 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Price Inflation on Algorithmic Collusion Through Reinforcement Learning Agents
Apr 05, 2025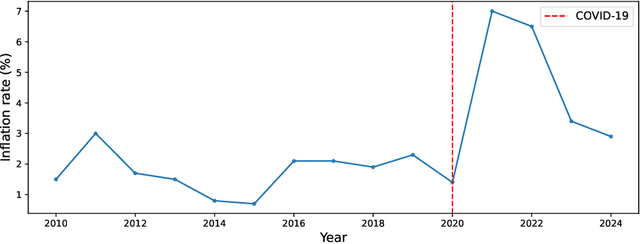

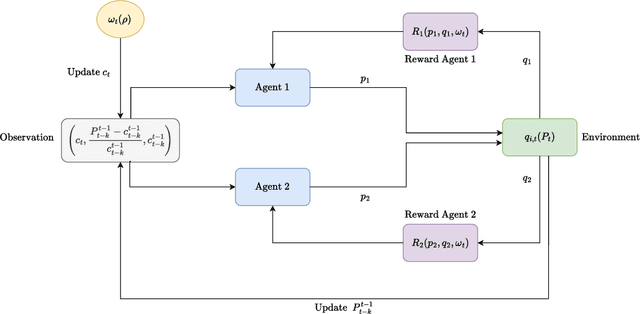

Algorithmic pricing is increasingly shaping market competition, raising concerns about its potential to compromise competitive dynamics. While prior work has shown that reinforcement learning (RL)-based pricing algorithms can lead to tacit collusion, less attention has been given to the role of macroeconomic factors in shaping these dynamics. This study examines the role of inflation in influencing algorithmic collusion within competitive markets. By incorporating inflation shocks into a RL-based pricing model, we analyze whether agents adapt their strategies to sustain supra-competitive profits. Our findings indicate that inflation reduces market competitiveness by fostering implicit coordination among agents, even without direct collusion. However, despite achieving sustained higher profitability, agents fail to develop robust punishment mechanisms to deter deviations from equilibrium strategies. The results suggest that inflation amplifies non-competitive dynamics in algorithmic pricing, emphasizing the need for regulatory oversight in markets where AI-driven pricing is prevalent.
Zero-Shot Decision Tree Construction via Large Language Models
Jan 27, 2025



This paper introduces a novel algorithm for constructing decision trees using large language models (LLMs) in a zero-shot manner based on Classification and Regression Trees (CART) principles. Traditional decision tree induction methods rely heavily on labeled data to recursively partition data using criteria such as information gain or the Gini index. In contrast, we propose a method that uses the pre-trained knowledge embedded in LLMs to build decision trees without requiring training data. Our approach leverages LLMs to perform operations essential for decision tree construction, including attribute discretization, probability calculation, and Gini index computation based on the probabilities. We show that these zero-shot decision trees can outperform baseline zero-shot methods and achieve competitive performance compared to supervised data-driven decision trees on tabular datasets. The decision trees constructed via this method provide transparent and interpretable models, addressing data scarcity while preserving interpretability. This work establishes a new baseline in low-data machine learning, offering a principled, knowledge-driven alternative to data-driven tree construction.
Fairness in LLM-Generated Surveys
Jan 25, 2025Large Language Models (LLMs) excel in text generation and understanding, especially in simulating socio-political and economic patterns, serving as an alternative to traditional surveys. However, their global applicability remains questionable due to unexplored biases across socio-demographic and geographic contexts. This study examines how LLMs perform across diverse populations by analyzing public surveys from Chile and the United States, focusing on predictive accuracy and fairness metrics. The results show performance disparities, with LLM consistently outperforming on U.S. datasets. This bias originates from the U.S.-centric training data, remaining evident after accounting for socio-demographic differences. In the U.S., political identity and race significantly influence prediction accuracy, while in Chile, gender, education, and religious affiliation play more pronounced roles. Our study presents a novel framework for measuring socio-demographic biases in LLMs, offering a path toward ensuring fairer and more equitable model performance across diverse socio-cultural contexts.
Measuring the Predictability of Recommender Systems using Structural Complexity Metrics
Apr 12, 2024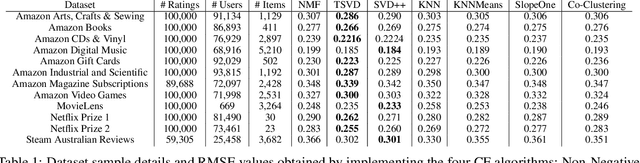

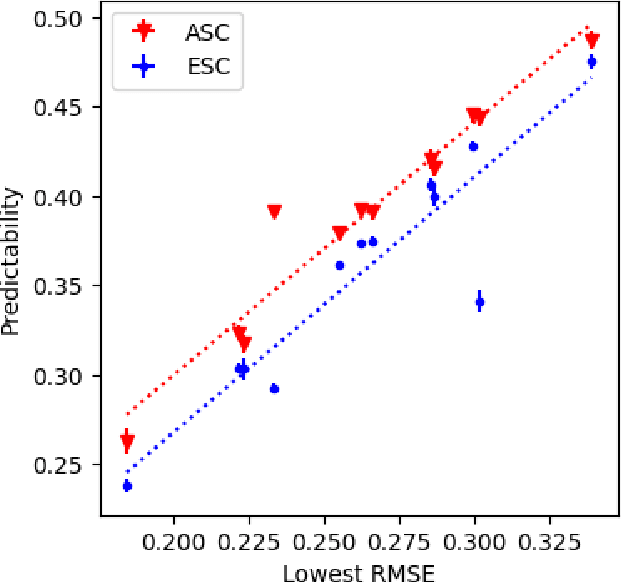
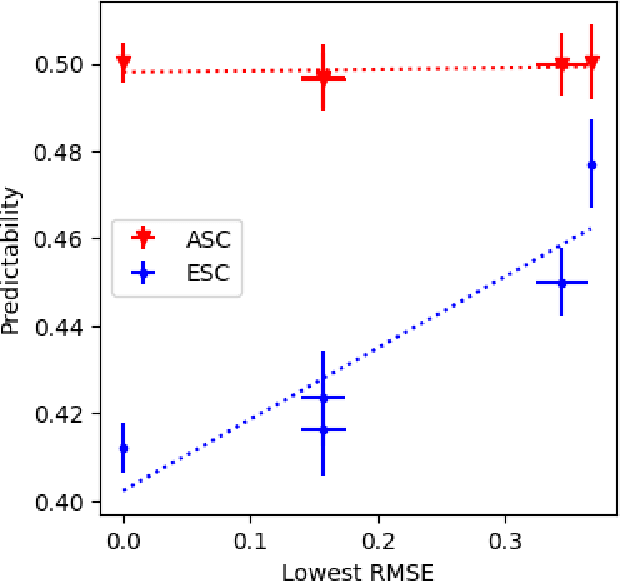
Recommender systems (RS) are central to the filtering and curation of online content. These algorithms predict user ratings for unseen items based on past preferences. Despite their importance, the innate predictability of RS has received limited attention. This study introduces data-driven metrics to measure the predictability of RS based on the structural complexity of the user-item rating matrix. A low predictability score indicates complex and unpredictable user-item interactions, while a high predictability score reveals less complex patterns with predictive potential. We propose two strategies that use singular value decomposition (SVD) and matrix factorization (MF) to measure structural complexity. By perturbing the data and evaluating the prediction of the perturbed version, we explore the structural consistency indicated by the SVD singular vectors. The assumption is that a random perturbation of highly structured data does not change its structure. Empirical results show a high correlation between our metrics and the accuracy of the best-performing prediction algorithms on real data sets.
QuickCent: a fast and frugal heuristic for harmonic centrality estimation on scale-free networks
Mar 02, 2023


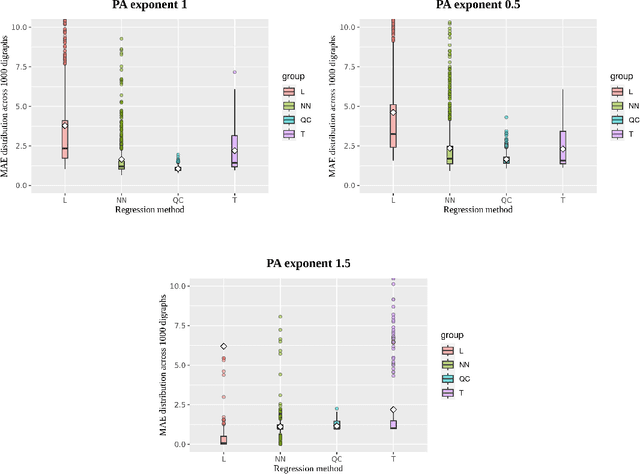
We present a simple and quick method to approximate network centrality indexes. Our approach, called QuickCent, is inspired by so-called fast and frugal heuristics, which are heuristics initially proposed to model some human decision and inference processes. The centrality index that we estimate is the harmonic centrality, which is a measure based on shortest-path distances, so infeasible to compute on large networks. We compare QuickCent with known machine learning algorithms on synthetic data generated with preferential attachment, and some empirical networks. Our experiments show that QuickCent is able to make estimates that are competitive in accuracy with the best alternative methods tested, either on synthetic scale-free networks or empirical networks. QuickCent has the feature of achieving low error variance estimates, even with a small training set. Moreover, QuickCent is comparable in efficiency -- accuracy and time cost -- to those produced by more complex methods. We discuss and provide some insight into how QuickCent exploits the fact that in some networks, such as those generated by preferential attachment, local density measures such as the in-degree, can be a proxy for the size of the network region to which a node has access, opening up the possibility of approximating centrality indices based on size such as the harmonic centrality. Our initial results show that simple heuristics and biologically inspired computational methods are a promising line of research in the context of network measure estimations.
Challenges in Forecasting Malicious Events from Incomplete Data
Apr 06, 2020



The ability to accurately predict cyber-attacks would enable organizations to mitigate their growing threat and avert the financial losses and disruptions they cause. But how predictable are cyber-attacks? Researchers have attempted to combine external data -- ranging from vulnerability disclosures to discussions on Twitter and the darkweb -- with machine learning algorithms to learn indicators of impending cyber-attacks. However, successful cyber-attacks represent a tiny fraction of all attempted attacks: the vast majority are stopped, or filtered by the security appliances deployed at the target. As we show in this paper, the process of filtering reduces the predictability of cyber-attacks. The small number of attacks that do penetrate the target's defenses follow a different generative process compared to the whole data which is much harder to learn for predictive models. This could be caused by the fact that the resulting time series also depends on the filtering process in addition to all the different factors that the original time series depended on. We empirically quantify the loss of predictability due to filtering using real-world data from two organizations. Our work identifies the limits to forecasting cyber-attacks from highly filtered data.
Learning Behavioral Representations from Wearable Sensors
Nov 16, 2019


The ubiquity of mobile devices and wearable sensors offers unprecedented opportunities for continuous collection of multimodal physiological data. Such data enables temporal characterization of an individual's behaviors, which can provide unique insights into her physical and psychological health. Understanding the relation between different behaviors/activities and personality traits such as stress or work performance can help build strategies to improve the work environment. Especially in workplaces like hospitals where many employees are overworked, having such policies improves the quality of patient care by prioritizing mental and physical health of their caregivers. One challenge in analyzing physiological data is extracting the underlying behavioral states from the temporal sensor signals and interpreting them. Here, we use a non-parametric Bayesian approach, to model multivariate sensor data from multiple people and discover dynamic behaviors they share. We apply this method to data collected from sensors worn by a population of workers in a large urban hospital, capturing their physiological signals, such as breathing and heart rate, and activity patterns. We show that the learned states capture behavioral differences within the population that can help cluster participants into meaningful groups and better predict their cognitive and affective states. This method offers a practical way to learn compact behavioral representations from dynamic multivariate sensor signals and provide insights into the data.
Discovering patterns of online popularity from time series
Apr 10, 2019
How is popularity gained online? Is being successful strictly related to rapidly becoming viral in an online platform or is it possible to acquire popularity in a steady and disciplined fashion? What are other temporal characteristics that can unveil the popularity of online content? To answer these questions, we leverage a multi-faceted temporal analysis of the evolution of popular online contents. Here, we present dipm-SC: a multi-dimensional shape-based time-series clustering algorithm with a heuristic to find the optimal number of clusters. First, we validate the accuracy of our algorithm on synthetic datasets generated from benchmark time series models. Second, we show that dipm-SC can uncover meaningful clusters of popularity behaviors in a real-world Twitter dataset. By clustering the multidimensional time-series of the popularity of contents coupled with other domain-specific dimensions, we uncover two main patterns of popularity: bursty and steady temporal behaviors. Moreover, we find that the way popularity is gained over time has no significant impact on the final cumulative popularity.
Characterizing Activity on the Deep and Dark Web
Mar 01, 2019


The deep and darkweb (d2web) refers to limited access web sites that require registration, authentication, or more complex encryption protocols to access them. These web sites serve as hubs for a variety of illicit activities: to trade drugs, stolen user credentials, hacking tools, and to coordinate attacks and manipulation campaigns. Despite its importance to cyber crime, the d2web has not been systematically investigated. In this paper, we study a large corpus of messages posted to 80 d2web forums over a period of more than a year. We identify topics of discussion using LDA and use a non-parametric HMM to model the evolution of topics across forums. Then, we examine the dynamic patterns of discussion and identify forums with similar patterns. We show that our approach surfaces hidden similarities across different forums and can help identify anomalous events in this rich, heterogeneous data.