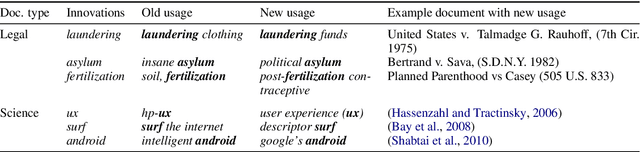
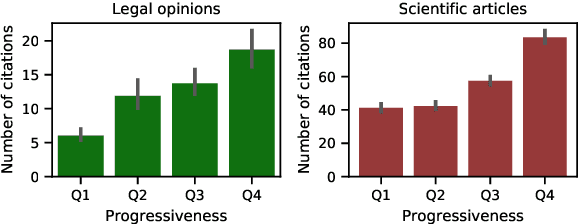
Diachronic word embeddings offer remarkable insights into the evolution of language and provide a tool for quantifying socio-cultural change. However, while this method identifies words that have semantically shifted, it studies them in isolation; it does not facilitate the discovery of documents that lead or lag with respect to specific semantic innovations. In this paper, we propose a method to quantify the degree of semantic progressiveness in each usage. These usages can be aggregated to obtain scores for each document. We analyze two large collections of documents, representing legal opinions and scientific articles. Documents that are predicted to be semantically progressive receive a larger number of citations, indicating that they are especially influential. Our work thus provides a new technique for identifying lexical semantic leaders and demonstrates a new link between early adoption and influence in a citation network.
Characterizing Activity on the Deep and Dark Web
Mar 01, 2019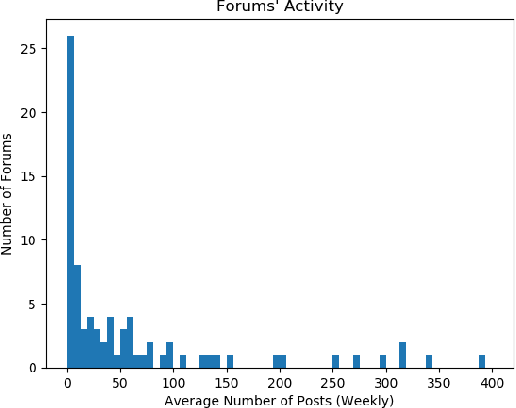


The deep and darkweb (d2web) refers to limited access web sites that require registration, authentication, or more complex encryption protocols to access them. These web sites serve as hubs for a variety of illicit activities: to trade drugs, stolen user credentials, hacking tools, and to coordinate attacks and manipulation campaigns. Despite its importance to cyber crime, the d2web has not been systematically investigated. In this paper, we study a large corpus of messages posted to 80 d2web forums over a period of more than a year. We identify topics of discussion using LDA and use a non-parametric HMM to model the evolution of topics across forums. Then, we examine the dynamic patterns of discussion and identify forums with similar patterns. We show that our approach surfaces hidden similarities across different forums and can help identify anomalous events in this rich, heterogeneous data.
Discriminative Modeling of Social Influence for Prediction and Explanation in Event Cascades
Feb 16, 2018
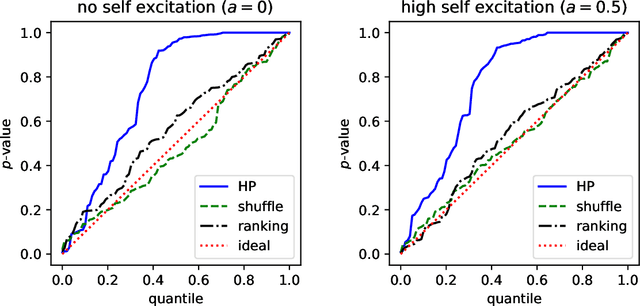


The global dynamics of event cascades are often governed by the local dynamics of peer influence. However, detecting social influence from observational data is challenging, due to confounds like homophily and practical issues like missing data. In this work, we propose a novel discriminative method to detect influence from observational data. The core of the approach is to train a ranking algorithm to predict the source of the next event in a cascade, and compare its out-of-sample accuracy against a competitive baseline which lacks access to features corresponding to social influence. Using synthetically generated data, we provide empirical evidence that this method correctly identifies influence in the presence of confounds, and is robust to both missing data and misspecification --- unlike popular alternatives. We also apply the method to two real-world datasets: (1) cascades of co-sponsorship of legislation in the U.S. House of Representatives, on a social network of shared campaign donors; (2) rumors about the Higgs boson discovery, on a follower network of $10^5$ Twitter accounts. Our model identifies the role of peer influence in these scenarios, and uses it to make more accurate predictions about the future trajectory of cascades.