 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Modeling of Social Influence for Prediction and Explanation in Event Cascades
Paper and Code

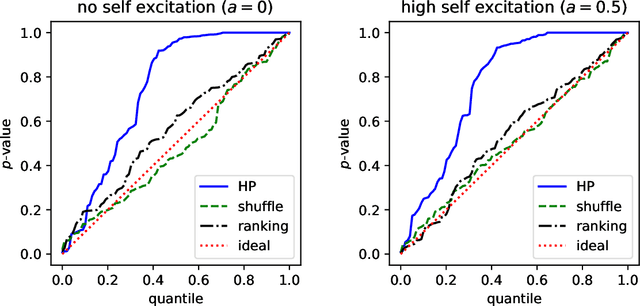


The global dynamics of event cascades are often governed by the local dynamics of peer influence. However, detecting social influence from observational data is challenging, due to confounds like homophily and practical issues like missing data. In this work, we propose a novel discriminative method to detect influence from observational data. The core of the approach is to train a ranking algorithm to predict the source of the next event in a cascade, and compare its out-of-sample accuracy against a competitive baseline which lacks access to features corresponding to social influence. Using synthetically generated data, we provide empirical evidence that this method correctly identifies influence in the presence of confounds, and is robust to both missing data and misspecification --- unlike popular alternatives. We also apply the method to two real-world datasets: (1) cascades of co-sponsorship of legislation in the U.S. House of Representatives, on a social network of shared campaign donors; (2) rumors about the Higgs boson discovery, on a follower network of $10^5$ Twitter accounts. Our model identifies the role of peer influence in these scenarios, and uses it to make more accurate predictions about the future trajectory of cascades.