 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLM Evaluators Really Narcissists? Sanity Checking Self-Preference Evaluations
Jan 30, 2026Recent research has shown that large language models (LLM) favor own outputs when acting as judges, undermining the integrity of automated post-training and evaluation workflows. However, it is difficult to disentangle which evaluation biases are explained by narcissism versus general experimental confounds, distorting measurements of self-preference bias. We discover a core methodological confound which could reduce measurement error by 89.6%. Specifically, LLM evaluators may deliver self-preferring verdicts when the judge responds to queries which they completed incorrectly themselves; this would be true regardless of whether one of their responses is their own. To decouple self-preference signals from noisy outputs on hard problems, we introduce an Evaluator Quality Baseline, which compares the probability that a judge incorrectly votes for itself against the probability that it votes for an incorrect response from another model. Evaluating this simple baseline on 37,448 queries, only 51% of initial findings retain statistical significance. Finally, we turn towards characterizing the entropy of "easy" versus "hard" evaluation votes from LLM judges. Our corrective baseline enables future research on self-preference by eliminating noisy data from potential solutions. More widely, this work contributes to the growing body of work on cataloging and isolating judge-bias effects.
Mind the Gap! Pathways Towards Unifying AI Safety and Ethics Research
Dec 10, 2025



While much research in artificial intelligence (AI) has focused on scaling capabilities, the accelerating pace of development makes countervailing work on producing harmless, "aligned" systems increasingly urgent. Yet research on alignment has diverged along two largely parallel tracks: safety--centered on scaled intelligence, deceptive or scheming behaviors, and existential risk--and ethics--focused on present harms, the reproduction of social bias, and flaws in production pipelines. Although both communities warn of insufficient investment in alignment, they disagree on what alignment means or ought to mean. As a result, their efforts have evolved in relative isolation, shaped by distinct methodologies, institutional homes, and disciplinary genealogies. We present a large-scale, quantitative study showing the structural split between AI safety and AI ethics. Using a bibliometric and co-authorship network analysis of 6,442 papers from twelve major ML and NLP conferences (2020-2025), we find that over 80% of collaborations occur within either the safety or ethics communities, and cross-field connectivity is highly concentrated: roughly 5% of papers account for more than 85% of bridging links. Removing a small number of these brokers sharply increases segregation, indicating that cross-disciplinary exchange depends on a handful of actors rather than broad, distributed collaboration. These results show that the safety-ethics divide is not only conceptual but institutional, with implications for research agendas, policy, and venues. We argue that integrating technical safety work with normative ethics--via shared benchmarks, cross-institutional venues, and mixed-method methodologies--is essential for building AI systems that are both robust and just.
Breaking the Mirror: Activation-Based Mitigation of Self-Preference in LLM Evaluators
Sep 03, 2025Large language models (LLMs) increasingly serve as automated evaluators, yet they suffer from "self-preference bias": a tendency to favor their own outputs over those of other models. This bias undermines fairness and reliability in evaluation pipelines, particularly for tasks like preference tuning and model routing. We investigate whether lightweight steering vectors can mitigate this problem at inference time without retraining. We introduce a curated dataset that distinguishes self-preference bias into justified examples of self-preference and unjustified examples of self-preference, and we construct steering vectors using two methods: Contrastive Activation Addition (CAA) and an optimization-based approach. Our results show that steering vectors can reduce unjustified self-preference bias by up to 97\%, substantially outperforming prompting and direct preference optimization baselines. Yet steering vectors are unstable on legitimate self-preference and unbiased agreement, implying self-preference spans multiple or nonlinear directions. This underscores both their promise and limits as safeguards for LLM-as-judges and motivates more robust interventions.
Words and Action: Modeling Linguistic Leadership in #BlackLivesMatter Communities
Dec 03, 2024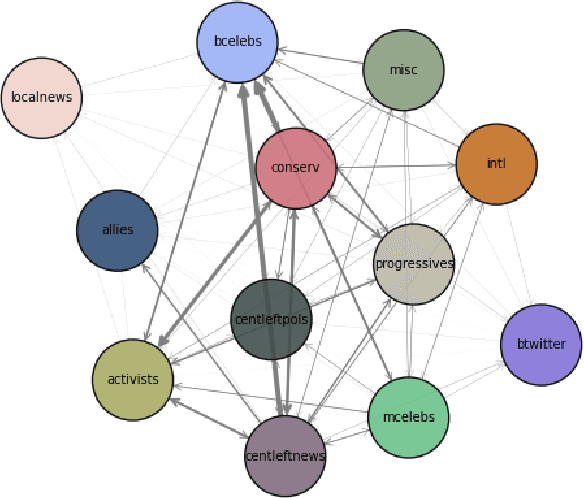



In this project, we describe a method of modeling semantic leadership across a set of communities associated with the #BlackLivesMatter movement, which has been informed by qualitative research on the structure of social media and Black Twitter in particular. We describe our bespoke approaches to time-binning, community clustering, and connecting communities over time, as well as our adaptation of state-of-the-art approaches to semantic change detection and semantic leadership induction. We find substantial evidence of the leadership role of BLM activists and progressives, as well as Black celebrities. We also find evidence of the sustained engagement of the conservative community with this discourse, suggesting an alternative explanation for how we arrived at the present moment, in which "anti-woke" and "anti-CRT" bills are being enacted nationwide.