 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo not Mask Randomly: Effective Domain-adaptive Pre-training by Masking In-domain Keywords
Jul 14, 2023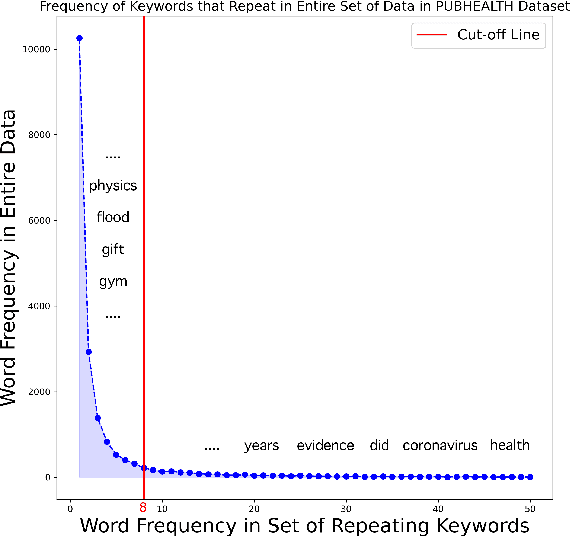
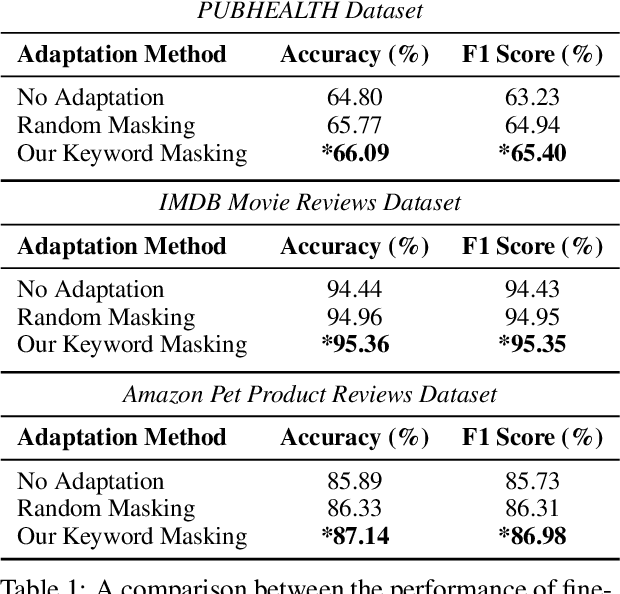
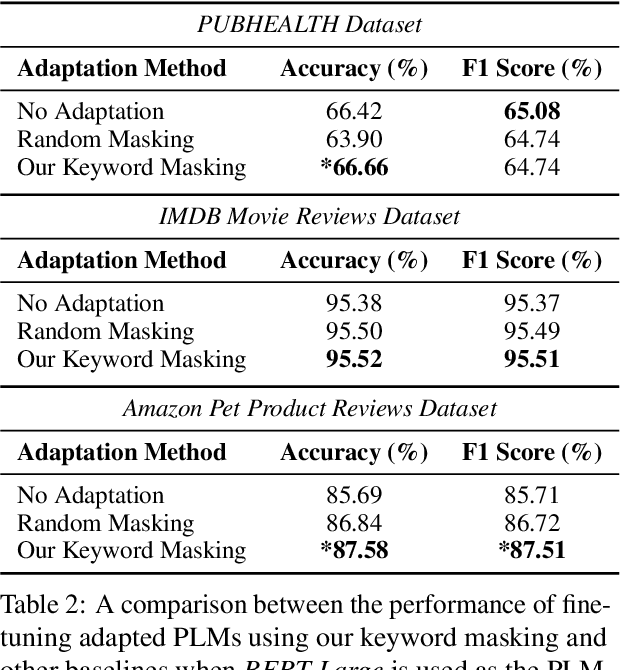
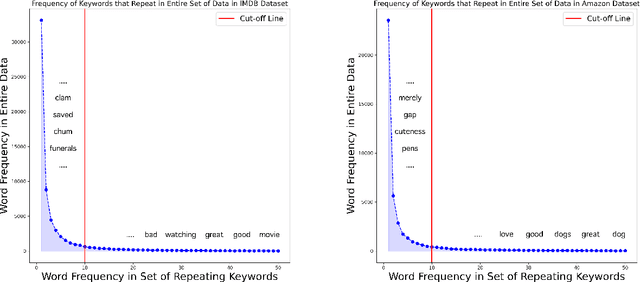
We propose a novel task-agnostic in-domain pre-training method that sits between generic pre-training and fine-tuning. Our approach selectively masks in-domain keywords, i.e., words that provide a compact representation of the target domain. We identify such keywords using KeyBERT (Grootendorst, 2020). We evaluate our approach using six different settings: three datasets combined with two distinct pre-trained language models (PLMs). Our results reveal that the fine-tuned PLMs adapted using our in-domain pre-training strategy outperform PLMs that used in-domain pre-training with random masking as well as those that followed the common pre-train-then-fine-tune paradigm. Further, the overhead of identifying in-domain keywords is reasonable, e.g., 7-15% of the pre-training time (for two epochs) for BERT Large (Devlin et al., 2019).
A Compact Pretraining Approach for Neural Language Models
Aug 29, 2022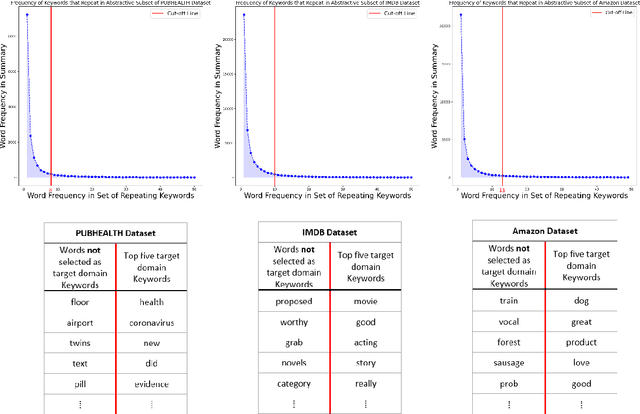
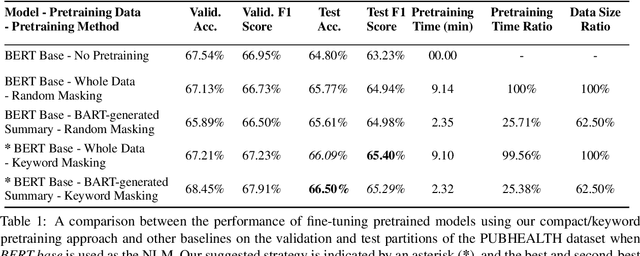
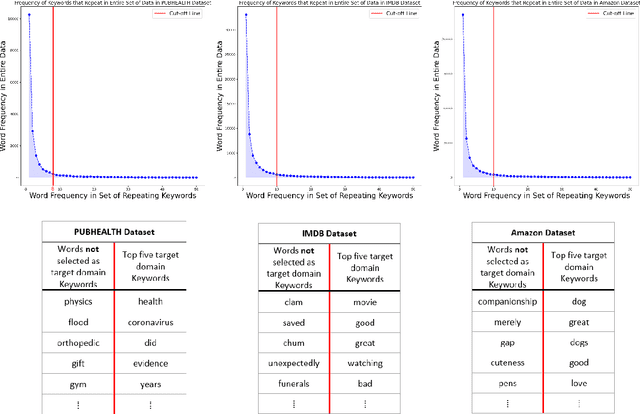

Domain adaptation for large neural language models (NLMs) is coupled with massive amounts of unstructured data in the pretraining phase. In this study, however, we show that pretrained NLMs learn in-domain information more effectively and faster from a compact subset of the data that focuses on the key information in the domain. We construct these compact subsets from the unstructured data using a combination of abstractive summaries and extractive keywords. In particular, we rely on BART to generate abstractive summaries, and KeyBERT to extract keywords from these summaries (or the original unstructured text directly). We evaluate our approach using six different settings: three datasets combined with two distinct NLMs. Our results reveal that the task-specific classifiers trained on top of NLMs pretrained using our method outperform methods based on traditional pretraining, i.e., random masking on the entire data, as well as methods without pretraining. Further, we show that our strategy reduces pretraining time by up to five times compared to vanilla pretraining. The code for all of our experiments is publicly available at https://github.com/shahriargolchin/compact-pretraining.
Pattern Discovery in Time Series with Byte Pair Encoding
May 30, 2021


The growing popularity of wearable sensors has generated large quantities of temporal physiological and activity data. Ability to analyze this data offers new opportunities for real-time health monitoring and forecasting. However, temporal physiological data presents many analytic challenges: the data is noisy, contains many missing values, and each series has a different length. Most methods proposed for time series analysis and classification do not handle datasets with these characteristics nor do they offer interpretability and explainability, a critical requirement in the health domain. We propose an unsupervised method for learning representations of time series based on common patterns identified within them. The patterns are, interpretable, variable in length, and extracted using Byte Pair Encoding compression technique. In this way the method can capture both long-term and short-term dependencies present in the data. We show that this method applies to both univariate and multivariate time series and beats state-of-the-art approaches on a real world dataset collected from wearable sensors.
Challenges in Forecasting Malicious Events from Incomplete Data
Apr 06, 2020



The ability to accurately predict cyber-attacks would enable organizations to mitigate their growing threat and avert the financial losses and disruptions they cause. But how predictable are cyber-attacks? Researchers have attempted to combine external data -- ranging from vulnerability disclosures to discussions on Twitter and the darkweb -- with machine learning algorithms to learn indicators of impending cyber-attacks. However, successful cyber-attacks represent a tiny fraction of all attempted attacks: the vast majority are stopped, or filtered by the security appliances deployed at the target. As we show in this paper, the process of filtering reduces the predictability of cyber-attacks. The small number of attacks that do penetrate the target's defenses follow a different generative process compared to the whole data which is much harder to learn for predictive models. This could be caused by the fact that the resulting time series also depends on the filtering process in addition to all the different factors that the original time series depended on. We empirically quantify the loss of predictability due to filtering using real-world data from two organizations. Our work identifies the limits to forecasting cyber-attacks from highly filtered data.
Learning Behavioral Representations from Wearable Sensors
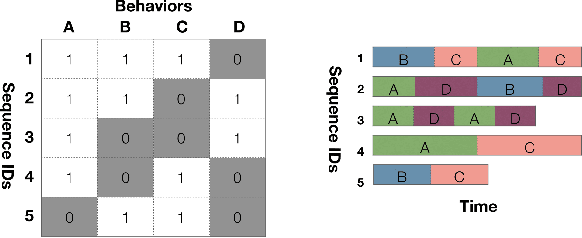
Nov 16, 2019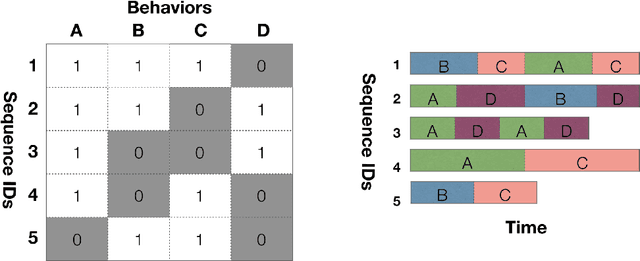

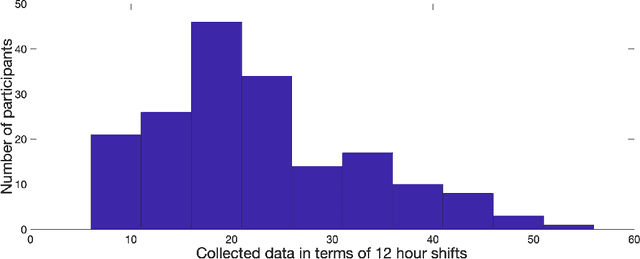

The ubiquity of mobile devices and wearable sensors offers unprecedented opportunities for continuous collection of multimodal physiological data. Such data enables temporal characterization of an individual's behaviors, which can provide unique insights into her physical and psychological health. Understanding the relation between different behaviors/activities and personality traits such as stress or work performance can help build strategies to improve the work environment. Especially in workplaces like hospitals where many employees are overworked, having such policies improves the quality of patient care by prioritizing mental and physical health of their caregivers. One challenge in analyzing physiological data is extracting the underlying behavioral states from the temporal sensor signals and interpreting them. Here, we use a non-parametric Bayesian approach, to model multivariate sensor data from multiple people and discover dynamic behaviors they share. We apply this method to data collected from sensors worn by a population of workers in a large urban hospital, capturing their physiological signals, such as breathing and heart rate, and activity patterns. We show that the learned states capture behavioral differences within the population that can help cluster participants into meaningful groups and better predict their cognitive and affective states. This method offers a practical way to learn compact behavioral representations from dynamic multivariate sensor signals and provide insights into the data.
Characterizing Activity on the Deep and Dark Web
Mar 01, 2019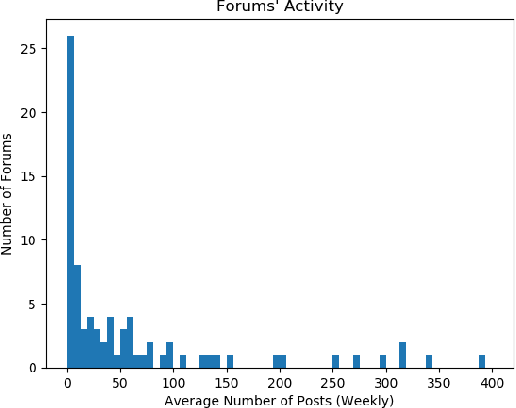


The deep and darkweb (d2web) refers to limited access web sites that require registration, authentication, or more complex encryption protocols to access them. These web sites serve as hubs for a variety of illicit activities: to trade drugs, stolen user credentials, hacking tools, and to coordinate attacks and manipulation campaigns. Despite its importance to cyber crime, the d2web has not been systematically investigated. In this paper, we study a large corpus of messages posted to 80 d2web forums over a period of more than a year. We identify topics of discussion using LDA and use a non-parametric HMM to model the evolution of topics across forums. Then, we examine the dynamic patterns of discussion and identify forums with similar patterns. We show that our approach surfaces hidden similarities across different forums and can help identify anomalous events in this rich, heterogeneous data.
Discovering Signals from Web Sources to Predict Cyber Attacks
Jun 08, 2018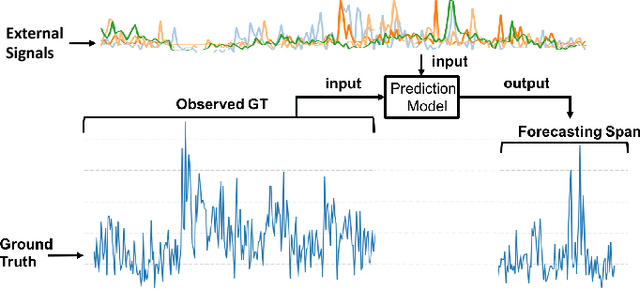
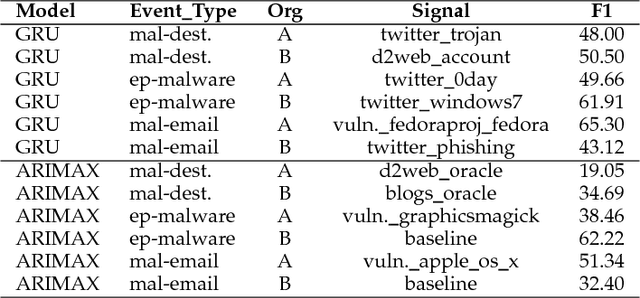
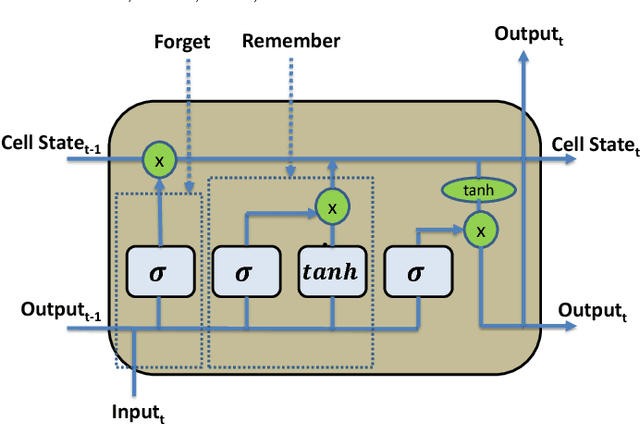
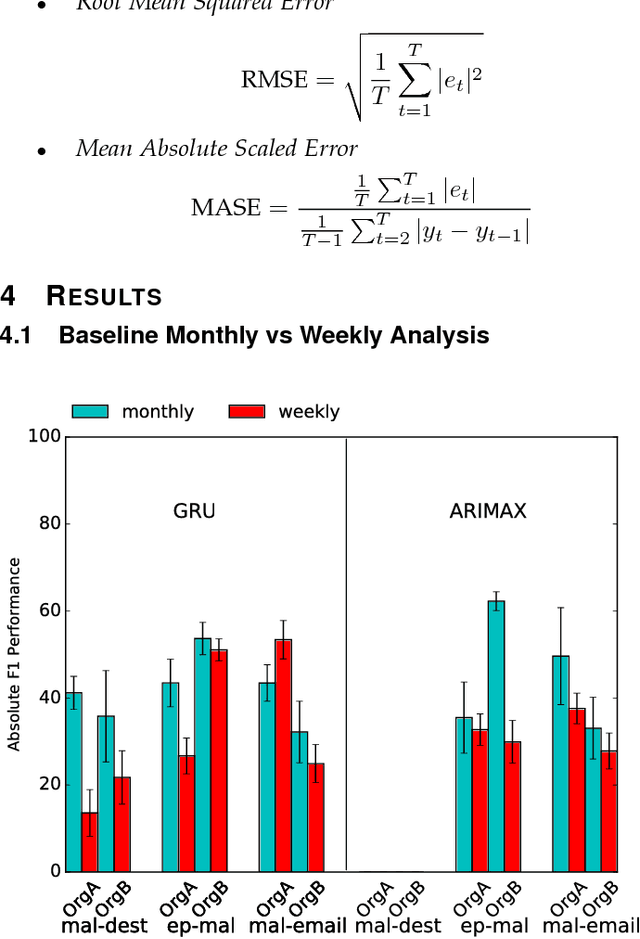
Cyber attacks are growing in frequency and severity. Over the past year alone we have witnessed massive data breaches that stole personal information of millions of people and wide-scale ransomware attacks that paralyzed critical infrastructure of several countries. Combating the rising cyber threat calls for a multi-pronged strategy, which includes predicting when these attacks will occur. The intuition driving our approach is this: during the planning and preparation stages, hackers leave digital traces of their activities on both the surface web and dark web in the form of discussions on platforms like hacker forums, social media, blogs and the like. These data provide predictive signals that allow anticipating cyber attacks. In this paper, we describe machine learning techniques based on deep neural networks and autoregressive time series models that leverage external signals from publicly available Web sources to forecast cyber attacks. Performance of our framework across ground truth data over real-world forecasting tasks shows that our methods yield a significant lift or increase of F1 for the top signals on predicted cyber attacks. Our results suggest that, when deployed, our system will be able to provide an effective line of defense against various types of targeted cyber attacks.