 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow to High Dimensional Modality Hallucination using Aggregated Fields of View
Jul 13, 2020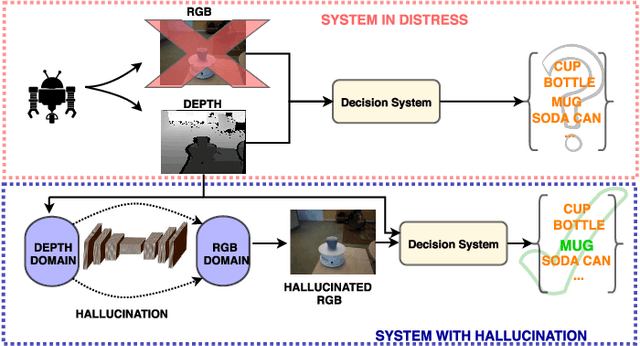



Real-world robotics systems deal with data from a multitude of modalities, especially for tasks such as navigation and recognition. The performance of those systems can drastically degrade when one or more modalities become inaccessible, due to factors such as sensors' malfunctions or adverse environments. Here, we argue modality hallucination as one effective way to ensure consistent modality availability and thereby reduce unfavorable consequences. While hallucinating data from a modality with richer information, e.g., RGB to depth, has been researched extensively, we investigate the more challenging low-to-high modality hallucination with interesting use cases in robotics and autonomous systems. We present a novel hallucination architecture that aggregates information from multiple fields of view of the local neighborhood to recover the lost information from the extant modality. The process is implemented by capturing a non-linear mapping between the data modalities and the learned mapping is used to aid the extant modality to mitigate the risk posed to the system in the adverse scenarios which involve modality loss. We also conduct extensive classification and segmentation experiments on UWRGBD and NYUD datasets and demonstrate that hallucination allays the negative effects of the modality loss. Implementation and models: https://github.com/kausic94/Hallucination
memeBot: Towards Automatic Image Meme Generation
Apr 30, 2020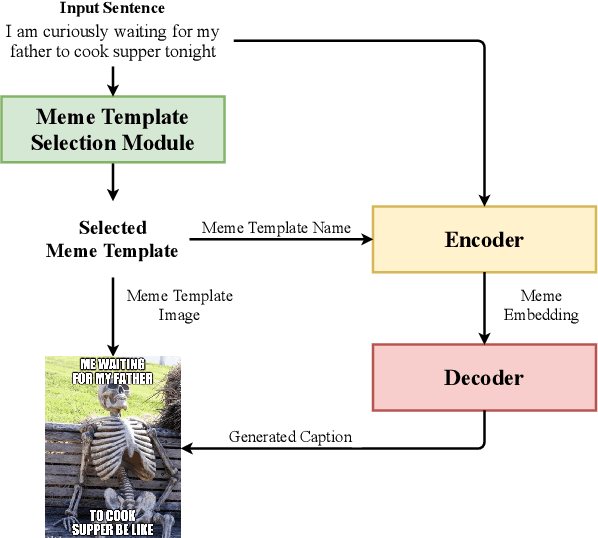



Image memes have become a widespread tool used by people for interacting and exchanging ideas over social media, blogs, and open messengers. This work proposes to treat automatic image meme generation as a translation process, and further present an end to end neural and probabilistic approach to generate an image-based meme for any given sentence using an encoder-decoder architecture. For a given input sentence, an image meme is generated by combining a meme template image and a text caption where the meme template image is selected from a set of popular candidates using a selection module, and the meme caption is generated by an encoder-decoder model. An encoder is used to map the selected meme template and the input sentence into a meme embedding and a decoder is used to decode the meme caption from the meme embedding. The generated natural language meme caption is conditioned on the input sentence and the selected meme template. The model learns the dependencies between the meme captions and the meme template images and generates new memes using the learned dependencies. The quality of the generated captions and the generated memes is evaluated through both automated and human evaluation. An experiment is designed to score how well the generated memes can represent the tweets from Twitter conversations. Experiments on Twitter data show the efficacy of the model in generating memes for sentences in online social interaction.