 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Uncertainty in Deep Learning for Selective Classification
May 23, 2019
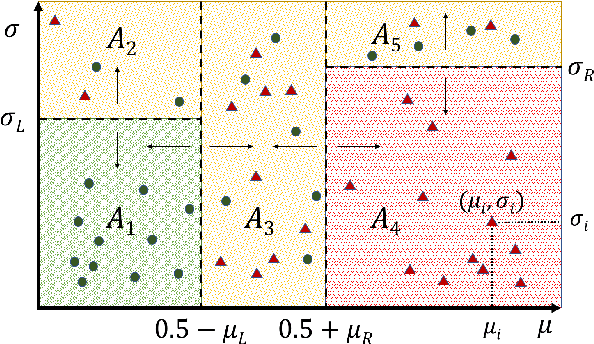
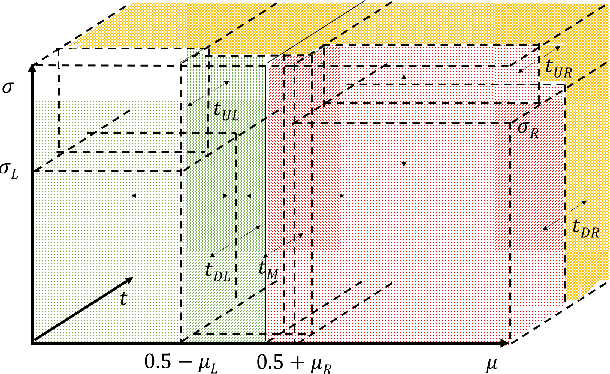
The wide and rapid adoption of deep learning by practitioners brought unintended consequences in many situations such as in the infamous case of Google Photos' racist image recognition algorithm; thus, necessitated the utilization of the quantified uncertainty for each prediction. There have been recent efforts towards quantifying uncertainty in conventional deep learning methods (e.g., dropout as Bayesian approximation); however, their optimal use in decision making is often overlooked and understudied. In this study, we propose a mixed-integer programming framework for classification with reject option (also known as selective classification), that investigates and combines model uncertainty and predictive mean to identify optimal classification and rejection regions. Our results indicate superior performance of our framework both in non-rejected accuracy and rejection quality on several publicly available datasets. Moreover, we extend our framework to cost-sensitive settings and show that our approach outperforms industry standard methods significantly for online fraud management in real-world settings.
Discovering patterns of online popularity from time series
Apr 10, 2019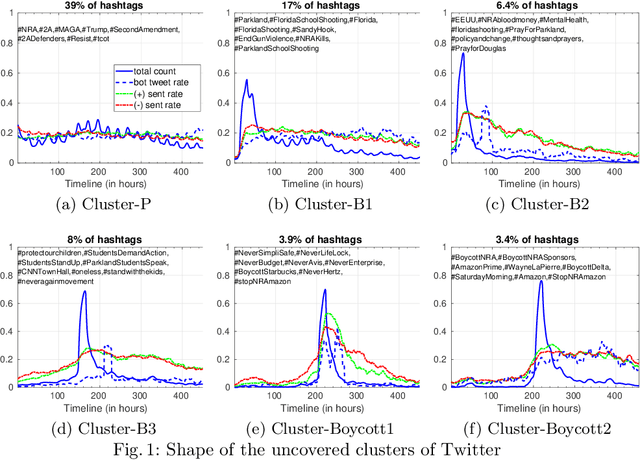
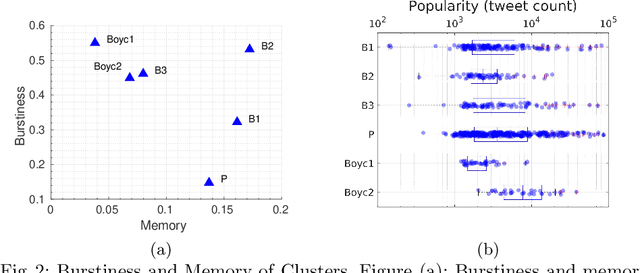
How is popularity gained online? Is being successful strictly related to rapidly becoming viral in an online platform or is it possible to acquire popularity in a steady and disciplined fashion? What are other temporal characteristics that can unveil the popularity of online content? To answer these questions, we leverage a multi-faceted temporal analysis of the evolution of popular online contents. Here, we present dipm-SC: a multi-dimensional shape-based time-series clustering algorithm with a heuristic to find the optimal number of clusters. First, we validate the accuracy of our algorithm on synthetic datasets generated from benchmark time series models. Second, we show that dipm-SC can uncover meaningful clusters of popularity behaviors in a real-world Twitter dataset. By clustering the multidimensional time-series of the popularity of contents coupled with other domain-specific dimensions, we uncover two main patterns of popularity: bursty and steady temporal behaviors. Moreover, we find that the way popularity is gained over time has no significant impact on the final cumulative popularity.
Community Detection in Political Twitter Networks using Nonnegative Matrix Factorization Methods
Aug 05, 2016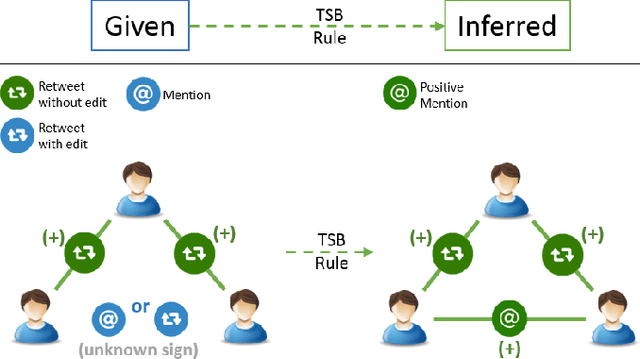
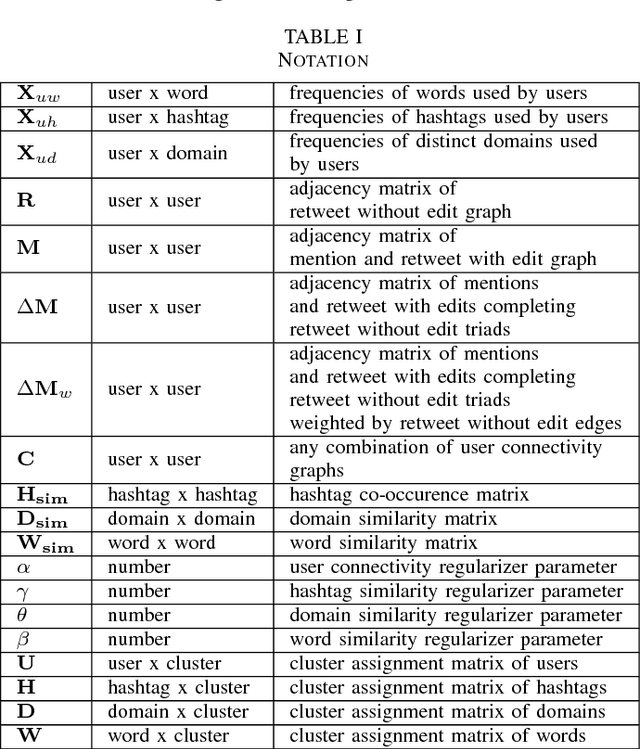
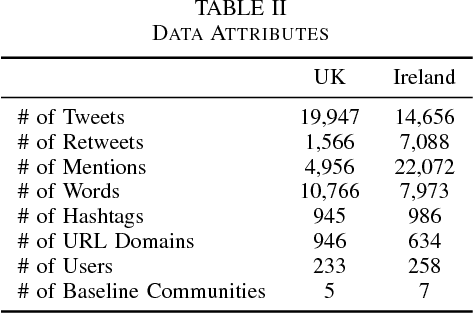

Community detection is a fundamental task in social network analysis. In this paper, first we develop an endorsement filtered user connectivity network by utilizing Heider's structural balance theory and certain Twitter triad patterns. Next, we develop three Nonnegative Matrix Factorization frameworks to investigate the contributions of different types of user connectivity and content information in community detection. We show that user content and endorsement filtered connectivity information are complementary to each other in clustering politically motivated users into pure political communities. Word usage is the strongest indicator of users' political orientation among all content categories. Incorporating user-word matrix and word similarity regularizer provides the missing link in connectivity only methods which suffer from detection of artificially large number of clusters for Twitter networks.