 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Cross-Examination Technique (ICE-T): Using highly informative features to boost LLM performance
May 08, 2024



In this paper, we introduce the Interpretable Cross-Examination Technique (ICE-T), a novel approach that leverages structured multi-prompt techniques with Large Language Models (LLMs) to improve classification performance over zero-shot and few-shot methods. In domains where interpretability is crucial, such as medicine and law, standard models often fall short due to their "black-box" nature. ICE-T addresses these limitations by using a series of generated prompts that allow an LLM to approach the problem from multiple directions. The responses from the LLM are then converted into numerical feature vectors and processed by a traditional classifier. This method not only maintains high interpretability but also allows for smaller, less capable models to achieve or exceed the performance of larger, more advanced models under zero-shot conditions. We demonstrate the effectiveness of ICE-T across a diverse set of data sources, including medical records and legal documents, consistently surpassing the zero-shot baseline in terms of classification metrics such as F1 scores. Our results indicate that ICE-T can be used for improving both the performance and transparency of AI applications in complex decision-making environments.
Quantifying How Hateful Communities Radicalize Online Users
Oct 02, 2022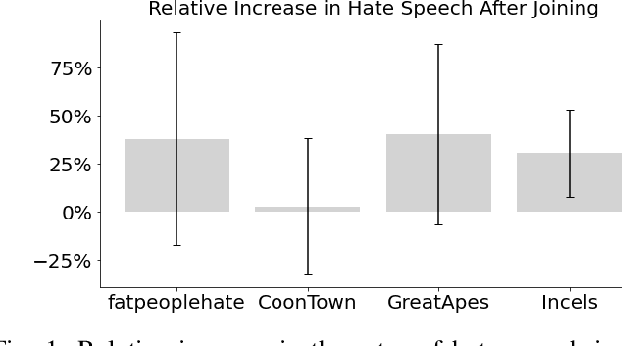
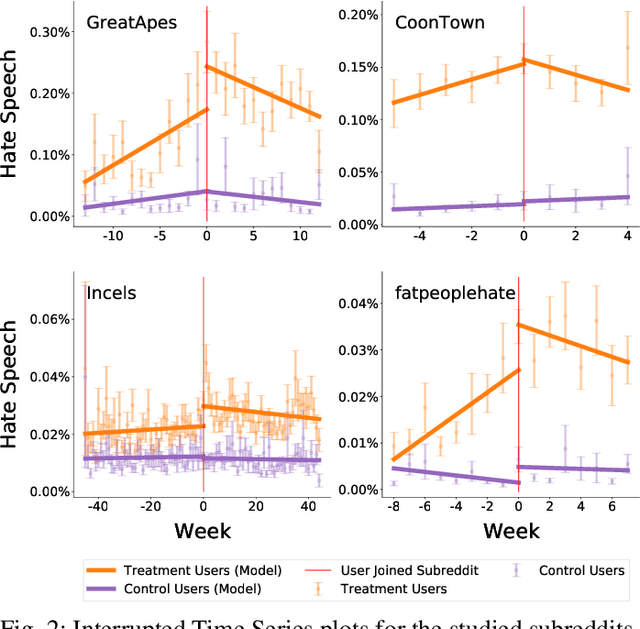
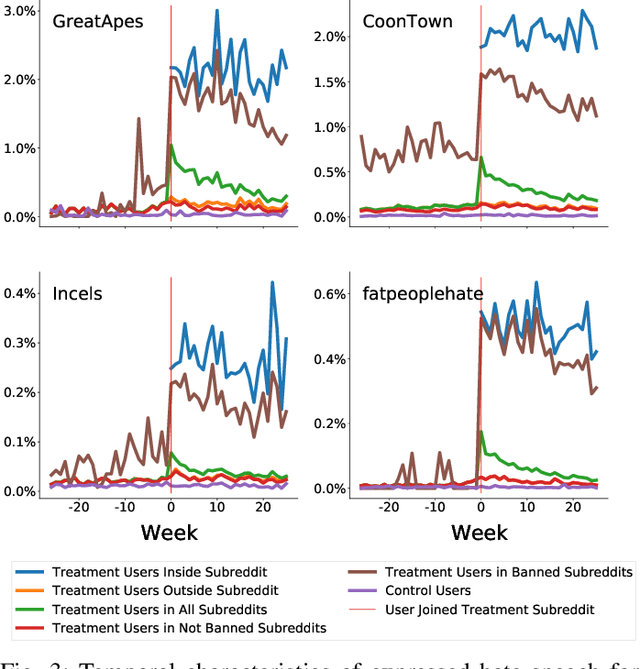
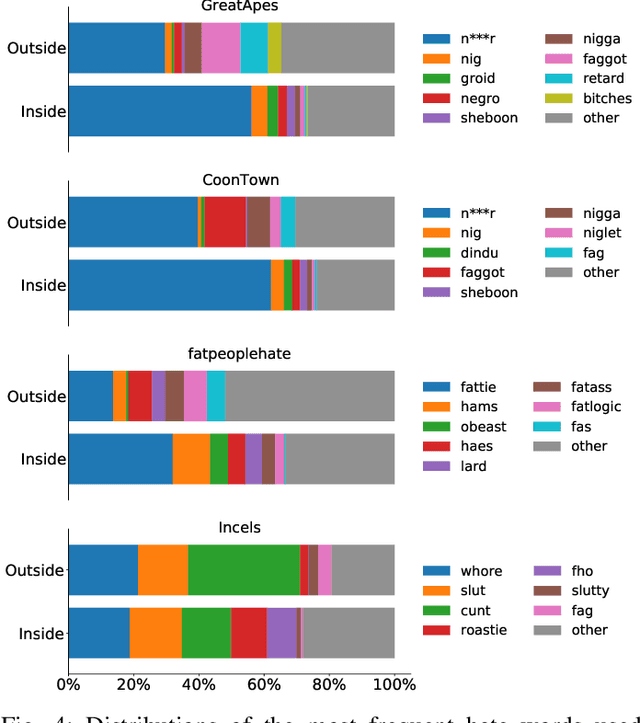
While online social media offers a way for ignored or stifled voices to be heard, it also allows users a platform to spread hateful speech. Such speech usually originates in fringe communities, yet it can spill over into mainstream channels. In this paper, we measure the impact of joining fringe hateful communities in terms of hate speech propagated to the rest of the social network. We leverage data from Reddit to assess the effect of joining one type of echo chamber: a digital community of like-minded users exhibiting hateful behavior. We measure members' usage of hate speech outside the studied community before and after they become active participants. Using Interrupted Time Series (ITS) analysis as a causal inference method, we gauge the spillover effect, in which hateful language from within a certain community can spread outside that community by using the level of out-of-community hate word usage as a proxy for learned hate. We investigate four different Reddit sub-communities (subreddits) covering three areas of hate speech: racism, misogyny and fat-shaming. In all three cases we find an increase in hate speech outside the originating community, implying that joining such community leads to a spread of hate speech throughout the platform. Moreover, users are found to pick up this new hateful speech for months after initially joining the community. We show that the harmful speech does not remain contained within the community. Our results provide new evidence of the harmful effects of echo chambers and the potential benefit of moderating them to reduce adoption of hateful speech.
Discovering patterns of online popularity from time series
Apr 10, 2019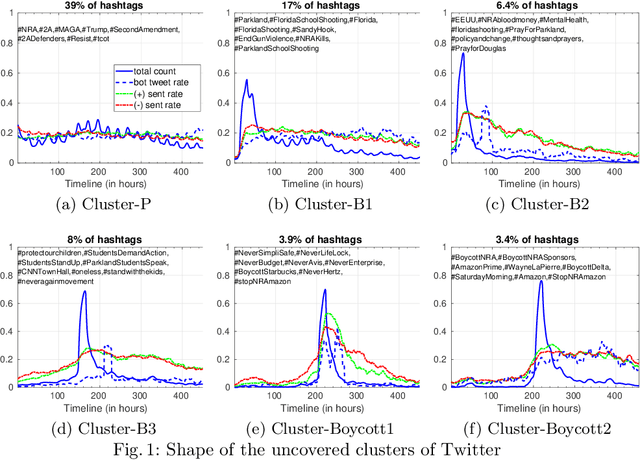
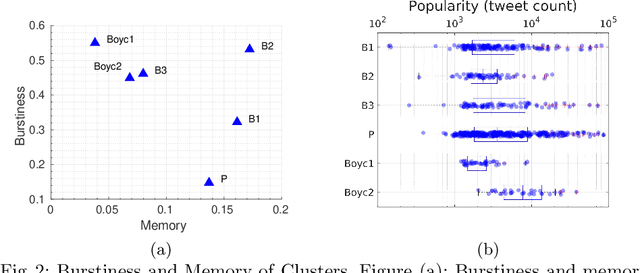
How is popularity gained online? Is being successful strictly related to rapidly becoming viral in an online platform or is it possible to acquire popularity in a steady and disciplined fashion? What are other temporal characteristics that can unveil the popularity of online content? To answer these questions, we leverage a multi-faceted temporal analysis of the evolution of popular online contents. Here, we present dipm-SC: a multi-dimensional shape-based time-series clustering algorithm with a heuristic to find the optimal number of clusters. First, we validate the accuracy of our algorithm on synthetic datasets generated from benchmark time series models. Second, we show that dipm-SC can uncover meaningful clusters of popularity behaviors in a real-world Twitter dataset. By clustering the multidimensional time-series of the popularity of contents coupled with other domain-specific dimensions, we uncover two main patterns of popularity: bursty and steady temporal behaviors. Moreover, we find that the way popularity is gained over time has no significant impact on the final cumulative popularity.