 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeSHFS: Neighborhood Search with Heuristic-based Feature Selection for Click-Through Rate Prediction
Sep 13, 2024Click-through-rate (CTR) prediction plays an important role in online advertising and ad recommender systems. In the past decade, maximizing CTR has been the main focus of model development and solution creation. Therefore, researchers and practitioners have proposed various models and solutions to enhance the effectiveness of CTR prediction. Most of the existing literature focuses on capturing either implicit or explicit feature interactions. Although implicit interactions are successfully captured in some studies, explicit interactions present a challenge for achieving high CTR by extracting both low-order and high-order feature interactions. Unnecessary and irrelevant features may cause high computational time and low prediction performance. Furthermore, certain features may perform well with specific predictive models while underperforming with others. Also, feature distribution may fluctuate due to traffic variations. Most importantly, in live production environments, resources are limited, and the time for inference is just as crucial as training time. Because of all these reasons, feature selection is one of the most important factors in enhancing CTR prediction model performance. Simple filter-based feature selection algorithms do not perform well and they are not sufficient. An effective and efficient feature selection algorithm is needed to consistently filter the most useful features during live CTR prediction process. In this paper, we propose a heuristic algorithm named Neighborhood Search with Heuristic-based Feature Selection (NeSHFS) to enhance CTR prediction performance while reducing dimensionality and training time costs. We conduct comprehensive experiments on three public datasets to validate the efficiency and effectiveness of our proposed solution.
memeBot: Towards Automatic Image Meme Generation
Apr 30, 2020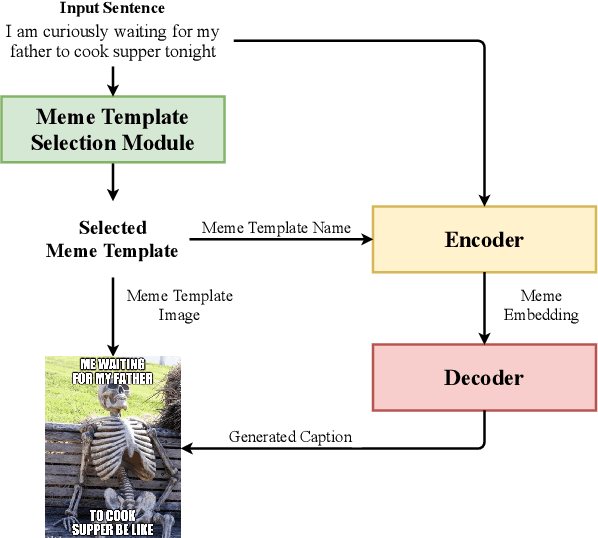



Image memes have become a widespread tool used by people for interacting and exchanging ideas over social media, blogs, and open messengers. This work proposes to treat automatic image meme generation as a translation process, and further present an end to end neural and probabilistic approach to generate an image-based meme for any given sentence using an encoder-decoder architecture. For a given input sentence, an image meme is generated by combining a meme template image and a text caption where the meme template image is selected from a set of popular candidates using a selection module, and the meme caption is generated by an encoder-decoder model. An encoder is used to map the selected meme template and the input sentence into a meme embedding and a decoder is used to decode the meme caption from the meme embedding. The generated natural language meme caption is conditioned on the input sentence and the selected meme template. The model learns the dependencies between the meme captions and the meme template images and generates new memes using the learned dependencies. The quality of the generated captions and the generated memes is evaluated through both automated and human evaluation. An experiment is designed to score how well the generated memes can represent the tweets from Twitter conversations. Experiments on Twitter data show the efficacy of the model in generating memes for sentences in online social interaction.
Graph Attention Auto-Encoders
May 26, 2019
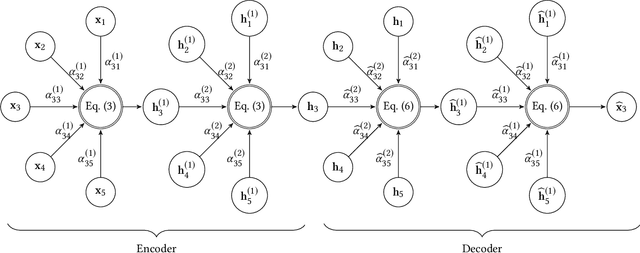


Auto-encoders have emerged as a successful framework for unsupervised learning. However, conventional auto-encoders are incapable of utilizing explicit relations in structured data. To take advantage of relations in graph-structured data, several graph auto-encoders have recently been proposed, but they neglect to reconstruct either the graph structure or node attributes. In this paper, we present the graph attention auto-encoder (GATE), a neural network architecture for unsupervised representation learning on graph-structured data. Our architecture is able to reconstruct graph-structured inputs, including both node attributes and the graph structure, through stacked encoder/decoder layers equipped with self-attention mechanisms. In the encoder, by considering node attributes as initial node representations, each layer generates new representations of nodes by attending over their neighbors' representations. In the decoder, we attempt to reverse the encoding process to reconstruct node attributes. Moreover, node representations are regularized to reconstruct the graph structure. Our proposed architecture does not need to know the graph structure upfront, and thus it can be applied to inductive learning. Our experiments demonstrate competitive performance on several node classification benchmark datasets for transductive and inductive tasks, even exceeding the performance of supervised learning baselines in most cases.
Leveraging Uncertainty in Deep Learning for Selective Classification
May 23, 2019
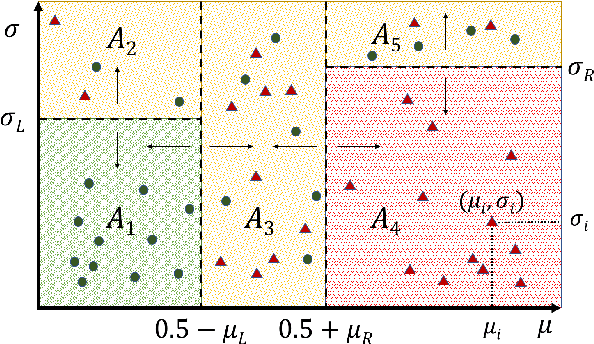
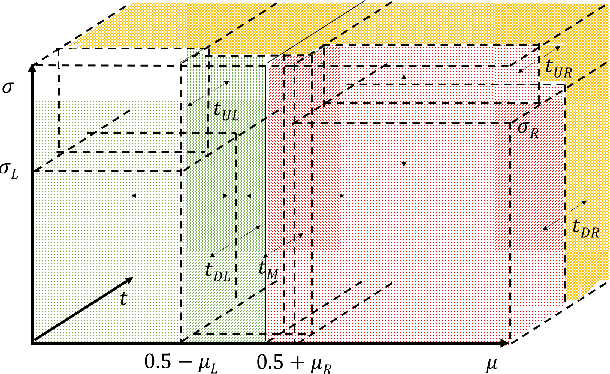
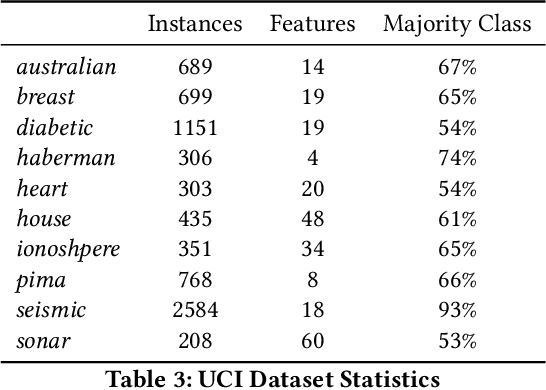
The wide and rapid adoption of deep learning by practitioners brought unintended consequences in many situations such as in the infamous case of Google Photos' racist image recognition algorithm; thus, necessitated the utilization of the quantified uncertainty for each prediction. There have been recent efforts towards quantifying uncertainty in conventional deep learning methods (e.g., dropout as Bayesian approximation); however, their optimal use in decision making is often overlooked and understudied. In this study, we propose a mixed-integer programming framework for classification with reject option (also known as selective classification), that investigates and combines model uncertainty and predictive mean to identify optimal classification and rejection regions. Our results indicate superior performance of our framework both in non-rejected accuracy and rejection quality on several publicly available datasets. Moreover, we extend our framework to cost-sensitive settings and show that our approach outperforms industry standard methods significantly for online fraud management in real-world settings.
Community Detection in Political Twitter Networks using Nonnegative Matrix Factorization Methods
Aug 05, 2016
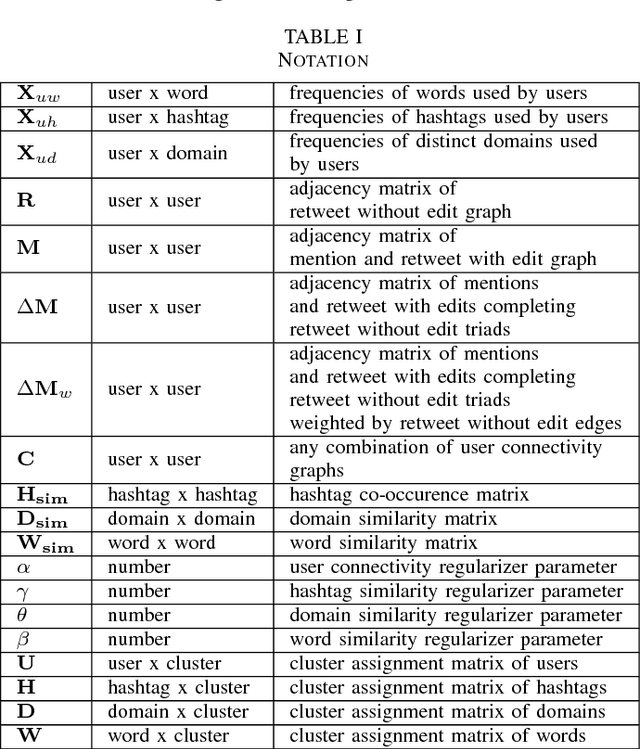
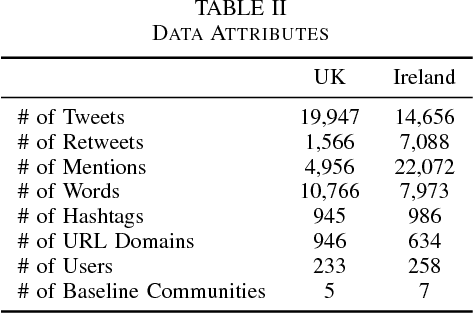

Community detection is a fundamental task in social network analysis. In this paper, first we develop an endorsement filtered user connectivity network by utilizing Heider's structural balance theory and certain Twitter triad patterns. Next, we develop three Nonnegative Matrix Factorization frameworks to investigate the contributions of different types of user connectivity and content information in community detection. We show that user content and endorsement filtered connectivity information are complementary to each other in clustering politically motivated users into pure political communities. Word usage is the strongest indicator of users' political orientation among all content categories. Incorporating user-word matrix and word similarity regularizer provides the missing link in connectivity only methods which suffer from detection of artificially large number of clusters for Twitter networks.
Orthogonal Rank-One Matrix Pursuit for Low Rank Matrix Completion
Apr 16, 2014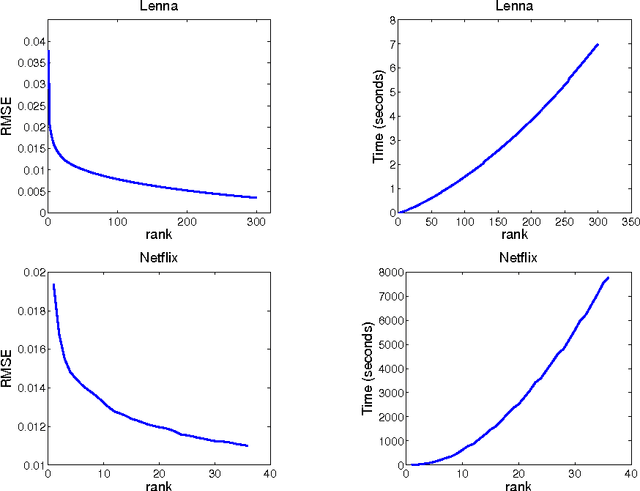
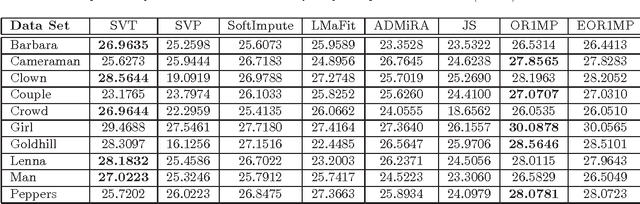
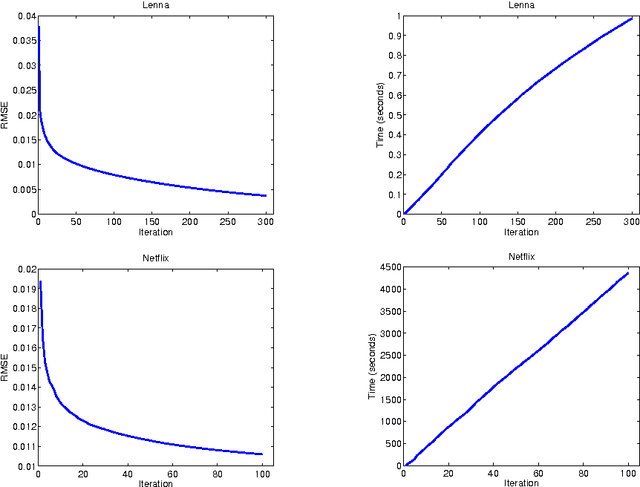
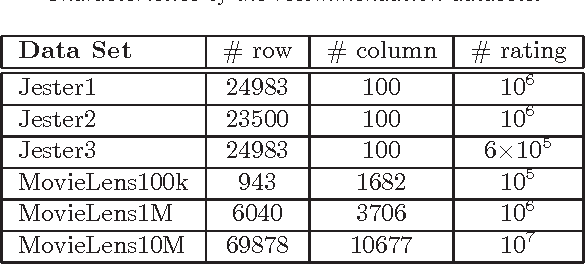
In this paper, we propose an efficient and scalable low rank matrix completion algorithm. The key idea is to extend orthogonal matching pursuit method from the vector case to the matrix case. We further propose an economic version of our algorithm by introducing a novel weight updating rule to reduce the time and storage complexity. Both versions are computationally inexpensive for each matrix pursuit iteration, and find satisfactory results in a few iterations. Another advantage of our proposed algorithm is that it has only one tunable parameter, which is the rank. It is easy to understand and to use by the user. This becomes especially important in large-scale learning problems. In addition, we rigorously show that both versions achieve a linear convergence rate, which is significantly better than the previous known results. We also empirically compare the proposed algorithms with several state-of-the-art matrix completion algorithms on many real-world datasets, including the large-scale recommendation dataset Netflix as well as the MovieLens datasets. Numerical results show that our proposed algorithm is more efficient than competing algorithms while achieving similar or better prediction performance.