 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Reranking to Operationalize Nuanced Objectives in Recommender Systems
Jun 01, 2026Recommender systems have grown from content-organization tools into sophisticated systems that shape daily behavior. By controlling what we see, they shape what we perceive, raising concerns about filter bubbles, radicalization, polarization, and social inequality. Large language models (LLMs) enable more powerful personalization, intensifying these dynamics. Yet most recommenders are tuned for engagement or limited accuracy metrics, with little attention to broader social implications, e.g. how personalization reshapes exposure in socially consequential domains. We investigate whether LLM-assisted reranking, while improving personalization, inadvertently amplifies exposure to ideologically extreme or conspiratorial political content, a risk theorized but not empirically characterized in news recommendation. Using real news-consumption histories, we rerank YouTube's sidebar candidates through zero-shot, instruction-based prompting. We compare a baseline prompt with a constrained variant that preserves topical relevance and broadens ideological exposure while reducing conspiratorial or extreme content. Without constraints, reranking strengthened personalization but increased exposure to conspiratorial and extremist material for users whose histories contained such content. Lightweight prompt-level regularization reduced promotion of extreme content and increased ideological diversity, with modest relevance loss. Synthetic experiments suggest that LLMs rerank via statistical regularities in language rather than semantic understanding of ideology, clarifying why naive prompts amplify these patterns and why regularization can reshape them. Together, our results highlight the power of LLMs to operationalize contextual nuance in high-stakes recommendation, and the need to evaluate LLM-assisted personalization beyond accuracy and treat prompt design as a value-laden rather than neutral default.
The diminishing state of shared reality on US television news
Oct 29, 2023The potential for a large, diverse population to coexist peacefully is thought to depend on the existence of a ``shared reality:'' a public sphere in which participants are exposed to similar facts about similar topics. A generation ago, broadcast television news was widely considered to serve this function; however, since the rise of cable news in the 1990s, critics and scholars have worried that the corresponding fragmentation and segregation of audiences along partisan lines has caused this shared reality to be lost. Here we examine this concern using a unique combination of data sets tracking the production (since 2012) and consumption (since 2016) of television news content on the three largest cable and broadcast networks respectively. With regard to production, we find strong evidence for the ``loss of shared reality hypothesis:'' while broadcast continues to cover similar topics with similar language, cable news networks have become increasingly distinct, both from broadcast news and each other, diverging both in terms of content and language. With regard to consumption, we find more mixed evidence: while broadcast news has indeed declined in popularity, it remains the dominant source of news for roughly 50\% more Americans than does cable; moreover, its decline, while somewhat attributable to cable, appears driven more by a shift away from news consumption altogether than a growth in cable consumption. We conclude that shared reality on US television news is indeed diminishing, but is more robust than previously thought and is declining for somewhat different reasons.
Learning Behavioral Representations from Wearable Sensors
Nov 16, 2019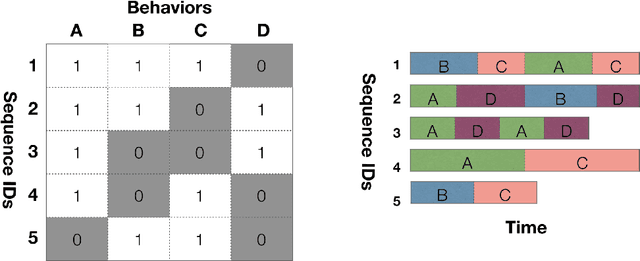

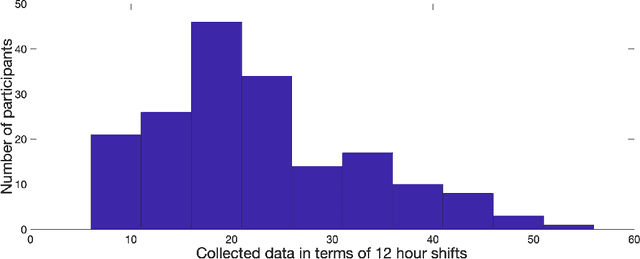

The ubiquity of mobile devices and wearable sensors offers unprecedented opportunities for continuous collection of multimodal physiological data. Such data enables temporal characterization of an individual's behaviors, which can provide unique insights into her physical and psychological health. Understanding the relation between different behaviors/activities and personality traits such as stress or work performance can help build strategies to improve the work environment. Especially in workplaces like hospitals where many employees are overworked, having such policies improves the quality of patient care by prioritizing mental and physical health of their caregivers. One challenge in analyzing physiological data is extracting the underlying behavioral states from the temporal sensor signals and interpreting them. Here, we use a non-parametric Bayesian approach, to model multivariate sensor data from multiple people and discover dynamic behaviors they share. We apply this method to data collected from sensors worn by a population of workers in a large urban hospital, capturing their physiological signals, such as breathing and heart rate, and activity patterns. We show that the learned states capture behavioral differences within the population that can help cluster participants into meaningful groups and better predict their cognitive and affective states. This method offers a practical way to learn compact behavioral representations from dynamic multivariate sensor signals and provide insights into the data.
Stacking Models for Nearly Optimal Link Prediction in Complex Networks
Sep 17, 2019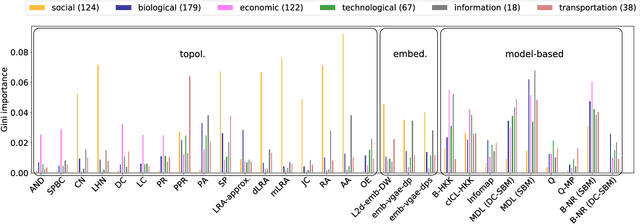
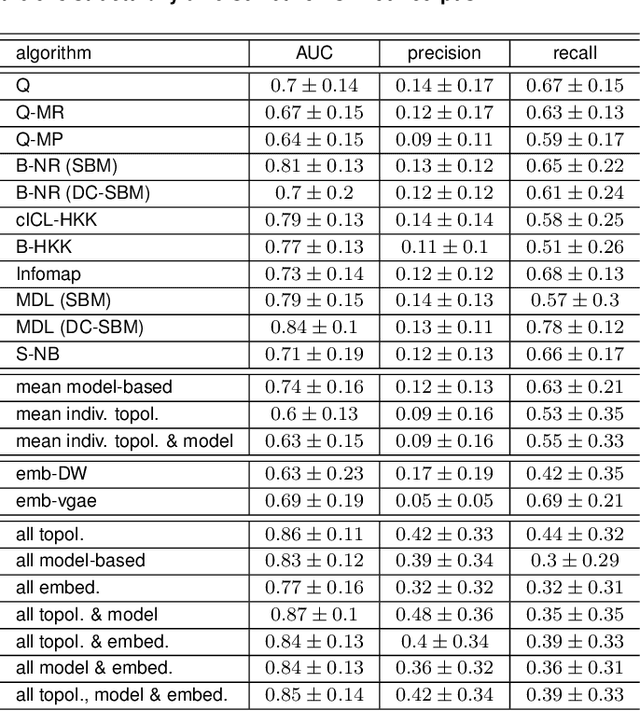
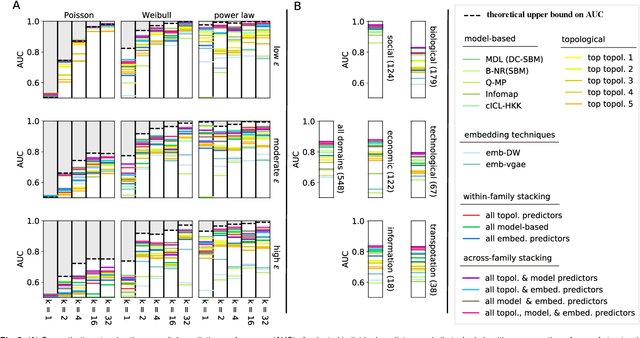
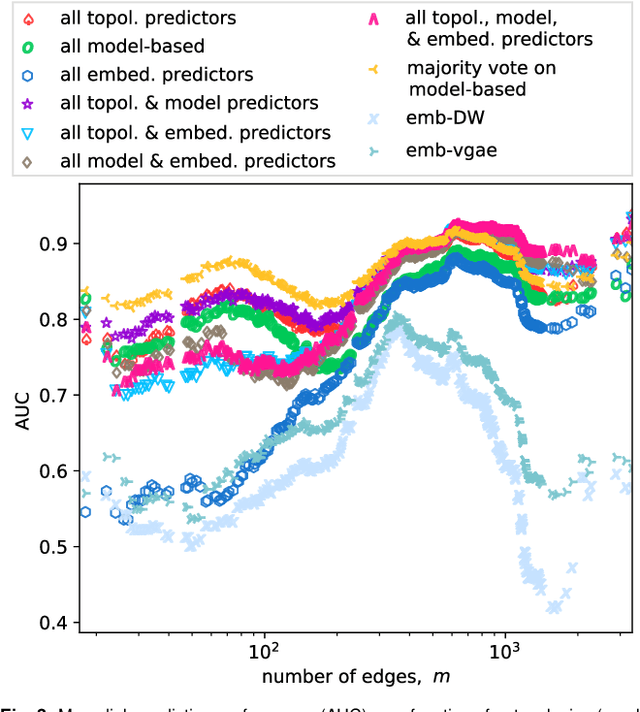
Most real-world networks are incompletely observed. Algorithms that can accurately predict which links are missing can dramatically speedup the collection of network data and improve the validity of network models. Many algorithms now exist for predicting missing links, given a partially observed network, but it has remained unknown whether a single best predictor exists, how link predictability varies across methods and networks from different domains, and how close to optimality current methods are. We answer these questions by systematically evaluating 203 individual link predictor algorithms, representing three popular families of methods, applied to a large corpus of 548 structurally diverse networks from six scientific domains. We first show that individual algorithms exhibit a broad diversity of prediction errors, such that no one predictor or family is best, or worst, across all realistic inputs. We then exploit this diversity via meta-learning to construct a series of "stacked" models that combine predictors into a single algorithm. Applied to a broad range of synthetic networks, for which we may analytically calculate optimal performance, these stacked models achieve optimal or nearly optimal levels of accuracy. Applied to real-world networks, stacked models are also superior, but their accuracy varies strongly by domain, suggesting that link prediction may be fundamentally easier in social networks than in biological or technological networks. These results indicate that the state-of-the-art for link prediction comes from combining individual algorithms, which achieves nearly optimal predictions. We close with a brief discussion of limitations and opportunities for further improvement of these results.
Discovering Hidden Structure in High Dimensional Human Behavioral Data via Tensor Factorization
May 21, 2019
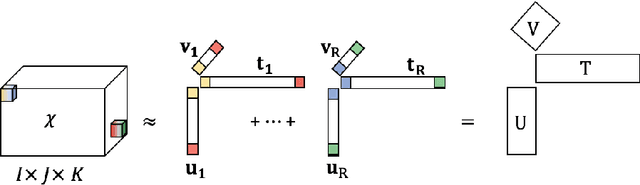
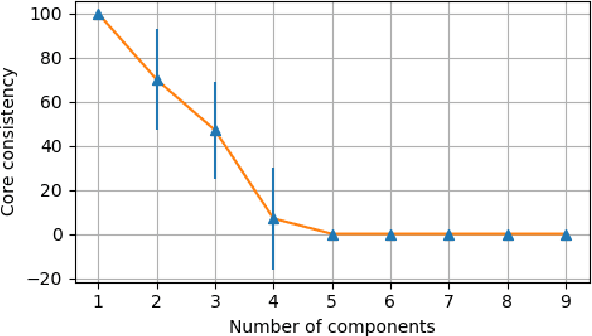
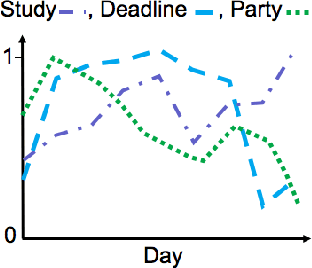
In recent years, the rapid growth in technology has increased the opportunity for longitudinal human behavioral studies. Rich multimodal data, from wearables like Fitbit, online social networks, mobile phones etc. can be collected in natural environments. Uncovering the underlying low-dimensional structure of noisy multi-way data in an unsupervised setting is a challenging problem. Tensor factorization has been successful in extracting the interconnected low-dimensional descriptions of multi-way data. In this paper, we apply non-negative tensor factorization on a real-word wearable sensor data, StudentLife, to find latent temporal factors and group of similar individuals. Meta data is available for the semester schedule, as well as the individuals' performance and personality. We demonstrate that non-negative tensor factorization can successfully discover clusters of individuals who exhibit higher academic performance, as well as those who frequently engage in leisure activities. The recovered latent temporal patterns associated with these groups are validated against ground truth data to demonstrate the accuracy of our framework.
* 2018 WSDM Heteronam Workshop
Tensor Embedding: A Supervised Framework for Human Behavioral Data Mining and Prediction
Aug 31, 2018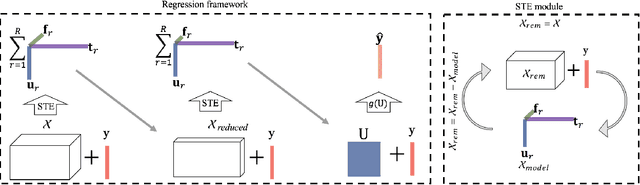

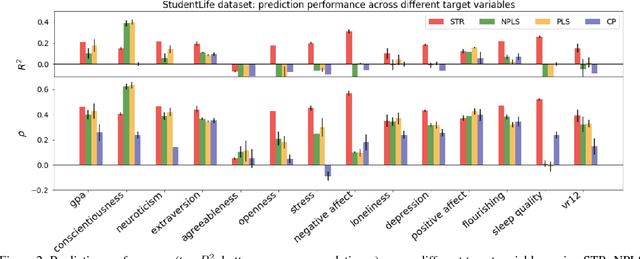
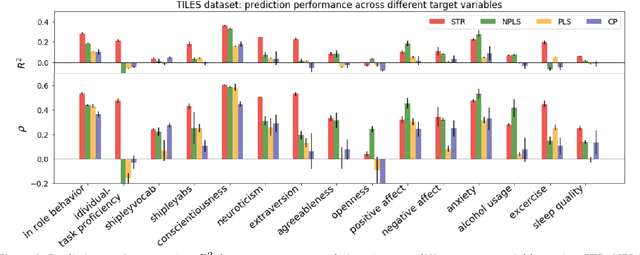
Today's densely instrumented world offers tremendous opportunities for continuous acquisition and analysis of multimodal sensor data providing temporal characterization of an individual's behaviors. Is it possible to efficiently couple such rich sensor data with predictive modeling techniques to provide contextual, and insightful assessments of individual performance and wellbeing? Prediction of different aspects of human behavior from these noisy, incomplete, and heterogeneous bio-behavioral temporal data is a challenging problem, beyond unsupervised discovery of latent structures. We propose a Supervised Tensor Embedding (STE) algorithm for high dimension multimodal data with join decomposition of input and target variable. Furthermore, we show that features selection will help to reduce the contamination in the prediction and increase the performance. The efficiently of the methods was tested via two different real world datasets.
Evaluating Overfit and Underfit in Models of Network Community Structure
Mar 01, 2018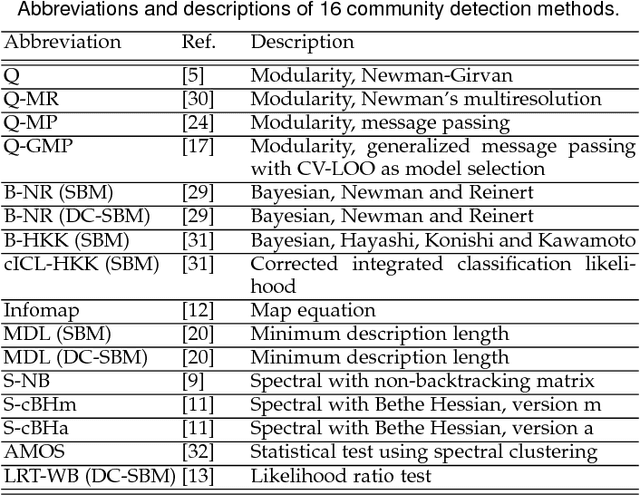
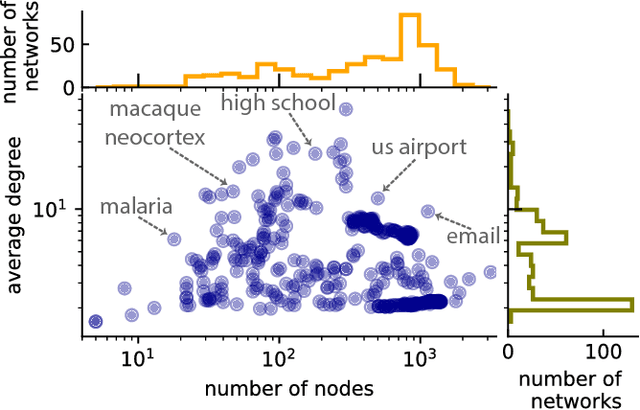
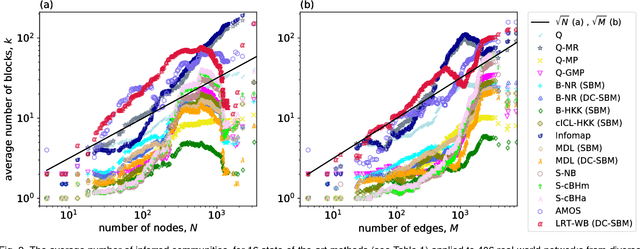
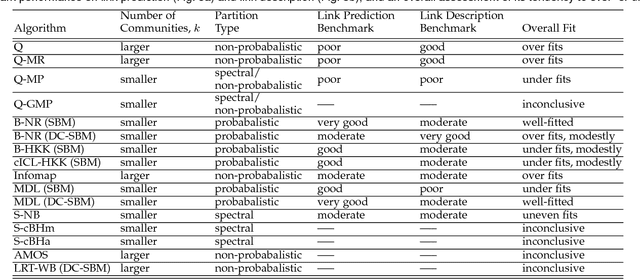
A common data mining task on networks is community detection, which seeks an unsupervised decomposition of a network into structural groups based on statistical regularities in the network's connectivity. Although many methods exist, the No Free Lunch theorem for community detection implies that each makes some kind of tradeoff, and no algorithm can be optimal on all inputs. Thus, different algorithms will over or underfit on different inputs, finding more, fewer, or just different communities than is optimal, and evaluation methods that use a metadata partition as a ground truth will produce misleading conclusions about general accuracy. Here, we present a broad evaluation of over and underfitting in community detection, comparing the behavior of 16 state-of-the-art community detection algorithms on a novel and structurally diverse corpus of 406 real-world networks. We find that (i) algorithms vary widely both in the number of communities they find and in their corresponding composition, given the same input, (ii) algorithms can be clustered into distinct high-level groups based on similarities of their outputs on real-world networks, and (iii) these differences induce wide variation in accuracy on link prediction and link description tasks. We introduce a new diagnostic for evaluating overfitting and underfitting in practice, and use it to roughly divide community detection methods into general and specialized learning algorithms. Across methods and inputs, Bayesian techniques based on the stochastic block model and a minimum description length approach to regularization represent the best general learning approach, but can be outperformed under specific circumstances. These results introduce both a theoretically principled approach to evaluate over and underfitting in models of network community structure and a realistic benchmark by which new methods may be evaluated and compared.